
数据可视化现状调研 概述
数据可视(Data visualization)数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。但是,这并不就意味着,数据可视化就一定因为要实现其功能用途而令人感到枯燥乏味,或者是为了看上去绚丽多彩而显得极端复杂。为了有效地传达思想概念,美学形式与功能需要齐头并进,通过直观地传达关键的方面与特征,从而实现对于相当稀疏而又复杂的数据集的深入洞察。然而,设计人员往往并不能很好地把握设计与功能之间的平衡,从而创造出华而不实的数据可视化形式,无法达到其主要目的,也就是传达与沟通信息。
背景
在专业视听领域,最初的可视化要求比较简单。大屏显示系统只是作为显示载体,通过前端抓取、传输信息,并将图像、音视频信号传输到屏幕上显示即可。但随着大数据、人工智能等技术的飞速发展,如今的大屏显示系统不仅要负责对海量数据信息进行高效率的分析,还要将分析结果展现出来,帮助用户发现挖掘数据背后的逻辑和规律,为用户决策行为提供依据。
这无疑对专业视听企业提出了更高要求。长期以来,专业视听厂商主要以提供硬件为主,而如今却需要厂商对软硬件都要有很强的开发能力,并对各行业有非常深入的了解。然而任何一个行业应用都会牵涉到很多不同数据之间的对接和分析,目前还很少有企业能够做到完全胜任。同时这还需要大量时间、资金的投入以及人才的培养。这种费时费力费钱的事,并不是每个企业都愿意去做的,但这并不影响数据可视化成为一种趋势。
数据可视化所需具备的条件
一个好的大屏数据可视化系统需要具备以下六个条件:
管理数据:即从数据采集、清理、整合方面,能提供完整的系统工具平台。支持各种类型的数据接入、灵活设置数据清洗规则、采用合理的数据管理模型整合数据,帮助企业很好的管理数据。
可视数据:可提供可视化的数据展示设计工具,可以快速实现基础数据、业务指标、可视化展示的设计应用,能够直观的看懂理解业务数据。
应用数据:数据可视化不能只是简单的图形化,更重要的是能够发现业务潜在的风险、价值。能够支持业务规则、算法模型的嵌入应用,对数据进行挖掘分析,再通过可视化手段展示分析结果,真正能用数据驱动业务。
业务服务:数据可视化平台是为客户的生产业务提供服务的,所以系统需要能够实现业务的监控、预警、分析、处置的能力。
