
对于时空数据集的可视化,往往会query多种类型的数据维度。比如下图所示,为了查询“温哥华去年夏天使用安卓手机的数量”,需要从空间维度挑选出“温哥华”地区,再从时间维度挑选出“去年夏天”的时间段,最后取出“安卓”的数据。这个过程对于大型的时空数据集来说是一个不小的挑战,因为每一次查询都会是一个非常耗时的过程。
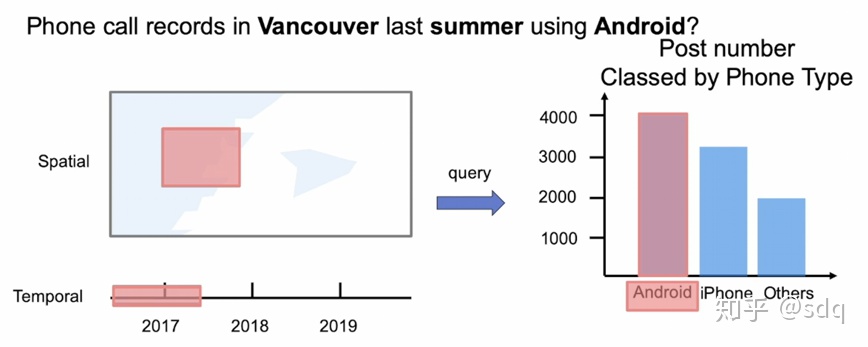
图1. 时空数据集可视化示例
为了加速这个过程,我们可以对数据集在初始化的时候进行预先的计算。这也就衍生出了两个概念,第一个是如下图中间所示的数据立方体(Data Cubes),它包含了一个数据集所有的累计运算情况,其中如图示中左右两侧的每一个立方体(Cuboid)都包含了一种累计运算情况的所有计算结果。有了这样的一个Data Cubes,当用户进行查询的时候,就可以快速地获取数据并进行可视化了。
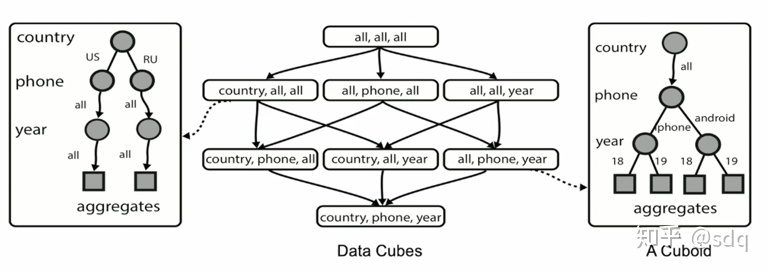
图2 Data Cube和Cuboid
Data Cubes存在的问题是冗余非常严重,在整个立方体中其实有很大一部分是用不到的,但我门却进行了计算和存储。这些冗余源自于两个方面:
第一,通常可视化系统的任务是固定的,不可能囊括所有的Data Cubes。
第二,用户往往有固定的查询偏好,在一定的偏好下通常只有部分的Cuboids会被使用到。
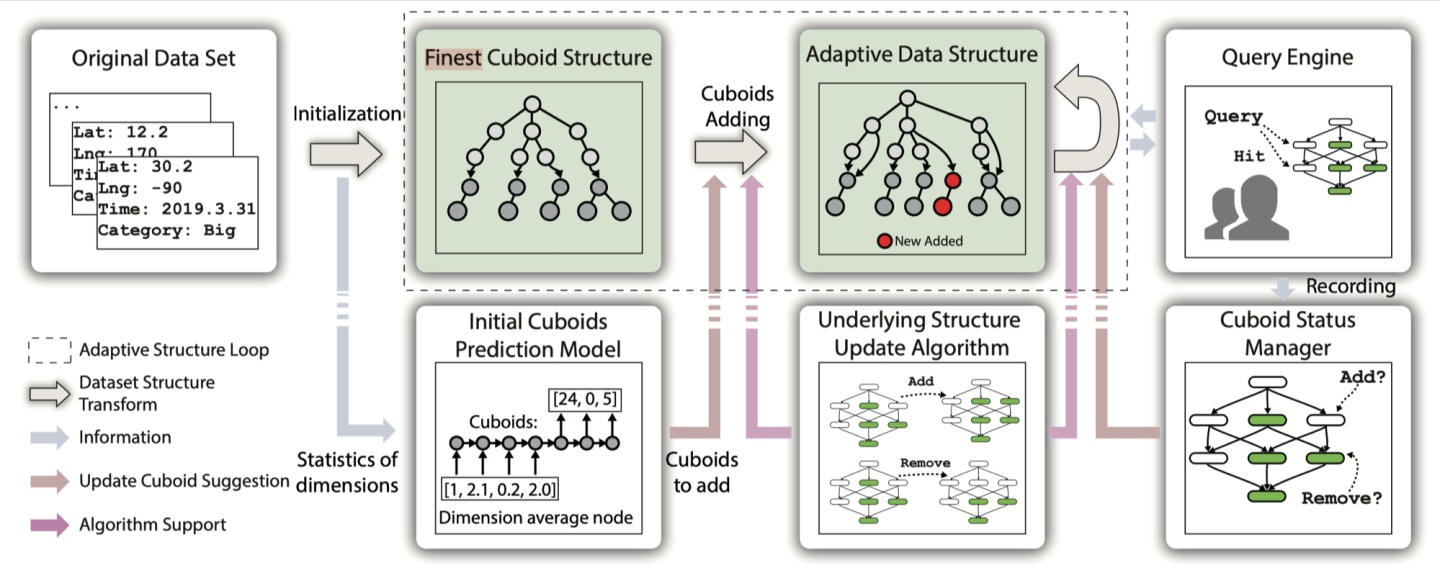
