
问题描述
请分析 Boston 数据集,并撰写一个数据分析报告。
在报告中主要分析并回答以下两个问题。
Boston 数据集查看数据集
> library(MASS)
> head(Boston) # 查看数据前6行
crim zn indus chas nox rm age dis rad tax ptratio black lstat medv
1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33 36.2
6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
数据描述
在命令行中输入
?Boston命令,Rstudio 界面出现该数据集的解释界面,如图所示:
该数据集描述波士顿郊区的房价,该数据集共506行、14列。
哑变量一般指虚拟变量。 虚拟变量 ( Dummy Variables) 又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。引入哑变量可使线形回归模型变得更复杂,但对问题描述更简明。
构建分类模型数据可视化
通过查看数据描述,我们知道了每个变量的含义。通过数据可视化,我们可以快速知道数据分布情况金融数据分析导论:基于r语言,便于下一步构造模型。查看 crim 变量,绘制箱线图。因为数值多分布在0-1范围内,所以在该箱线图中,对y轴的显示取对数,便于更方便地观察数据。
boxplot 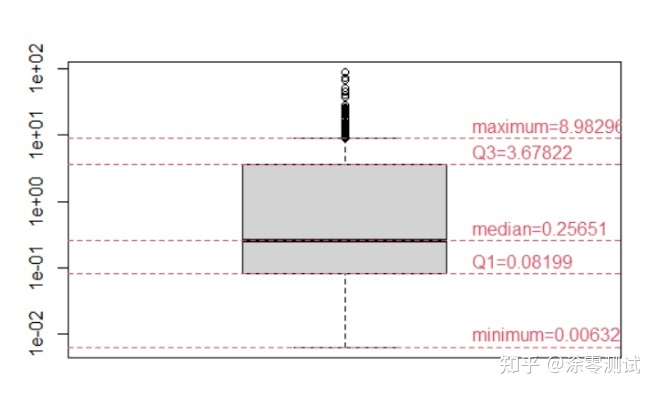
logistic 分类模型构建分类模型的因变量
构建 logistic 分类模型的因变量,该因变量是二分类的。我们将高于犯罪率中位数的项记为“1”,否则为“0”。
dt median(dt$crim), 1, 0)
构建三个不同自变量的模型
#### 构建3个模型 ####
log.fit 交叉验证
进行交叉验证,将准确率作为衡量标准。
fold_log 0.5, 1, 0)
a 结果分析
> fold_log(log.fit,dt)
[1] 0.9150087
> fold_log(log.fit2,dt)
[1] 0.9229287
> fold_log(log.fit3,dt)
[1] 0.9090433由输出结果可知,log.fit2 即第二个模型的准确率更高,为$0.9229287$。
LDA 回归模型
同理金融数据分析导论:基于r语言,
lda 结果分析
> fold_lda(lda,dt)
[1] 0.8556253
> fold_lda(lda2,dt)
[1] 0.8575861
> fold_lda(lda3,dt)
[1] 0.8635469由输出结果可知,lda3 即第三个模型的准确率更高,为 0.8635469。
K 临近模型
#### 模型1 ####
# k=1
library(kknn)
library(caret)
set.seed(3)
folds 0.5, 1, 0)
a 0.5, 1, 0)
a 0.5, 1, 0)
a 0.5, 1, 0)
a
试看结束,如继续查看请付费↓↓↓↓
打赏0.5元才能查看本内容,立即打赏
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





