
Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。梯度科技自主研发的Datagradient(数度),实时计算(实时开发)是一套基于Apache Flink构建的一站式、高性能实时大数据处理平台,广泛适用于流式数据处理场景。实时计算产品彻底规避繁重的底层流式处理逻辑开发工作,Flink 被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。
目前市场上主流的流式计算框架有 Apache Storm、Spark Streaming、Apache Flink 等,但能够同时支持低延迟、高吞吐、Exactly-Once(收到的消息仅处理一次)的框架只有Apache Flink。Flink具有同时支持高吞吐低延迟、支持有状态计算、支持事件时间、支持高可用性配置、提供了不同层级的API的优势。
Flink是原生的流处理系统,但也提供了批处理API,拥有基于流式计算引擎处理批量数据的计算能力,真正实现了批流统一。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
一、数度Datagradient平台
数度Datagradient解决用户数据应用开发效率低和数据资产管理混乱的难题,帮助用户快速引接数据、构建数据湖、标准规范化数据、将数据加工成业务人员易懂易用的标签实时开发提供了强大的实时处理能力,集成诸多全链路功能,方便进行全链路实时计算开发,包括强大的流计算引擎、实时计算提供Flink SQL,支持各类错误场景的自动恢复,保证故障情况下数据处理的准确性、支持多种内置函数大数据应用场景,包括:字符串函数、日期函数、聚合。
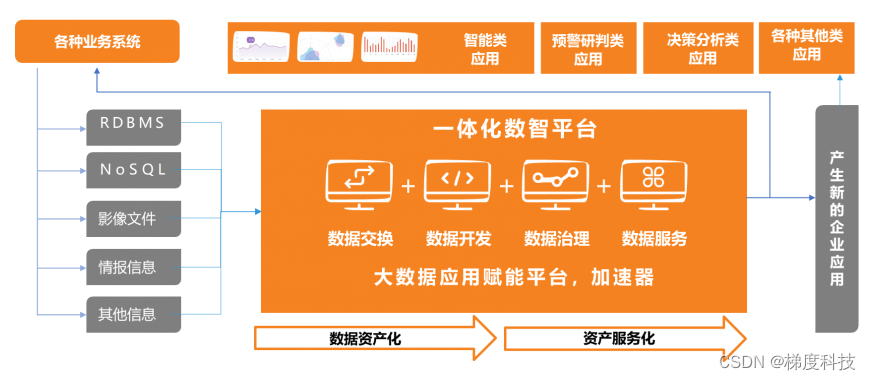
大量优化的SQL执行引擎,提供比原生Flink作业更高效且更廉价的计算作业。在开发成本和运行成本方面,实时计算均要远低于开源流式框架。轻量级本地化部署,最小五台物理机或者虚拟机即可部署实时开发平台。
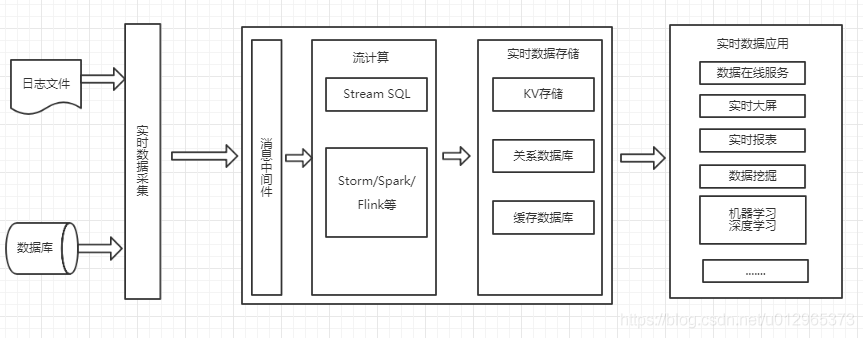
二、Flink的应用场景
Flink 的应用场景主要有以下几种类型。
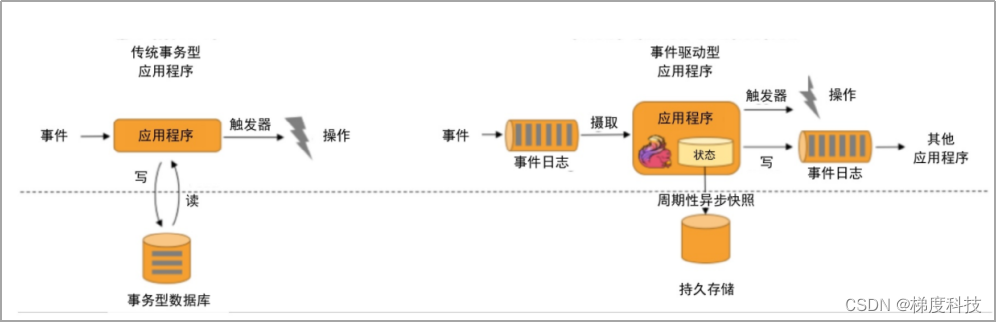
1.事件驱动
根据到来的事件流触发计算、状态更新或其他外部动作,主要应用实例有反欺诈、异常检测、基于规则的报警、业务流程监控、(社交网络)Web 应用等。
传统应用和事件驱动型应用架构的区别如下图所示。
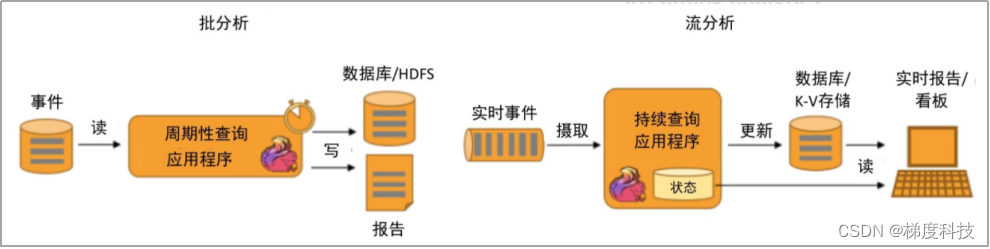
2.数据分析
从原始数据中提取有价值的信息和指标,这些信息和指标数据可以写入外部数据库系统或以内部状态的形式维护,主要应用实例有电信网络质量监控、移动应用中的产品更新及实验评估分析、实时数据分析、大规模图分析100%等。
Flink 同时支持批量及流式分析应用,如下图所示。
3.数据管道
数据管道和 ETL(Extract-Transform-Load,提取-转换-加载)作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。与 ETL 不同的是,
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





