
“最近一份据说是埃森哲的大数据分析PPT莫名被朋友分享,真实与否暂不考究,但是就PPT内容来说,对于数据分析还是很翔实的,有很多实用的大数据分析方法”
0、简述
PPT的内容非常多,具体目录:
1、概述
2、数据分析框架
3、数据分析方法
4、数据分析支撑工具
先给大家说一下,我这篇文章写什么:
1、总结 「埃森哲」大数据分析PPT内容;
2、里面有些内容可能比较久远,我会补充下我所知道的现在比较常用的方法;
3、原PPT的分享内容文字叙述总结居多,我会根据我们日常的工作,编辑一些相关案例,帮助理解;
4、针对 「埃森哲」公司分享的这个PPT里面的具体方法,我会给出相应地python实现方式,应用起来更方便。
我不确定我是否有公开该PPT的权限,所以就不把PPT放在文章里,如果大家有需要,直接后台留言/回复「数据分析」,我再告诉大家获取方法。
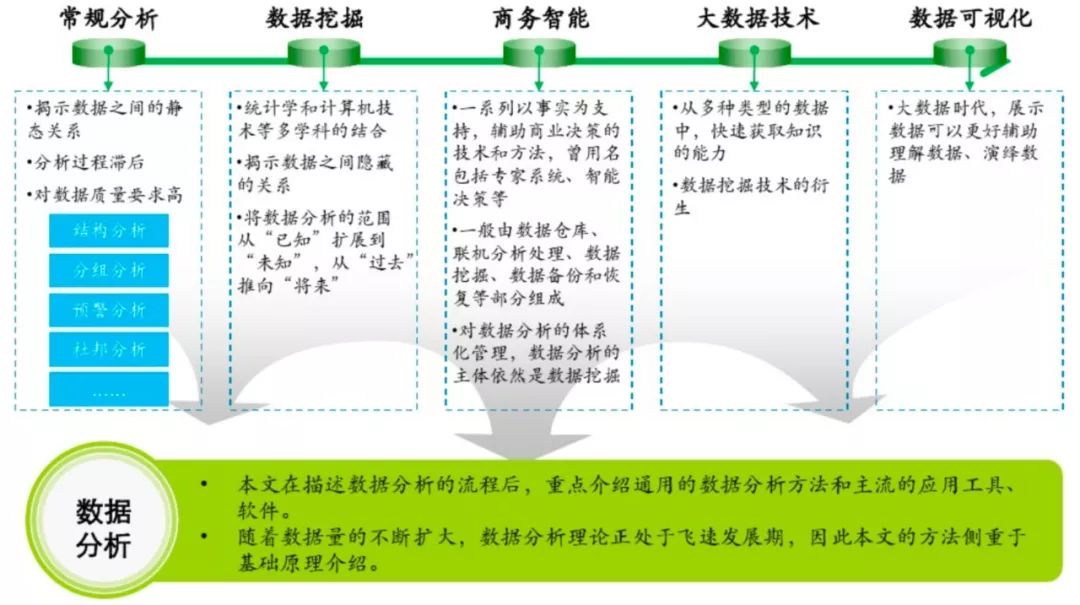
1、概述