SmartCube希望基于这样的情况对目前的Data Cubes进行优化,能够形成一个有效的自适应结构,在确保查询延迟小的情况下,也能保证存储空间也尽可能小。下图是SmartCube的核心工作流,在对数据结构进行初始化后,SmartCube会持续记录用户的Query信息,并基于用户最近查询的Query列表进行数据结构的优化,从而添加需要的Cuboid并删除无用Cuboid。
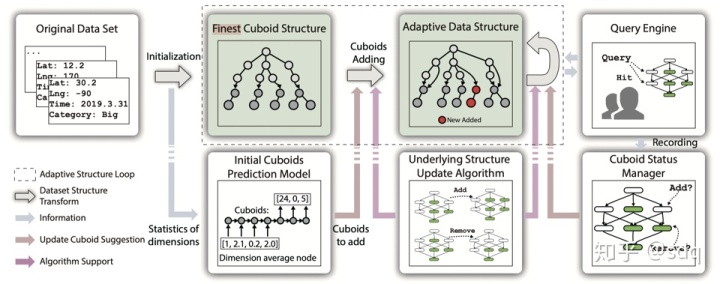
图3 SmartCube工作流
SmartCube的层次结构核心分为四个大层:最底层是空间数据层,使用四叉树(quad-tree)的方法对地理空间进行划分;第二层是类别数据层,直接根据数据中的分类进行划分;第三层是时间数据层,通过自然时间进行划分(如年、月、日);最后一层是累计运算层,是存储计算完毕的数据。下面这张图介绍了SmartCube是如何增加一个Cuboid和删除一个Cuboid的,在增加的过程中可以复用已有的运算结果。
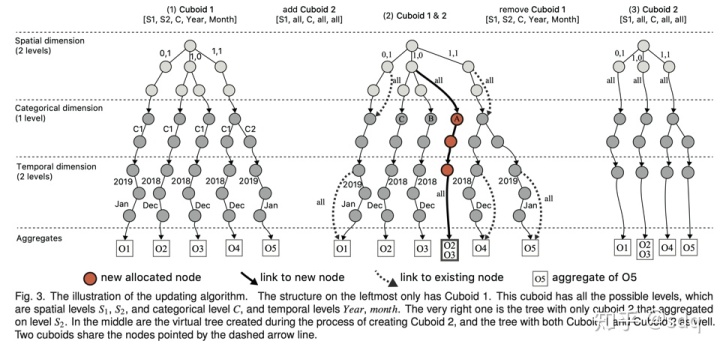
图4 SmartCube的结构更新方法
在具体的更新运算过程中,SmartCube会根据用户最新的Query和现存最近的Query来判断,是否添加一个新的Cuboid可以使得整体查询延迟降低数据可视化应用架构
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





