
随着行业IT应用的业务复杂度提升、数据级日渐庞大、应用面越来越广、并发压力也越来越高。为了应对这样的情况,分布式系统的解决方案随之而出,成为目前主流架构模式。当然,是否采用分布式方案取决于实际业务系统要求。
分布式系统涉及到的技术层面非常广,本文只针对在规划设计分布式系统时会面临到的分布式事务问题采取的解决方案进行总体阐述。
分布式系统架构
随着行业业务及互联网不断的高速发展,业务的复杂度也越发更高,数据增长快、并发性能要求高,造成近年来大部分业务系统逐步转化成采用分布式架构。
对业务进行合理的、有前瞻性的服务化拆分规划是目前所有大型系统采取的一个原则,而大型的系统技术架构也要基于该原则,面向服务化的系统架构设计要服务于业务规划设计方案。
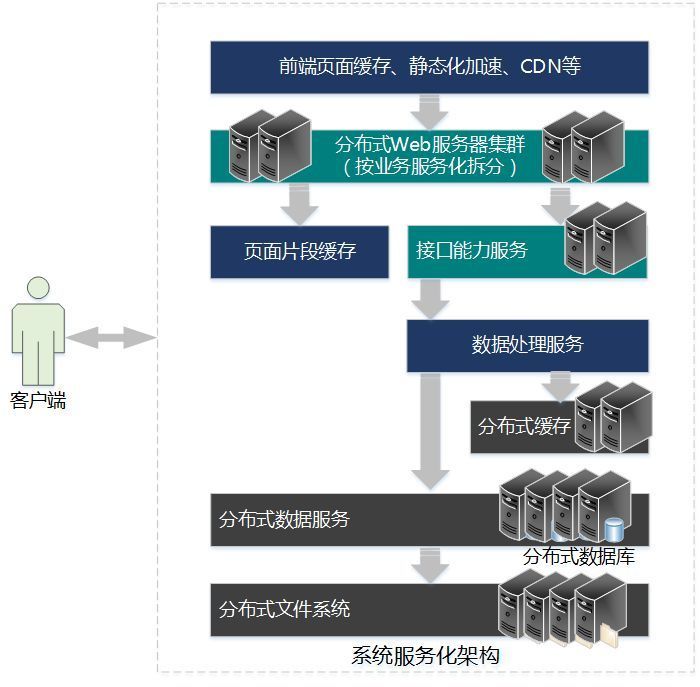
分布式系统架构大概的模式
目前大部分大型WEB系统发展趋向都采用类似互联网基于业务服务化进行架构设计模式,对业务进行深入拆分规划、服务化等,微服务、SOA 等服务架构模式正在被大规模的使用。业务系统的服务部署也逐步采用各种主流的技术方案,例如虚拟化、Docker、云托管等。
分布式系统架构的采用、业务服务化和微服务的采用对于大型WEB系统可降低系统开发整体难度、提升系统开发迭代周期和效率等,也可以引入不同的技术栈协同开发数据业务化,不同开发团队同时协作开发。
这时产生了一个问题,业务系统的服务拆分的颗粒越细、越独立,例如像现在很多大型平台搭建各种业务中台、技术中台等,反而有时会使系统架构设计的复杂度变的更高,采用的技术底层处理框架会更复杂。从业务处理方面看,会带来一个分布式事务处理的问题,数据的一致性的解决复杂度会比以往单机系统更高。
什么是事务
1. 事务的具体定义
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。
简单地说,事务提供一种“要么什么都不做,要么做全套”机制。
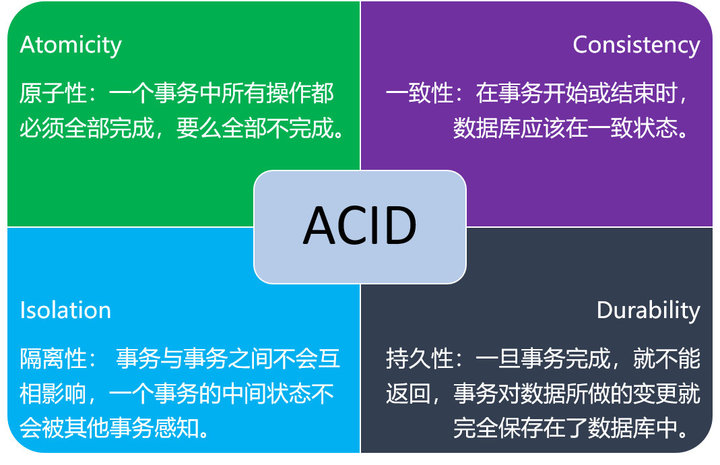
2. 事务的ACID
我们常说的ACID,特指结构化关系型数据库的特性。
关系数据库的ACID模型拥有:高一致性(C)和可用性(A), 很难进行分区(P)。
什么是分布式事务
百度百科:分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。
