
本文采用Kaggle上面的Boston HousePrice数据集展示了如何建立机器学习模型的通常过程,包括以下几个阶段:
标签变量(房价)采取了对数转换,使其符合正太分布,最后从12个备选模型中[补充模型名称]选出预测效果最好的6个模型Lasso,Ridge,SVR,KernelRidge,ElasticNet,BayesianRidge分别进行加权平均集成和Stacking集成,最后发现Stacking集成效果更好,创新之处在于将Stacking集成后的数据加入原训练集中再次训练Stacking集成模型,使得模型性能再次得到改善,作为最后的预测模型,预测结果提交kaggle上后表现不错。另外受限于训练时间,超参数搜索空间小,有待改善。
数据获取
Kaggle官网提供了大量的机器学习数据集,本文从其中选择了Boston HousePrice数据集,下载地址为,下载后的数据集包括train.csv,test.csv,data_description.txt,sample_submission.csv四个文件,顾名思义train.csv为训练数据集,用于训练模型,test.csv为测试数据集,用于验证模型的准确性,data_description.txt描述train.csv字段,sample_submission.csv提供了最后提交文件的样式。其中训练集有1459条样本,81个字段,一个ID字段,一个标签SalePrice字段,测试集共有1458条样本,80个字段。
赛题给我们79个描述房屋的特征,要求我们据此预测房屋的最终售价,即对于测试集中每个房屋的ID给出对于的SalePrice字段的预测值,主要考察我们数据清洗、特征工程、模型搭建及调优等方面的技巧。本赛题是典型的回归类问题,评估指标选用的是均方根误差(RMSE),为了使得价格的高低对结果的评估有均等的影响,赛题均方根误差基于预测值和实际值分别取对数来计算。特征初步分析:
特征名称
描述
类型
单位
SalePrice
房屋售价,我们要预测的label
数值型
美元
MSSubClass
建筑的等级
类别型
MSZoning
区域分类
类别型
LotFrontage
距离街道的直线距离
数值型
英尺
LotArea
地皮面积
数值型
平方英尺
Street
街道类型
类别型
Alley
巷子类型
类别型
LotShape
房子整体形状
类别型
LandContour
平整度级别
类别型
Utilities
公共设施类型
类别型
LotConfig
房屋配置
类别型
LandSlope
倾斜度
类别型
Neighborhood
市区物理位置
类别型
数据清洗
数据清洗,是整个数据分析过程中不可缺少的一个环节,其结果质量直接关系到模型效果和最终结论。数据清洗对象主要有离群点、缺失值、重复值,以及数据转换等。
离群值
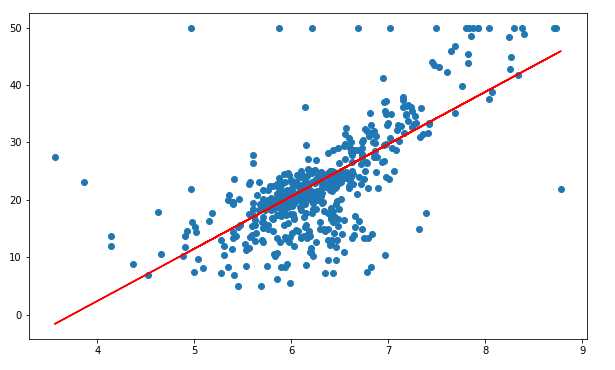
离群点通常指的是数值型变量,通过做特征GrLivArea和SalePrice散点图发现右下方存在两个异常点,因为不太可能居住面积越大,而售价却越低,因删除。
变量转换
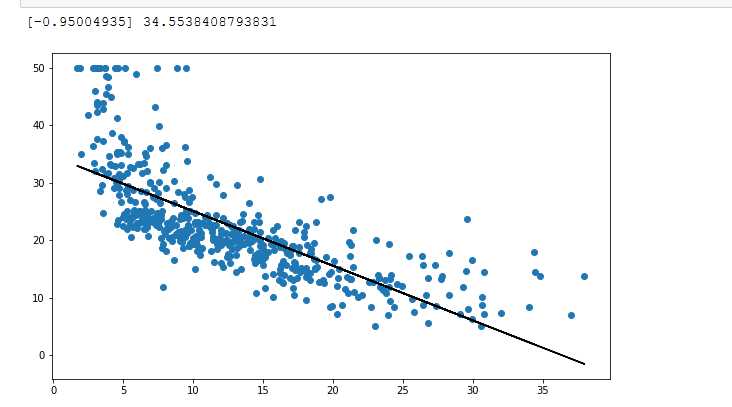
SalePrice是我们需要预测的目标变量,下面对SalePrice做一些分析。用正太分布去拟合SalePrice,同时做其正太概率图图可以发现目标变量呈现右偏态分布。
因为线性模型更适合拟合正太分布,因此需要对目标变量做log转换使其接近正态分布。做log变换后重复上面步骤发现偏度明显减小,几乎接近正态分布。
缺失值
将训练集与测试集合在一个数据框中一起处理缺失值。分析数据缺失情况,如下图所示
思考:
根据各个特征的实际意义分别进行缺失值填充。分析各特征与SalePrice的相关性,最好使用热力图。
可以看到对角线有一条白线,这代表相同的特征相关性为最高,但值得注意的是,有两个正方形小块:TotaLBsmtSF和1stFlrSF、GarageAreas和GarageCars处。这代表全部建筑面积TotaLBsmtSF与一层建筑面积1stFlrSF成强正相关,车库区域GarageAreas和车库车辆GarageCars成强正相关,那么在填补缺失值的时候就有了依据,我们可以直接删掉一个多余的特征或者使用一个填补另一个。
对于特征PoolQC,因为具有很高的缺失率,NA表示不带游泳池,根据常识中大多数房屋都不带游泳池,因此缺失值全部用None填充。
对于特征MiscFeature,Alley,Fence,FireplaceQu和MSSubClass,NA都表示没有特征所代表的实际意义,因此缺失值都用None填充。
对于特征LotFrontage,根据特征描述,因为任一房屋都非常可能与它的邻居拥有相同的相连的街道区域,因此可以按照特征Neighborhood分组后在根据其众数填充。
对于特征GarageType, GarageFinish, GarageQual , GarageCond,直接用None填充。
对于特征GarageYrBlt, GarageArea和GarageCars机器学习 过拟合,因为都是数值型变量,缺失表示没有,因此全部用0填充。
