
个人博客
Python大作业——爬虫+可视化+数据分析+数据库(简介篇)
Python大作业——爬虫+可视化+数据分析+数据库(爬虫篇)
Python大作业——爬虫+可视化+数据分析+数据库(可视化篇)
Python大作业——爬虫+可视化+数据分析+数据库(数据库篇)
一、生成歌词词云
首先我们需要先获取所有爬取到的歌曲的歌词,将他们合成字符串
随后提取其中的中文,再合成字符串
text = re.findall('[一-龥]+', lyric, re.S) # 提取中文
text = " ".join(text)
之后使用jieba进行分词,并将其中分出来的长度大于等于2的词保存
word = jieba.cut(text, cut_all=True) # 分词
new_word = []
for i in word:
if len(i) >= 2:
new_word.append(i) # 只添加长度大于2的词
final_text = " ".join(new_word)
接下来为生成的词云选择一张好看的图片,就可以开始生成了!

mask = np.array(Image.open("2.jpg"))
word_cloud = WordCloud(background_color="white", width=800, height=600, max_words=100, max_font_size=80, contour_width=1, contour_color='lightblue', font_path="C:/Windows/Fonts/simfang.ttf", mask=mask).generate(final_text)
# plt.imshow(word_cloud, interpolation="bilinear")
# plt.axis("off")
# plt.show()
word_cloud.to_file(self.keyword+'词云.png')
os.startfile(self.keyword+'词云.png')
WordCloud参数中的contour_width=1, contour_color='lightblue’分别为背景图片轮廓线条的粗细和颜色,如果没有设置则不会出现轮廓,font_path是用来指定字体的
生成后可以通过show展示也可以通过保存到本地并打开大数据可视化效果图,最终结果如下
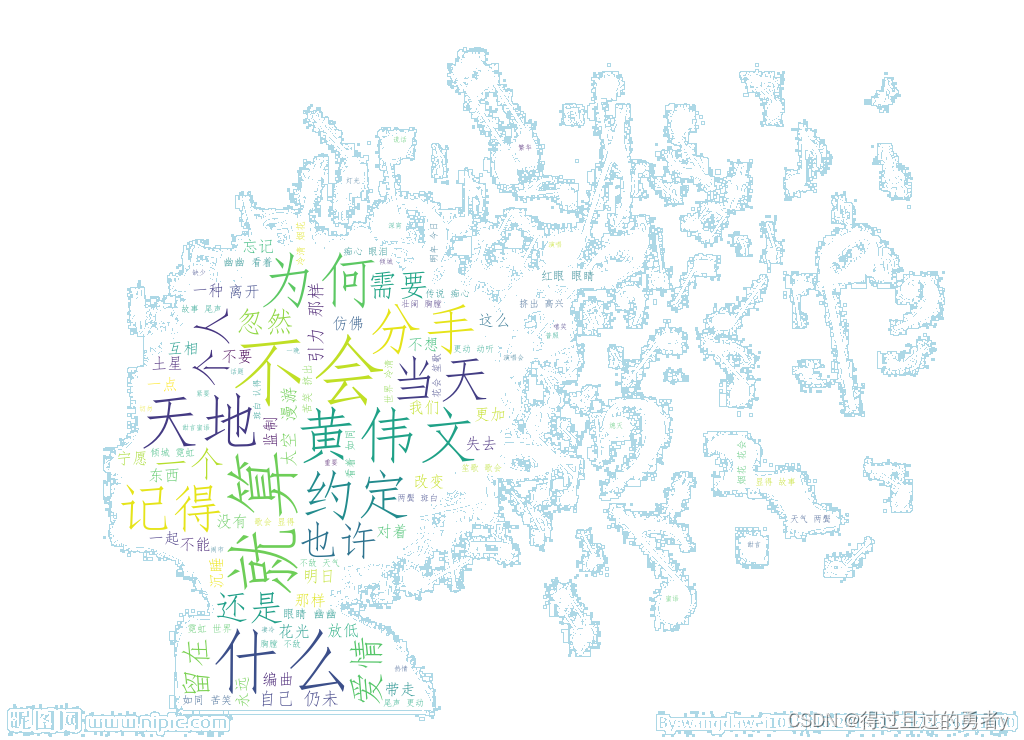
二、热门歌手歌曲量饼图
首先是获得热门歌手列表以及热门歌手歌曲量
随后用每个歌手歌曲数量除以所有这十个歌手的总歌曲数量,得到每个歌手歌曲量的占比
接下来可以选择设置哪一块突出显示,如图中周杰伦部分突出显示
如下只需要将突出部分的值设置大即可
explode = [0.1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
接下来就可以生成饼图了
plt.figure(figsize=(6, 9)) # 设置图形大小宽高
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
plt.axes(aspect=1) # 设置图形是圆的
plt.pie(x=proportion, labels=name, explode=explode, autopct='%3.1f %%',
shadow=True, labeldistance=1.2, startangle=0, pctdistance=0.8)
plt.title("热门歌手歌曲量占比")
# plt.show()
plt.savefig("热门歌手歌曲量占比饼图.jpg")
os.startfile("热门歌手歌曲量占比饼图.jpg")
其中x是歌曲量占比的列表,labels是对应的标签(在此图中则为歌手的姓名),explode就是上文提到的突出显示,这三个列表中的各个值是一一对应的,autopct是设置占比数值的显示方式,3.1f则表示占宽为3位(如果大于会原样输出),精度为1的浮点数

同样可以选择直接show展示,或者保存到本地再打开
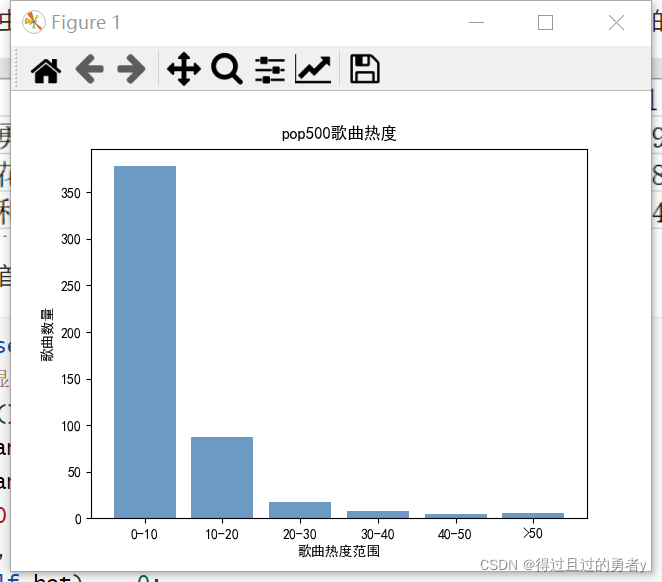
三、歌曲热度占比条形图
在之前我们通过爬虫获取了top500的歌曲的信息(如下),现在我们希望对歌曲的热度进行分析大数据可视化效果图,生成柱状图

效果图如下:
本来是想生成歌手拥有热门歌曲数量的柱形图的,但是那个爬取热门歌曲的网站中那些热门歌曲没有对应的歌手,还需要自己再去其他网站获得每首歌曲对应的歌手,太麻烦了就没这么做了,有兴趣的小伙伴可以自己实现一下
首先我们要获得每个热度范围的歌曲数量
下面的data列表就是对应x元组范围的歌曲数量
我们只要通过遍历歌曲热度列表,每次都在其data列表对应热度+1,最终即可得到每个热度范围的歌曲数量
x = ('来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