数据分析到底是一个什么样的工作,由于她的涵盖范围非常广,平时我们经常遇到不同专业的同学成为一名数据分析师,可能是学计算机的,或者是金融工程,也可能是学数学或者统计,数据分析作为一个多学科交叉工种所包含的学科知识也是五花八门,在我理解,数据分析师入门需要掌握4种能力:业务理解能力、数学/统计知识、数据库操作能力,编程能力。
业务理解能力对于数据分析师来说是至关重要的,业务经验可以帮助我们在分析具体问题前明确需求,在分析中可以判断方法是否合理以及分析后的指导应用。
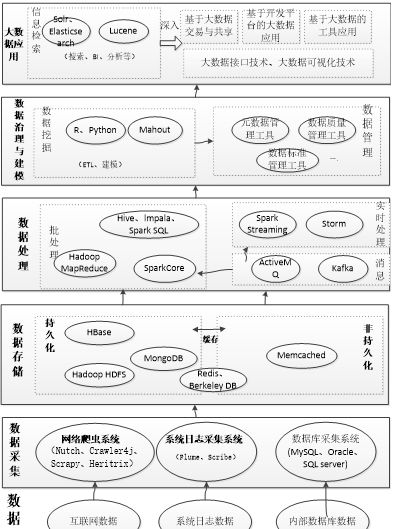
“随着计算机科学的发展,数据挖掘埃森哲 大数据 场景,机器学习,深度学习,大数据等概念越来越热,数据分析的手段和方法也越来越丰富”
这也恰恰意味着数据分析不拘一格,做数据分析的工作同样可以将机器学习甚至深度学习的相关算法加以应用在工作中。
(图片来自原PPT)
2、数据分析框架
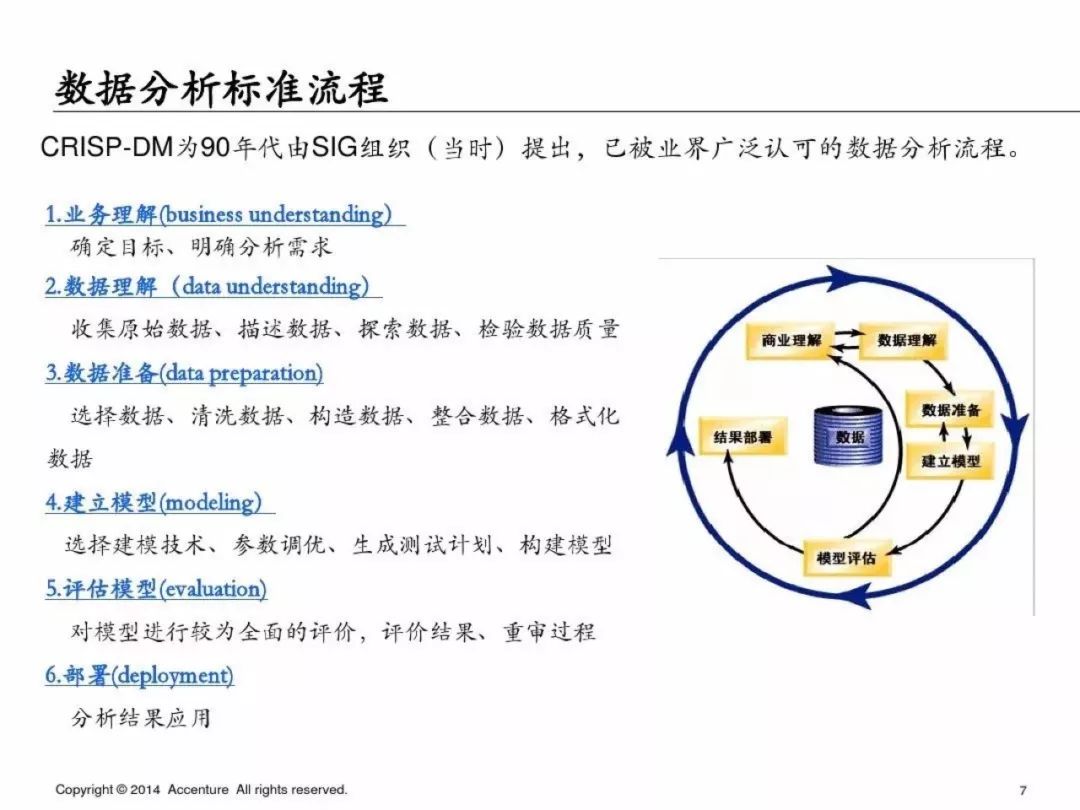
「埃森哲」的数据分析框架基本完全遵循CRISP-DM模型,非常经典的数据分析标准流程,采用量应该在50%左右;听说过这个模型的同学应该相当多吧,尤其是有咨询公司背景的同学,有了这个框架,那我们如何实现具体流程的呢?
