
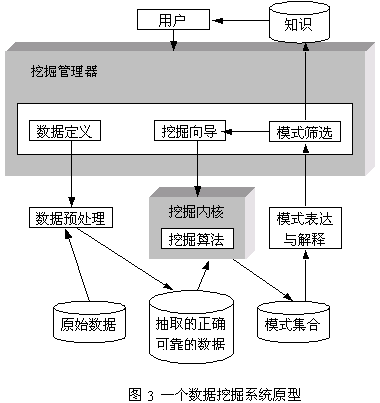
一、数据挖掘、知识发现的概念
数据挖掘 Data Mining :是指从海量的数据中通过相关的算法发现隐藏在数据中的规律和知识的过程。
知识发现:数据挖掘是知识发现中的一个步骤。当提到“数据挖掘”时,通常情况下要表述的是知识发现的整个过程。
数据预处理包括:数据清理和数据集成。
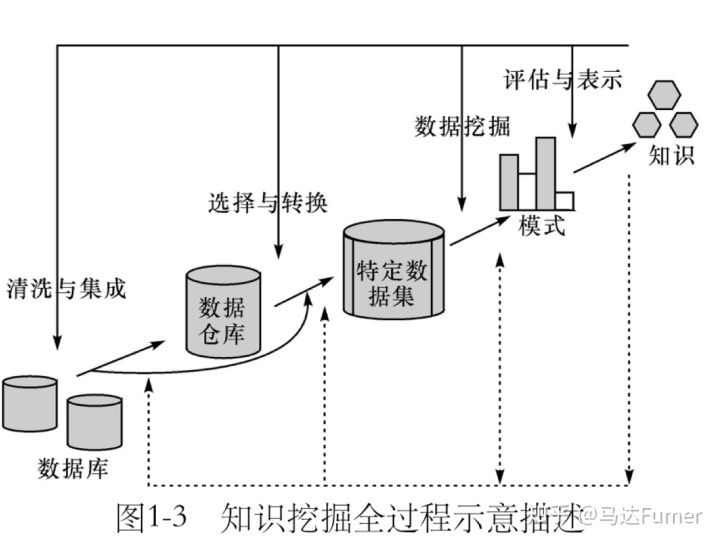
知识发现的过程:
①数据清理:消除数据中的噪声
②数据集成:将不同来源的数据组合在一起
③数据选择:从数据库中选择与任务相关的数据
④数据变换:将数据变换成适合挖掘的形式
⑤数据挖掘:使用数据挖掘的方法发现知识
⑥模式评估:识别知识中有用的模式
⑦知识表示:将挖掘到的知识用可视化的技术表示出来
数据分析和数据挖掘的区别:
(1)数据挖掘处理的是“海量”的数据,数据分析处理的数据不一定很大
(2)数据分析往往有明确的目标,而数据挖掘所发现的知识往往是未知的,需要通过数据挖掘的方法发现隐藏在数据中的有价值的信息和知识。
(3)数据分析着重于展现数据之间的关系,而数据挖掘可以通过现有数据结合数据模型,对未知的情况进行预测和估计。
二、分析与挖掘的数据类型 数据库数据+数据仓库数据+事物数据
1.数据库数据
2.数据仓库数据
3.事务数据
事务数据库的每个记录代表一个事务。(例如:一次车票的预定,顾客的一个订单)一个事务由一个唯一的标识号和一组描述事务的项组成。
4.数据矩阵
5.图和网状数据
图和网状结构通常用来表示不同节点之间的联系。如人际关系网、网站之间的相互链接关系等。
一般来说,被指向次数越多的网页,其重视程度越高。
三、数据挖掘和数据分析的方法
1.频繁模式
频繁模式就是在数据集中频繁出现的模式,多次出现的事物可能具有特殊的意义。例如:啤酒和尿不湿的故事。(数据的关联)
2.分类和回归
3.聚类分析
聚类是把一些对象划分成多个组或者聚簇,从而使同组内对象间比较相似而不同组对象间差异较大。聚类通常归于无监督学习,由于无监督算法不需要标签数据。它适用于许多难以获得标签数据的应用。
4.离群点分析
离群点是指全局或局部范围内偏离一般水平的观测对象。一般情况,离群点会被当作噪声而丢弃,但在特殊的应用中,离群点由于特殊的意义而被重视。(当一个人的信用卡在不经常消费的地区短时间消费了大量的金额,则认定这张卡的使用情况异常,需要及时采取措施)
四、数据分析和数据挖掘使用的技术
1.统计学方法
2.机器学习
(1)监督学习:在有标记的数据集上进行。对于训练集中的每个手写数字,标记它是0-9的哪个数字,并在训练的过程中输入数据和数据标记一同提供给学习器,在训练结束后,将不在训练数据集中的一张图像输入学习强,学习器根据学到的知识给出图像中包含的数字数据分析与数据挖掘的区别,因此,监督学习是一个分类的过程。
(2)无监督学习:在没有标记的数据集上学习,同样以手写数字数据集为例,通过对数据集上的数据进行学习,学习器得到了10个不同的类别,代表0-9个数字。当新的手写数字的图形输入学习器后,学习器会给出该图像属于这10个类别中的哪一个。但是,训练集没有任何标记,学习器不知道每个类别代表的数字是什么,不知道每个类别代表的实际语义是什么。
(3)半监督学习:在学习过程中使用标记和未标记的数据。它主要考虑:如何利用少量的有标记数据和大量未标记的数据进行学习,其中,标记的数据用来学习模型,而未标记的数据用来进一步改进类的边界。
如图:+ -是有标记的数据
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