系统要具备灵活的编辑、设计能力,从数据管理、指标定义、可视化展示能够通过可视化的实施工具灵活自定义,用户就可以根据自己的需求设置数据可视化的分析展示。
系统要能够支持 Windows、Android、iOS 系统,满足拼接屏、液晶屏、PC、移动端的灵活应用。
从以上可以看出,在数据可视化大屏系统中,数据的挖掘、分析及呈现,是数据可视化环节中的关键,同时也是区别一个大屏系统是否是真正的数据可视化系统的判断标准。
数据类型&数据关系
在进行数据分析、数据图表绘制或数据可视化之前,必须要对数据的类型以及数据之间的关系有所了解。在此基础上,我们才能选择正确的图形来展示分析数据并进行数据可视化。
分类数据
可以进行分组或排序,通常都是文字类型(可以分为有序和无序,均为离散数据);
量化数据
可以测量,所有的值都是数字(可以是连续数据或离散数据)
时间数据
以时间作为数据内容(既可以作为连续数据,又可以作为离散数据)
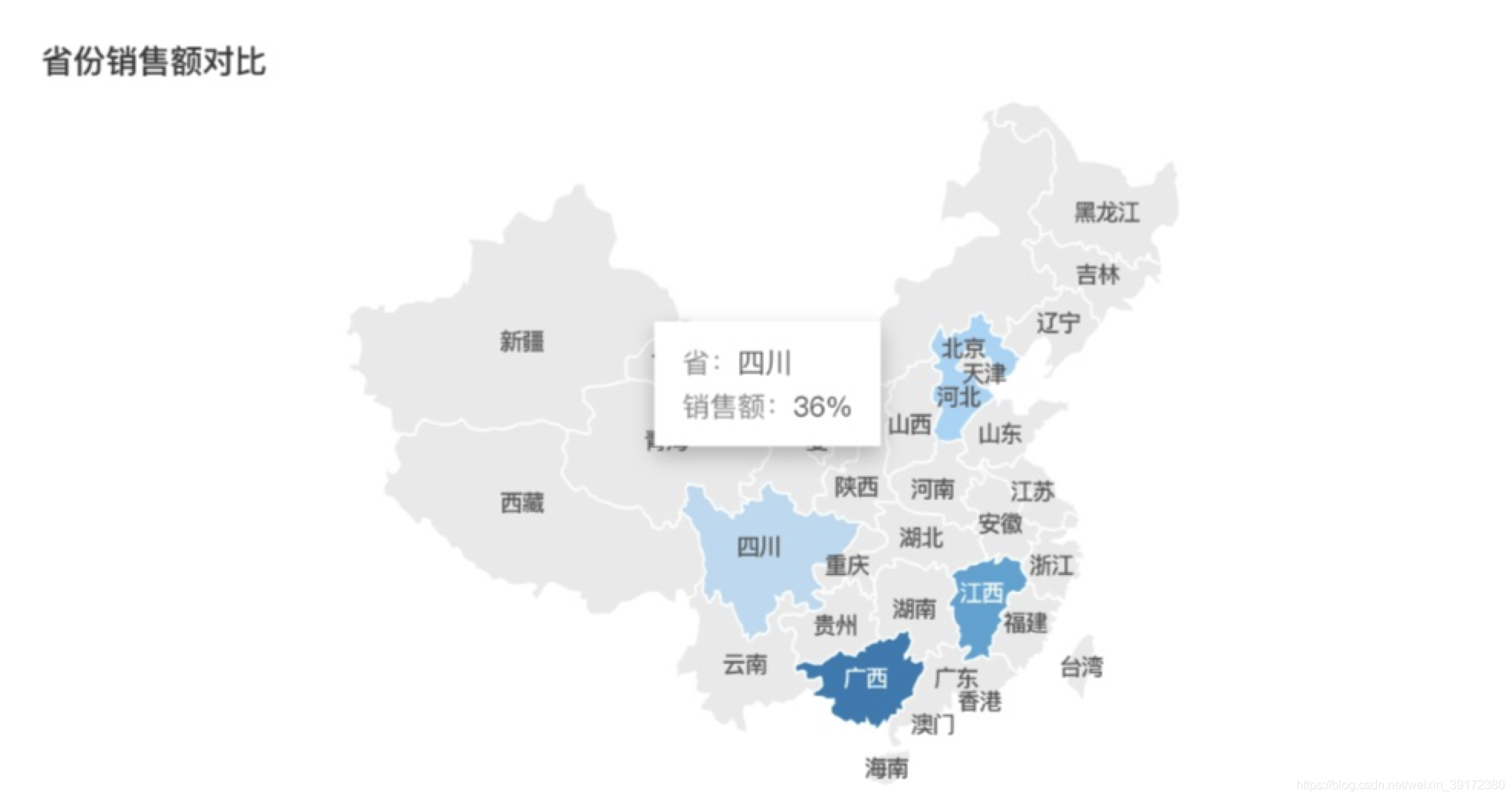
地理数据
用作地理位置的标示(地名 / 经纬度信息,属于离散数据)
