
大数据研究综述
陶雪娇,胡晓峰,刘洋
(国防大学信息作战与指挥训练教研部,北京100091)
研究机构Gartne:的定义:大数据是指需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
维基百科的定义:大数据指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理并整理成为帮助企业经营决策目的的资讯。
麦肯锡的定义:大数据是指无法在一定时间内用传统数据库软件工具对其内容进行采集、存储、管理和分析的赞据焦合。


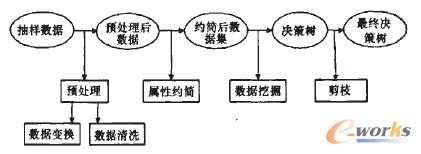
数据挖掘的焦点集中在寻求数据挖掘过程中的可视化方法,使知识发现过程能够被用户理解,便于在知识发现过程中的人机交互;研究在网络环境卜的数据挖掘技术,特别是在Internet上建立数据挖掘和知识发现((DMKD)服务器,与数据库服务器配合,实现数据挖掘;加强对各种非结构化或半结构化数据的挖掘,如多媒体数据、文本数据和图像数据等。
5.1数据量的成倍增长挑战数据存储能力
大数据及其潜在的商业价值要求使用专门的数据库技术和专用的数据存储设备,传统的数据库追求高度的数据一致性和容错性,缺乏较强的扩展性和较好的系统可用性,小能有效存储视频、音频等非结构化和半结构化的数据。目前,数据存储能力的增长远远赶小上数据的增长,设计最合理的分层存储架构成为信息系统的关键。
5.2数据类型的多样性挑战数据挖掘能力
数据类型的多样化,对传统的数据分析平台发出了挑战。从数据库的观点看,
挖掘算法的有效性和可伸缩性是实现数据挖掘的关键,而现有的算法往往适合常驻内存的小数据集,大型数据库中的数据可能无法同时导入内存,随着数据规模的小断增大,算法的效率逐渐成为数据分析流程的瓶颈。要想彻底改变被动局面,需要对现有架构、组织体系、资源配置和权力结构进行重组。
5.3对大数据的处理速度挑战数据处理的时效性
随着数据规模的小断增大,分析处理的时间相应地越来越长,而大数据条件对信息处理的时效性要求越来越高。传统的数据挖掘技术在数据维度和规模增大时,需要的资源呈指数增长,面对PB级以上的海量数据,N1ogN甚至线性复杂度的算法都难以接受,处理大数据需要简单有效的人工智能算法和新的问题求解方法。
5.4数据跨越组织边界传播挑战信息安全
随着技术的发展,大量信息跨越组织边界传播,信息安全问题相伴而生,不仅是没有价值的数据大量出现,保密数据、隐私数据也成倍增长,国家安全、知识产权、个人信息等等都面临着前所未有的安全挑战。大数据时代,犯罪分子获取信息更加容易,人们防范、打击犯罪行为更加困难,这对数据存储的物理安全性以及数据的多副本与容灾机制提出了更高的要求。要想应对瞬息万变的安全问题,最关键的是算法和特征,如何建立相应的强大安全防御体系来发现和识别安全漏洞是保证信息安全的重要环节。
5.5大数据时代的到来挑战人才资源
从大数据中获取价值至少需要三类关键人才队伍:一是进行大数据分析的资深分析型人才;二是精通如何申请、使用大数据分析的管理者和分析家;三是实现大数据的技术支持人才。此外,由于大数据涵盖内容广泛,所需的高端专业人才
小仅包括程序员和数据库工程师,同时也需要天体物理学家、生态学家、数学和统计学家、社会网络学家和社会行为心理学家等。可以预测,在未来几年,资深数据分析人才短缺问题将越来越突显。同时,需要具有前瞻性思维的实干型领导者,能够基于从大数据中获得的见解和分析,制定相应策略并贯彻执行。
大数据分析与处理方法分析
孔志文
(广东省民政职业技术学校,广州510310)
二、大数据分析的基本方面