(图片来自原PPT)
CRISP-DM (cross-industry standard process for data mining), 即为"跨行业数据挖掘标准流程",CRISP-DM 模型是KDD(KDD:Knowledge Discovery in Database)模型的一种,最近几年在各种KDD过程模型中占据领先位置,它是由戴姆勒-克莱斯勒、SPSS和NCR的分析人员共同开发的。CRISP提供了一种开放的、可自由使用的数据挖掘标准过程,使数据挖掘适合于商业或研究单位的问题求解策略。
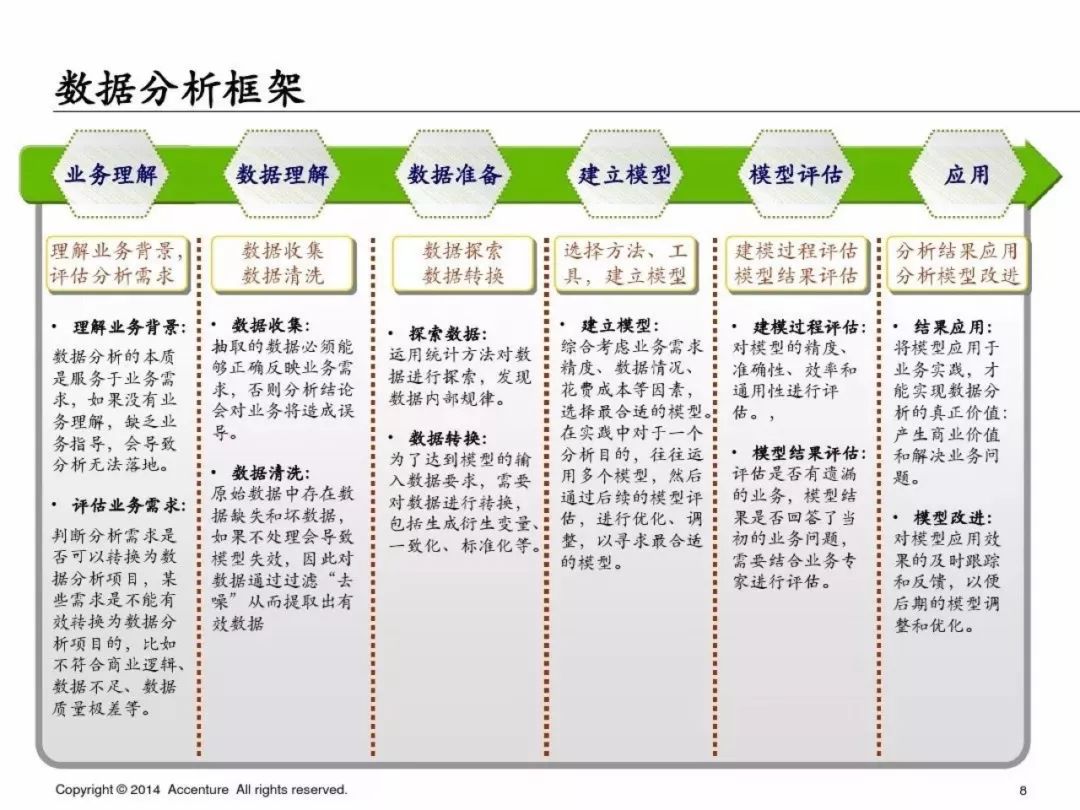
从我自己的理解:如果我们的分析需要建立模型,那么这个流程其实缺少模型监控,在完成建模分析后,我们需要持续观测模型的稳定性和准确度,在发现问题时可能需要及时的refit我们的模型。