当然数据可视化 应用,从严格的分类角度讲,时间和地理数据应该都属于分类数据(维度),把它们单独分离出来的目的是为了更好的进行可视化分析和展示
我们再简单讨论一下离散和连续。“离散”和“连续”是一个数学术语,但是不要害怕,定义其实很简单。连续意指“构成一个不间断的整体,没有中断”;离散意指“各自分离且不同”。看下面两个图就明白了
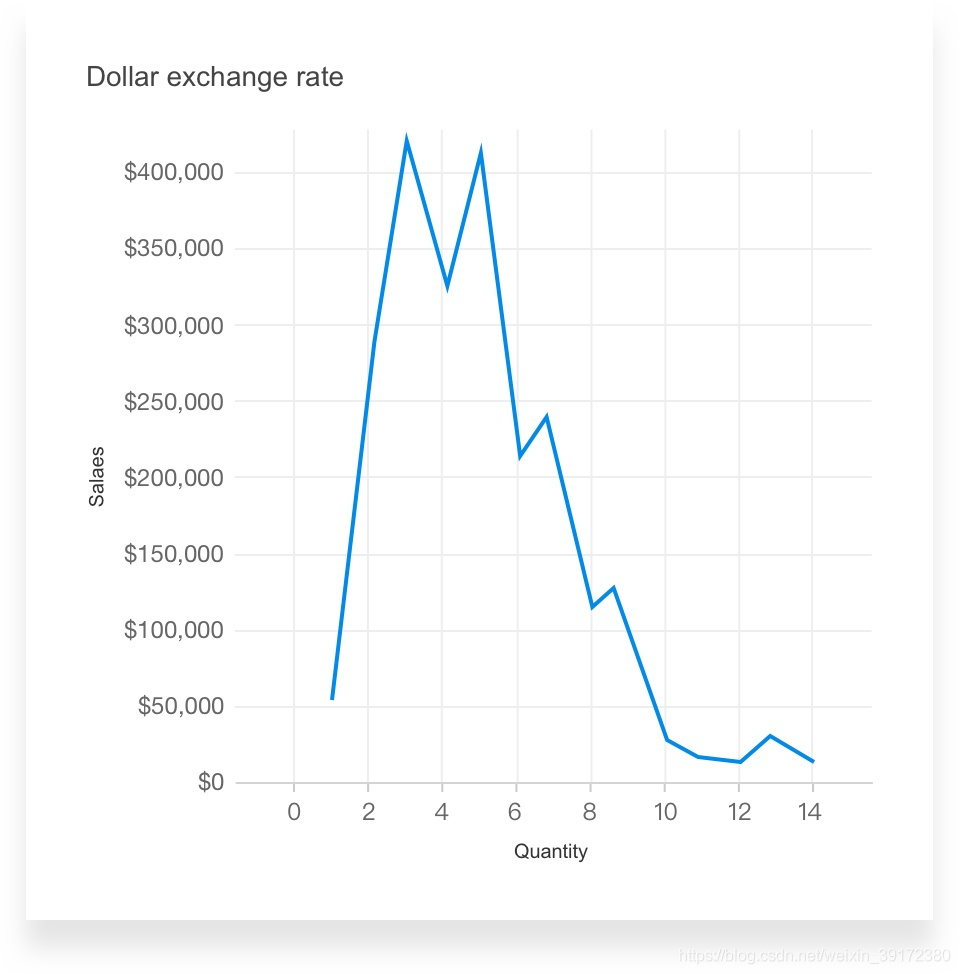
当把数据看作连续数据,并作为轴时,数据点不一定和刻度对应,而是根据实际的数值在轴的方向上分布。
当把数据当作离散数据,并作为标题时,数据点都会落在刻度上,并进行区隔。
通过数据的分类和特点,我们就有了数据可视化的一些基础信息,这对于我们选择图形来说,相当于有了一个筛选条件。
数据关系
这里说的数据之间的关系指的是数据点之间的关系,而不是通常的数据表之间的关系数据可视化 应用,数据点的关系既简单又复杂,但是对于数据可视化来说,却是不可或缺的一部分信息。
发现并正确描述数据之间的关系,可以说是一个真正的商业技能,这取决于你对数据和业务的理解程度,但是这个过程也并非无迹可寻,我们通常也可以把数据之间的关系分为以下七类:
简单对比