对于特征BsmtFinSF1, BsmtFinSF2, BsmtUnfSF, TotalBsmtSF, BsmtFullBath和BsmtHalfBath,都是数值型变量,缺失都表示没有,全部用0填充。
对于特征BsmtQual, BsmtCond, BsmtExposure, BsmtFinType1和BsmtFinType2,都是类别型变量,缺失表示没有basement,因此都用None填充。
对于特征MasVnrArea和MasVnrType,因为NA很可能意味着没有表层砌体饰面,因此分别用0和None填充。
对于特征MSZoning,Electrical,KitchenQual,Exterior1st,Exterior2nd和SaleType机器学习 过拟合,因为缺失率较低,全部用众数填充。
对于特征Functional,因为NA意味着typical,因此用Typ填充。
对于特征Utilities,除了两个NA和一个NoSeWa外,全部为AllPub,又NoSeWa属于训练集中,因此这个特征对于训练模型没有意义,应该删除。
编码
有些数据实际含义是类别型特征,在此处用了数值表示,需要将其转化为类别型特征,比如卖出的月份MoSold,这些变量有MSSubClass,BsmtFullBath,BsmtHalfBath,HalfBath,BedroomAbvGr,KitchenAbvGr,MoSold,YrSold,YearBuilt,YearRemodAdd,LowQualFinSF,GarageYrBlt。对SalePrice按照分类型变量进行分组后,进行特征映射。以变量MSSubClass为例,依据平均值可以将MSSubClass映射为右图所示。
依次对变量MSSubClass, MSZoning, Neighborhood, Condition1, BldgType, HouseStyle, Exterior1st, MasVnrType, ExterQual, Foundation, BsmtQual, BsmtExposure, Heating, HeatingQC, KitchenQual, Functional, FireplaceQu, GarageType, GarageFinish, PavedDrive, SaleType, SaleCondition分组后进行特征映射。
下面对特征进行编码,采用LabelEncode和OneHotEncode。先对于三个跟年相关的变量YearBuilt, YearRemodAdd, GarageYrBlt进行LabelEncoding编码,然后对于那些偏度很大的变量,先进行log1p转换后在进行OneHotEncode。接着将数据集按照原来的比例拆分为训练集和测试集,因为担心训练集和测试集中还有大量的离群点,考虑到模型的稳健性,使用robustscaler对所有数据进行缩放。
对数据完成了预处理,下面就进入了特征过程。
特征工程
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程主要包括特征创造和特征选择。
特征选择
特征选择主要有两个目的一是减少特征数量、降维,使模型泛化能力更强,二是减少过拟合,增强对特征和特征值之间的理解。选取特征主要依据以下两点:
一、特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
二、特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
基于以上两点,特征选择的常用方法有移除低方差的特征,卡方(Chi2)检验,Pearson相关系数,互信息和最大信息系数,距离相关系数,Wrapper,Embedded。
因为特征量较大,选择Embedded中基于惩罚项的特征选择法。Embedded主要思想是:使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。考虑到LASSO回归因为L1正则项同时具有特征选择和降维的作用,特别适合稀疏样本,因为前面进行编码后造成特征膨胀,样本变得稀疏,因此选择LASSO回归来筛选特征。对训练集应用LASSO回归,输出所有特征的特征重要性如下
接着筛选出特征重要性不为0的特征,如下图所示。
特征创造
基于特征重要性,可以创造一些新的特征,比如顾客可能关心的是房屋的总面积,因此可以组合新的特征。
X["TotalArea"]=X["TotalBsmtSF"]+X["1stFlrSF"]+X["2ndFlrSF"]+X["GarageArea"],同理根据原有特征描述以及实际意义,可以组合出以下新的特征。
X["TotalHouse"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"]
X["TotalHouse"]=X["TotalBsmtSF"]+X["1stFlrSF"]+X["2ndFlrSF"]
X["TotalArea"]=X["TotalBsmtSF"]+X["1stFlrSF"]+X["2ndFlrSF"]+X["GarageArea"]