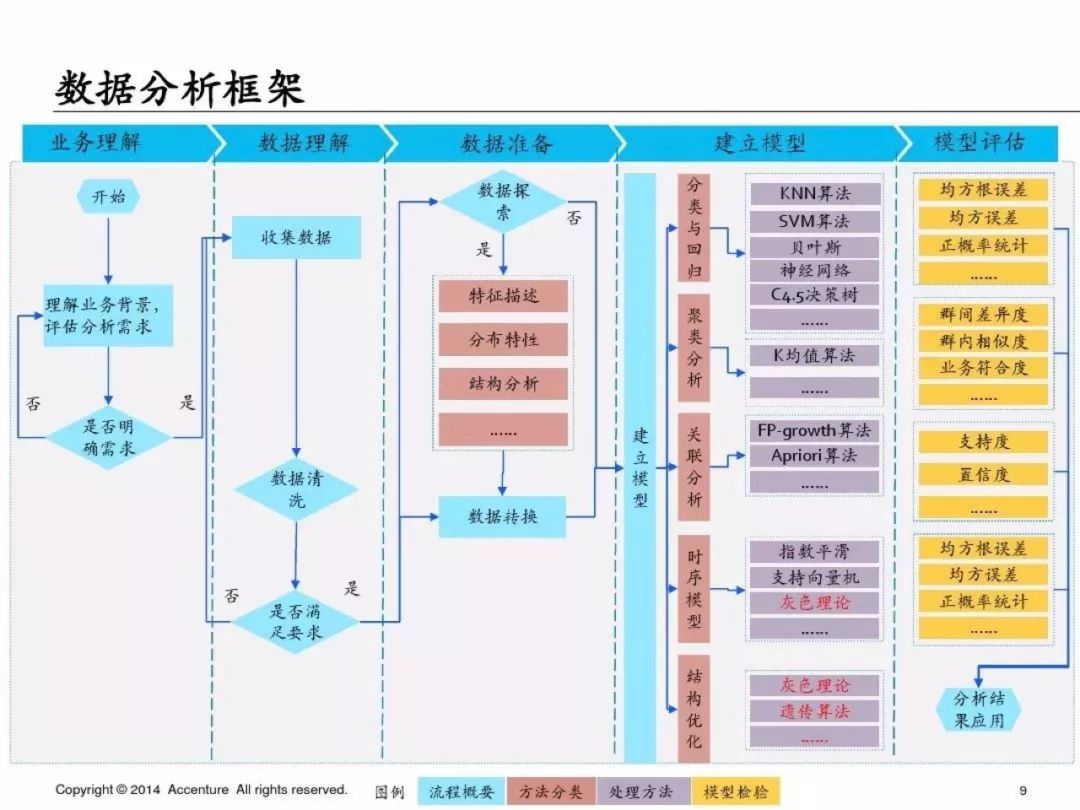
当我们需要建模来解决某个业务问题时,这个就是数据分析的基本框架。但是我觉得这个框架里在建立模型时可以做一些补充:
(这里补充上自己做的关于模型选择的思维导图)
3、数据分析方法
3.1数据清洗&数据探索
在我们拿到数据时首先我们需要对数据进行清洗:
这里一些一定要做的就是:异常值判断、缺失值处理、重复值处理、数据结构变化;
数据探索:主要是特征描述、数据分布、结构优化、变量相关性。
这里说一下我每次会用到的方法,用一行代码直接完成数据描述:
import pandas_profiling
data.profile_report(title='Model Dataset')
profile = data.profile_report(title='Model Dataset')
