
很多中小型公司认为,只有大公司才能买得起大数据驱动的解决方案,它只适合海量数据,而且价格昂贵。但是其实这已经不再是事实,有几场革命改变了这种状态。

大数据技术的成熟度
第一次革命与成熟度和质量有关。十年前,大数据技术需要一定的努力才能使它发挥作用,或者使所有的部件一起工作,这不是什么秘密。
过去有无数的故事来自开发者,他们浪费了80%的时间,试图用Spark、Hadoop、Kafka或其他技术克服愚蠢的小毛病。如今,这些技术已经变得足够可靠,学会了如何相互合作。
看到基础设施中断的几率比抓住内部bug的几率要大得多。即使是基础设施问题,在大多数情况下也可以轻描淡写地容忍,因为大多数大数据处理框架的设计都是容错的。此外,这些技术在计算上提供了稳定、强大和简单的抽象,并允许开发人员专注于业务方面的开发。
各种大数据技术
第二次革命正在发生--这些年发明了无数的开源和专有技术--Apache Pino、Delta Lake、Hudi、Presto、Clickhouse、Snowflake、Upsolver、Serverless等等等等。成千上万的开发者的创新能量和想法已经转化为大胆而优秀的解决方案。
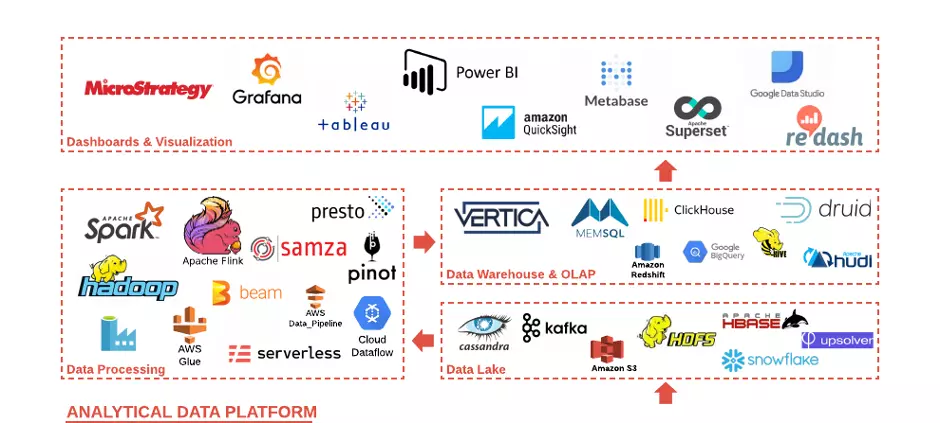

一个典型的分析数据平台(ADP)。它由四个主要层级组成。
每一层都有足够的选择,可以满足任何口味和要求。这些技术中有一半是在过去5年内出现的。