X["+_TotalHouse_OverallQual"]=X["TotalHouse"]*X["OverallQual"]
X["+_GrLivArea_OverallQual"]=X["GrLivArea"]*X["OverallQual"]
X["+_oMSZoning_TotalHouse"]=X["oMSZoning"]*X["TotalHouse"]
X["+_oMSZoning_OverallQual"]=X["oMSZoning"]+X["OverallQual"]
X["+_oMSZoning_YearBuilt"]=X["oMSZoning"]+X["YearBuilt"]
X["+_oNeighborhood_TotalHouse"]=X["oNeighborhood"]*X["TotalHouse"]
X["+_oNeighborhood_OverallQual"]=X["oNeighborhood"]+X["OverallQual"]
X["+_oNeighborhood_YearBuilt"]=X["oNeighborhood"]+X["YearBuilt"]
X["+_BsmtFinSF1_OverallQual"]=X["BsmtFinSF1"]*X["OverallQual"]
X["-_oFunctional_TotalHouse"]=X["oFunctional"]*X["TotalHouse"]
X["-_oFunctional_OverallQual"]=X["oFunctional"]+X["OverallQual"]
X["-_LotArea_OverallQual"]=X["LotArea"]*X["OverallQual"]
X["-_TotalHouse_LotArea"]=X["TotalHouse"]+X["LotArea"]
X["-_oCondition1_TotalHouse"]=X["oCondition1"]*X["TotalHouse"]
X["-_oCondition1_OverallQual"]=X["oCondition1"]+X["OverallQual"]
X["Bsmt"]=X["BsmtFinSF1"]+X["BsmtFinSF2"]+X["BsmtUnfSF"]
X["Rooms"] = X["FullBath"]+X["TotRmsAbvGrd"]
X["PorchArea"]=X["OpenPorchSF"]+X["EnclosedPorch"]+X["3SsnPorch"]+X["ScreenPorch"]
X["TotalPlace"]=X["TotalBsmtSF"]+X["1stFlrSF"]+X["2ndFlrSF"]+X["GarageArea"]+["OpenPorchSF"]+X["EnclosedPorch"]+X["3SsnPorch"]+X["ScreenPorch"]
降维
前面进行了编码和特征创造后,特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。但在该案例中采用PCA技术降维选择40个主成份效果差于采用400个主成份,400接近特征维度,表明模型过拟合程度不大。
模型融合与评估
模型融合和寻找高级特征是提升机器学习性能的两个重要手段。模型融合的方法很多,比如bagging,stacking,boosting,averageweight,voting等。本文选择averageweight和stacking这两种方法。用于融合的模型有LinearRegression,Ridge,Lasso,Random Forrest,Gradient Boosting Tree,Support Vector Regression,Linear Support Vector Regression,ElasticNet,Stochastic Gradient Descent,BayesianRidge,KernelRidge,ExtraTreesRegressor共12个基础模型。
评估函数
因为该案例是典型的回归问题,对于回归问题最适合采用基于距离的的评估函数,本文采用均方误差,调用库scikit-learn中cross_val_score函数评估模型效果。cross_val_score函数采用K折交叉验证,将训练样本分割成K份,一份被保留作为验证模型的数据(test set),其他K-1份用来训练(train set)。交叉验证重复K次,每份验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测,这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,运用同样的样本可以训练模型制定的次数,在样本量不足的环境下有用,交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合,还可以从有限的数据中获取尽可能多的有效信息。应用cross_val_score计算出各模型的得分情况如
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