profile.to_file(output_file='model_report.html')常见异常值的判断方法:
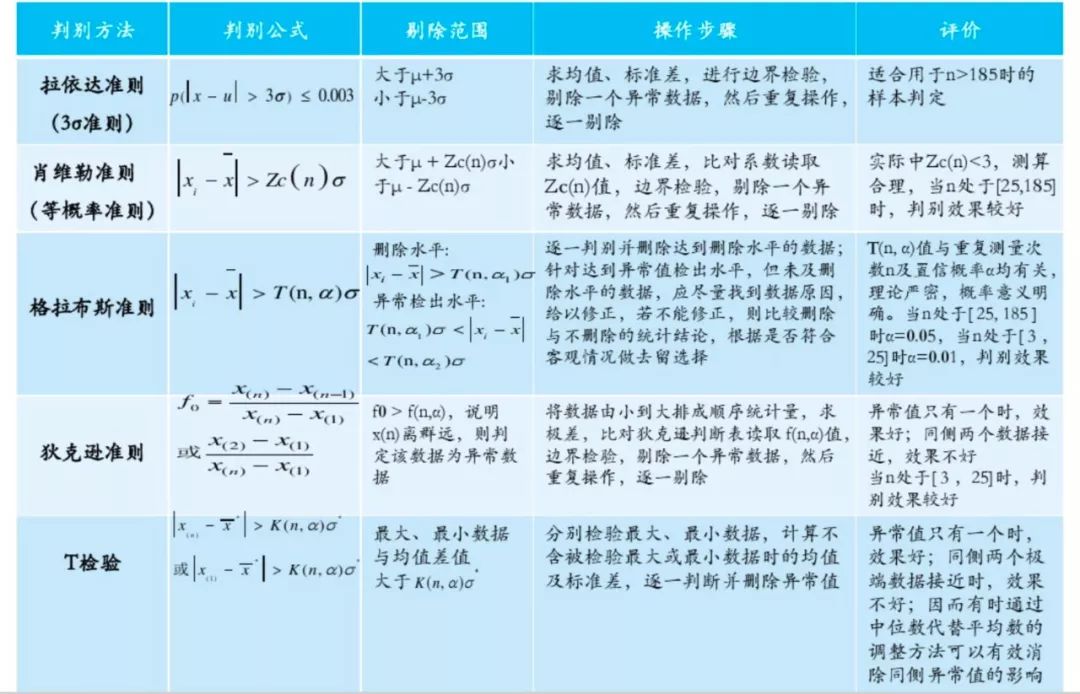
缺失值的处理方法:平均值/固定值/众数/中位数/上下条数据等填充、K最近距离法、回归、极大似然估计、多重插值等
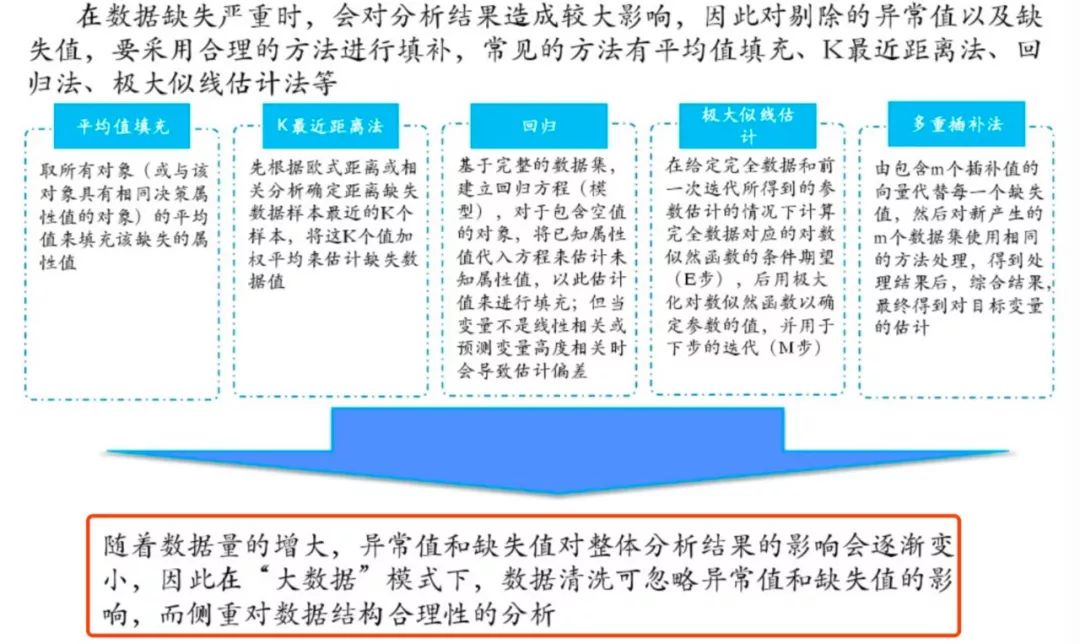
原PPT里的这一句我是完全不赞同的,在某些情况下异常值和缺失值缺失影响会比较小埃森哲 大数据 场景,但是并不可以忽略,尤其是异常值,某些情况下非常影响结果,还是需要引起重视。
对于缺失值的处理,除了直接删除缺失严重的特征外,还可以选择各种各样的填充方法。对于每一种填充方式而言,都有其适用的场景,没有绝对的好坏之分,因此在做数据预处理时,要多尝试几种填充方法,选择表现最佳的即可。