举例:在电商平台进行一次商品的采购就是一次分布式事务,其中包括商品选择、下单、库存、付款、对接支付平台、返回购买的结果等过程。
本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务的产生原因
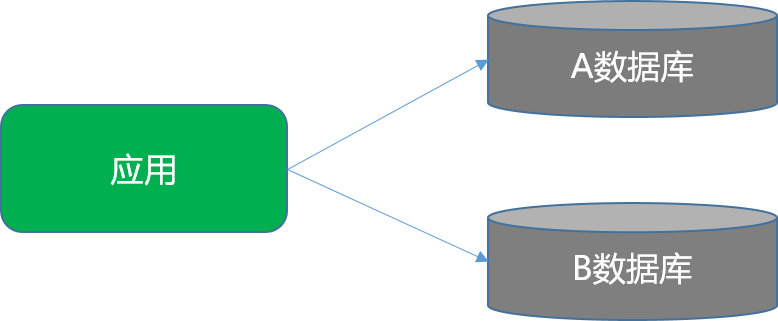
1. 数据架构规划或调整时进行分库分表
在前期数据架构设计时或者到了一定的数据级别时,进行了分库分表(垂直+水平)的操作,甚至进行深度调整改成分布式数据服务,就必然会用到分布式事务。如:某业务操作涉及访问操作A数据库、又访问操作B数据库库,有可能两个库所存放的位置还不同,所以该业务操作必须访问操作A、B库成功后,才算业务操作成功完成。
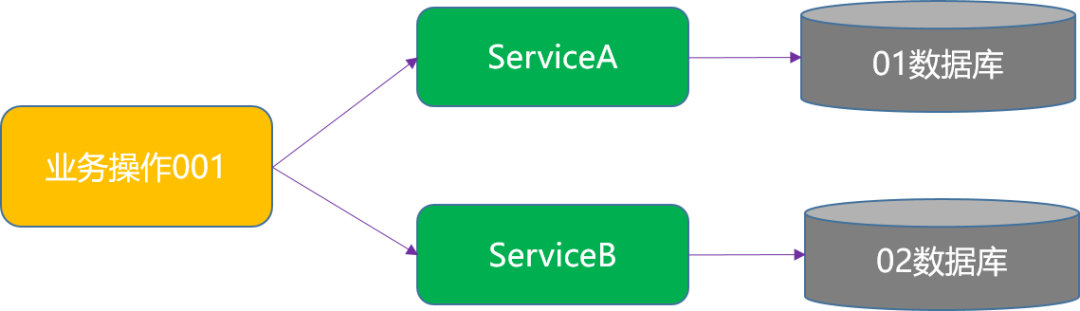
2. 业务服务化
由于业务系统的业务复杂度不断提升,考虑并发高时系统稳定等,同时为了方便团队协作开发业务应用,目前大部分都是采用基于服务的架构体系,按业务情况进行拆分成大量独立的服务或微服务,然后进行独立部署。
后期实际业务访问操作时会涉及到多个应用服务的调用,同时各个服务会针对自己业务的数据进行操作,为了保证整个业务访问过程涉及的数据一致性,就需要用到分布式事务。
分布式事务基础理论
之前说过数据库事务的 ACID 四大特性,已经无法支持分布式事务。由于分布式事务是来源于分布式系统的,在设计分布式系统时,业界主要有两大理论:CAP和BASE。
1. CAP
CAP理论的定义很简单,CAP三个字母分别代表了分布式系统中三个相互矛盾的属性:
CAP理论指出:无法设计一种分布式协议,使得同时完全具备CAP三个属性,即
分布式系统协议只能在CAP这三者间所有折中。CAP理论的详细证明可以参考相关论文。
副本定义:(replica/copy)指在分布式系统中为数据或服务提供的冗余。对于数据副本指在不同的节点上持久化同一份数据,当出现某一个节点的存储的数据丢失时,可以从副本上读到数据。
根据定理:任何分布式系统只可同时满足二点,没法三者兼顾。所以设计分布式应用系统的系统架构时,与传统的非分布式系统要有所区别,要根据实际业务场景及应用要求进行取舍,不要浪费精力在如何设计能满足三者的完美分布式系统上。