大数据分析可以划分为五个基本方而。一是具有预测性分析能力。分析员可以通过数据挖掘来更好地理解数据,而预测性分析是分析员在数据挖掘的基础上结合可视化分析得到的结果做出一些预测性的判断。二是具有数据质量和数据管理能力。数据管理和数据质量是数据分析的重点,是应用在管理方而的最佳实践,通过数据的标准化流程和工具,可以达到一个预先设定好的高质量的分析结果。三是具有可视化分析能力。可视化是服务于分析专家和使用用户的,数据可视化是数据分析的基木要求,它可以通过屏幕显示器直观地展示数据,提供给使用者,还可以让数据自己说话,让使用者听到结果。四是具有数据挖掘算法。可视化是给数据专家和使用用户提供的,数据挖掘是给机器使用的,通过集群、分割、孤立点分析等算法,深入数据内部,挖掘使用价值,数据挖掘算法不仅要处理大量的大数据,也要保持处理大数据的运行速度。五是具有语义引擎。语义引擎能从“文档”中只能提取信息,解决了非结构化数据多样性带来的数据分析困扰,通过语义引擎,能解析、提取、分析数据,完成使用者所需要的信息提取。
三、大数据处理方法
1.大数据处理流程
大数据整个处理流程可概括为四步。一是大数据采集过程。用户端数据通过多个数据库来接收,用户可以通过这些数据进行简单的查询和处理,在大数据采集过程中,可能有大量的用户来进行访问和操作,并发访问和使用量高,有时可峰值可达上百万,需要采集端部署大量的数据库才能支持止常运行。二是进行大数据统计和分析过程。统计和分析是通过对分布式计算集群内存储的数据进行分析和分类汇总,通过大数据处理方法,以满足使用者需求,统计与分析主要特点和挑战是分析所涉及的数据量大,极大地占用系统资源。三是大数据导入和预处理过程。因为采集端木身有很多数据库,在统计和分析数据时,如果对这些海量数据进行有效分析,还应该把来自各个前端数据导入集中的大型分布式数据库,也可以导入分布式存储集群,导入后在集群基础上再进行简单的清洗和预处理工作,导入和预处理环节主要特点是导入数据量大,每秒导入量经常达到几百兆,有时会达到千兆级别。四是大数据挖掘过程。数据挖掘与统计分析过程不同的是数据挖掘没有预先设定好的主题,主要在依据现有的数据进行计算,从而实现一些高级别数据分析的需求,达到预测效果。
2.大数据处理技术
(1) Hadoop架构。Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop具有可靠性数据可视化参考文献,能维护多个工作数据副木,可以对存储失败的节点重新分布处理。它具有高效性,通过并行处理加快处理速度。具有可伸缩性,能够处理PB级数据。Hadoop架构的关键点是借助大量PC构成一个PC群难以实现对数据的处理。处理数据时,现分析数据,后结合分配的相应电脑处理数据,最后整合数据处理结果。
浅谈数据挖掘技术及其应用
舒正渝
校,甘肃兰州730050)
摘要:科技的进步,特别是信息产业的发展数据可视化参考文献,把我们带入了一个崭新的信息时代。数据库管理系统的应用领域涉及到了各行各业,但目前所能做到的只是对数据库中已有的数据进行存储、查询、统计等功能,通过这些数据获得的信息量仅占整个数据库信息量的一小部分,如何才能从中提取有价值的知识,进一步提高信息量利用率,因此需要新的技术来自动、智能和快速地分析海量的原始数据,以使数据得以充分利用,由此引发了一个新的研究方向:数据挖掘与知识发现的理论与技术研究。数据挖掘技术在分析大量数据中具有明显优势,基于数据挖掘的分析技术在金融、保险、电信等有大量数据的行业已有着广泛的应用。
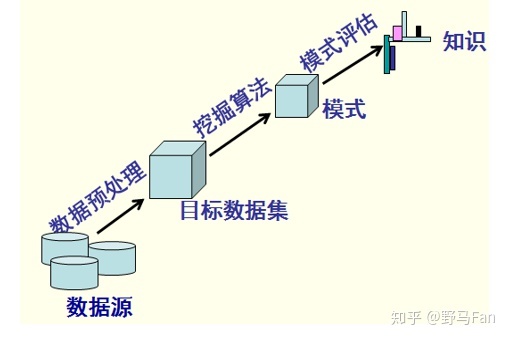
2数据挖掘的定义
数据挖掘(Data Mining),又称数据库中的知识发现(Knowledge Discovery in Database,简称KDD),比较公认的定义是由U. M. Fayyad等人提出的:数据挖掘就是从大量的、小完全的、有噪声的、模糊的、随机的数据集中,提取隐含在其中的、人们事先小知道的、但又是潜在的有用的信息和知识的过程,提取的知识表示为概念(Concepts)、规则(Rules)、规律(Regularities)、模式
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