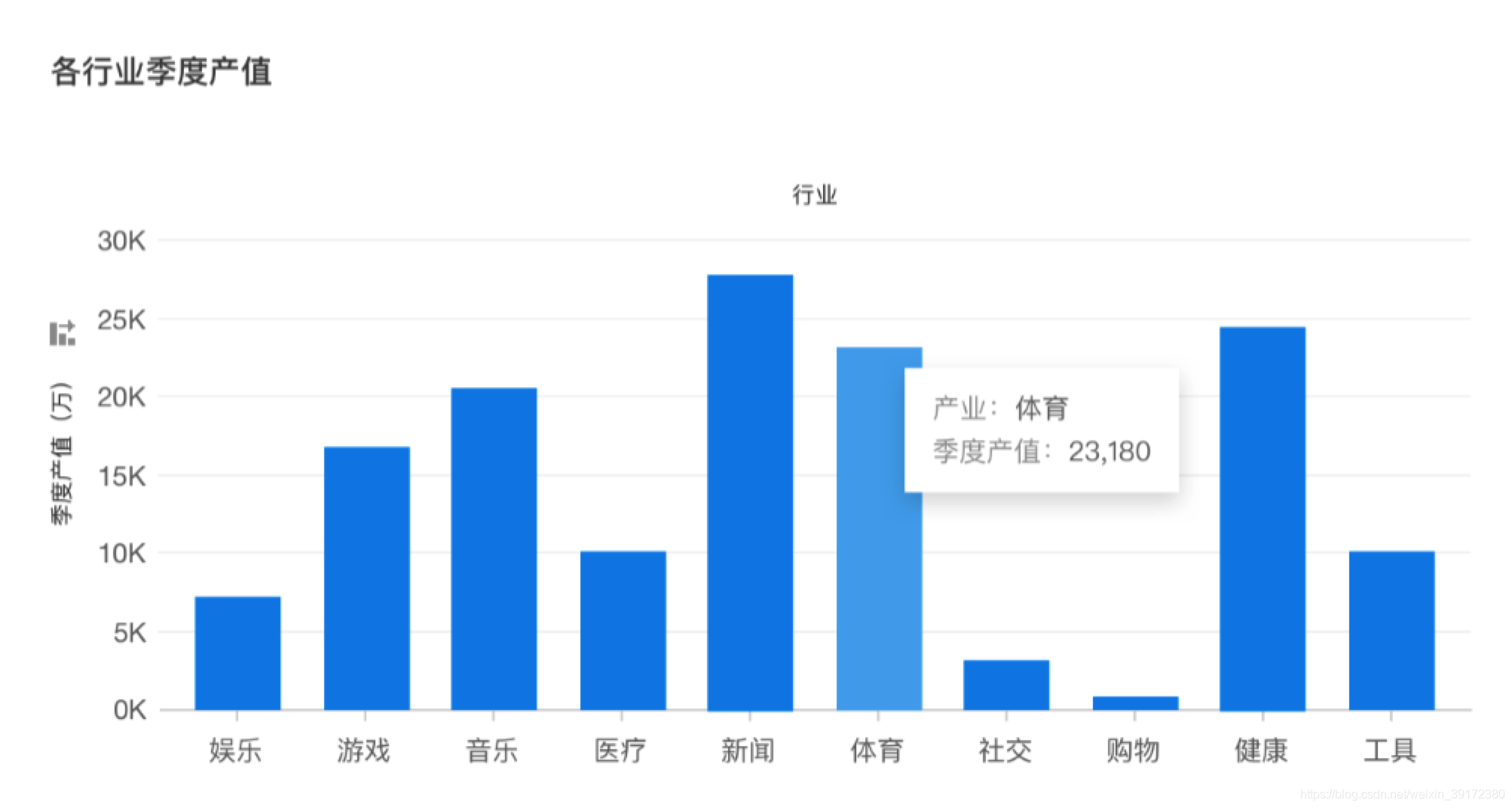
顾名思义,对分类的量化数据进行简单的对比,从而更直观的了解两者的量化对比情况,通常用来发现问题。比如:不同磁盘的空间使用率。
时间序列
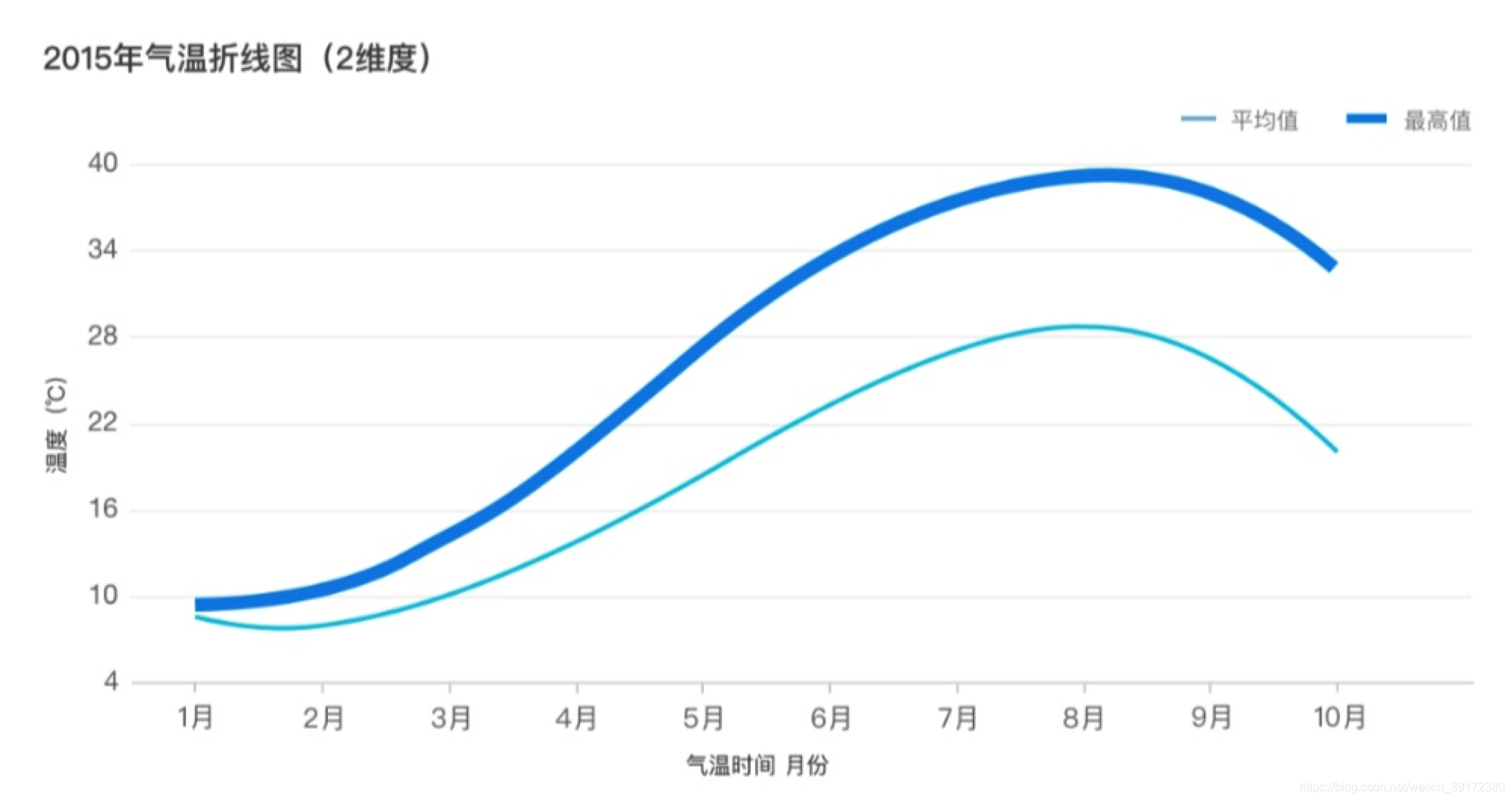
显示同一维度下数值随时间的变化,通常可以帮助人们发现趋势,进行预测。比如:随时间变化的cpu使用率。

3. 相关性
同一维度下两个数值的变化关系对比,从而发现正相关性或负相关性,以了解数据的相关情况,通常用于因果关系的发现。比如:内存使用率和虚拟内存使用率。

4. 分级排序
两个以上的数值互相之间的关系,通常用于排序分级,从而查看顺序和数量。比如:集群负载排名。

偏差性
通过观察数据点之间的关系,发现一些特殊的,与普通数据有明显不同的情况,用于观察数据偏离度。比如:交换机端口速率。

分布情况
描述数据围绕核心数值的一个分布情况,用于观察数据的分布方式和情况。比如:请求响应时长的分布情况。

来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