2. BASE
BASE思想可以说是CAP理论的进一步发展延伸。
BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性(C),获得可用性(A)或可靠性(P):
目前大部分分布式系统(例如互联网平台)多采用BASE思想指导设计及实现。
常见分布式事务解决方案
1、 2PC(基于XA协议的两阶段提交)
XA是一个分布式事务协议。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA实现分布式事务的原理如下:
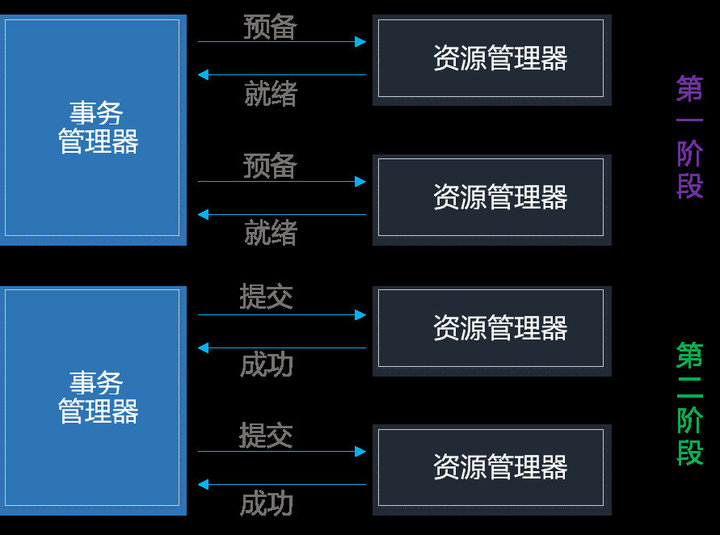
总的来说,XA协议比较简单,尽量保证了数据的强一致性,使用分布式事务的成本也比较低,在各大主流数据库都有自己实现,对于 MySQL 是从 5.5 开始支持。
但是,XA也有致命的缺点,那就是性能不理想, XA无法满足高并发场景,不能支持高并发(由于同步阻塞)依然是其最大的弱点。
单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能。比如在第二阶段中,假设协调者发出了事务 Commit 的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了 Commit 操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
2. TCC编程模式
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:
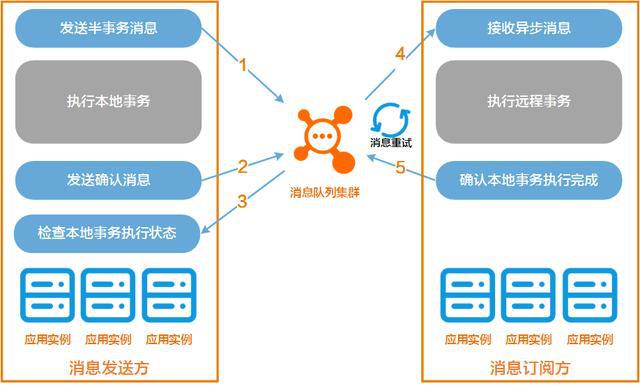
Try 阶段:尝试执行,完成所有业务检查(一致性),预留必需业务资源(准隔离性)。
Confirm 阶段:确认真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源,Cancel 操作满足幂等性。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
总之,TCC就是通过代码人为实现了两阶段提交,
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。