上述缺失值处理方法的代码参考:
举一个KNN填充缺失值得例子:
填充近邻的数据,先利用knn计算临近的k个数据,然后填充他们的均值。(安装fancyimpute)除了knn填充,fancyimpute还提供了其他填充方法。
from fancyimpute import KNN
train_data = pd.DataFrame(KNN(k=8).fit_transform(train_data), columns=features)数据探索
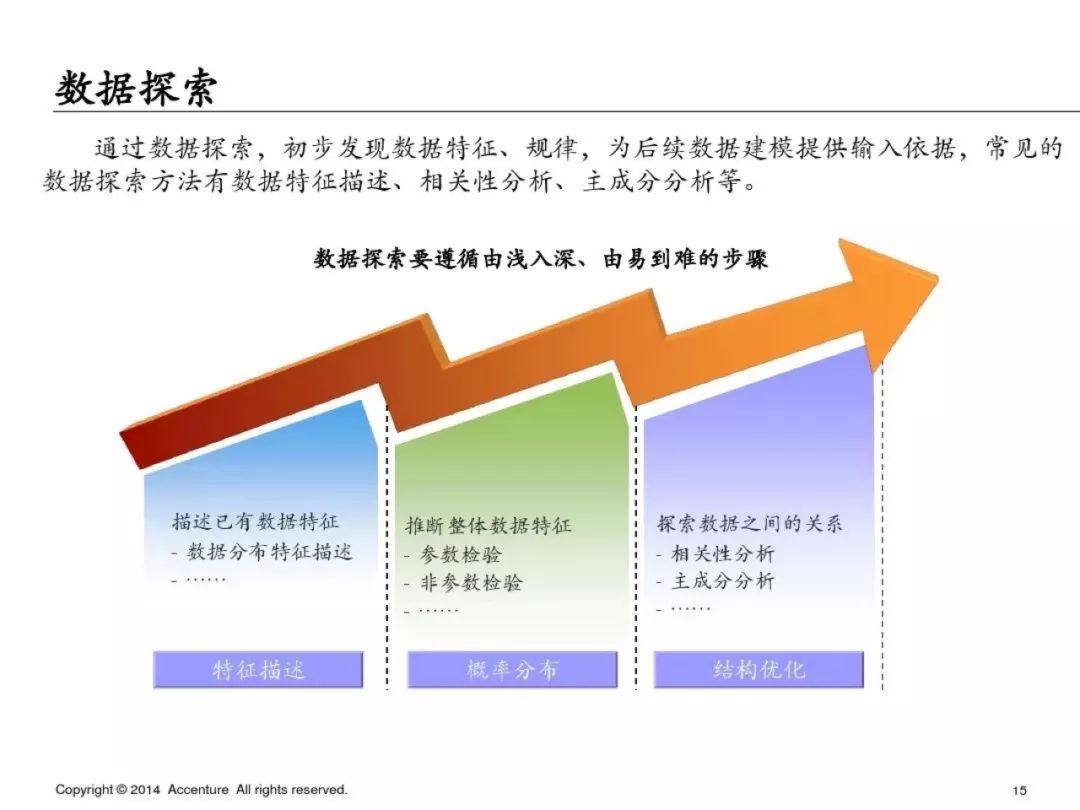

来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。