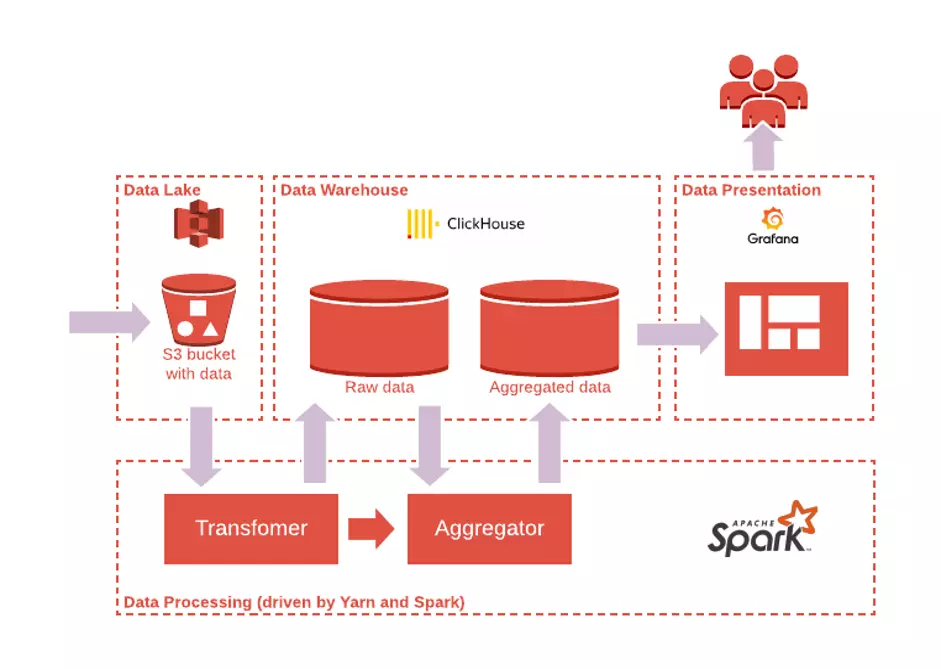
它们的重要意义在于,技术的开发意图是相互兼容。例如,典型的低成本小型ADP可能包括Apache Spark作为处理组件的基础,AWS S3或类似的作为数据湖,Clickhouse作为仓库和OLAP用于低延迟查询,Grafana用于漂亮的仪表盘(见下图)。
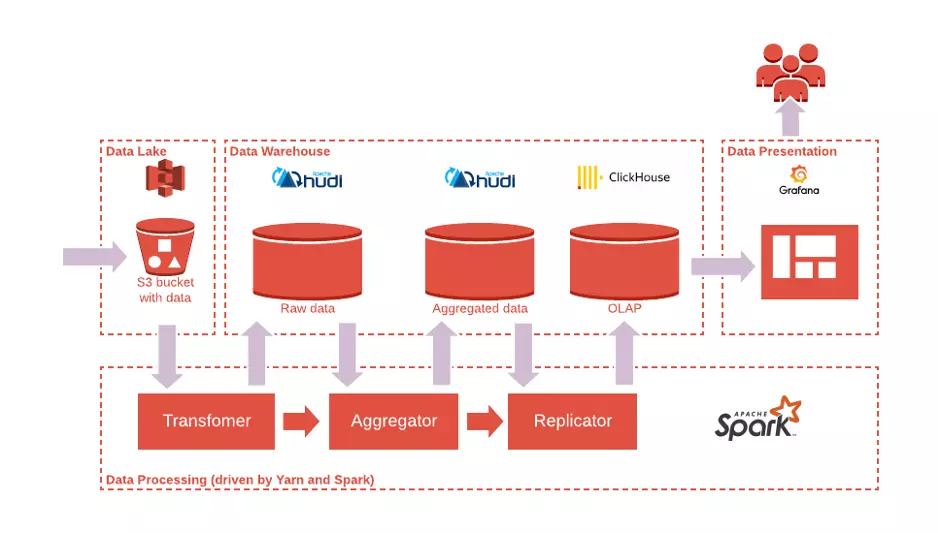
更复杂的ADP,更强的保障,可以用不同的方式组成。例如,引入Apache Hudi与S3作为数据仓库,可以保证更大的规模,而Clickhouse仍然是为了低延迟访问聚合数据(见下图)。
成本效益
第三次革命是由云制造的。云服务成为真正的游戏规则改变者。它们将大数据作为一个现成的平台(大数据即服务)来解决,让开发者专注于功能开发,让云来关心基础设施。
下图是另一个ADP的例子,它利用无服务器技术的力量,从存储、处理到演示层。它有同样的设计理念,但技术被AWS管理服务所取代。
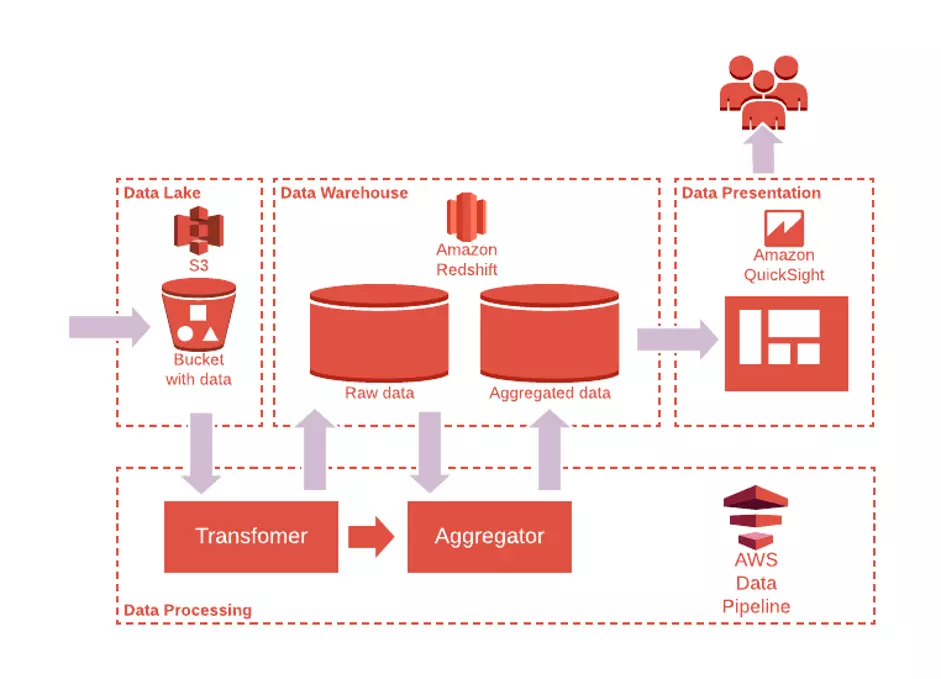
值得一说的是,这里的AWS只是一个例子,同样的ADP也可以建立在任何其他云服务商之上。
开发者可以选择特定的技术和无服务器的程度。无服务器的程度越高,它的可组合性就越强在线培训解决方案,然而,作为一个缺点,它被供应商锁定的程度就越高。被锁定在特定的云提供商和无服务器堆栈上的解决方案可能会有一个快速的上市时间跑道。在无服务器技术之间做出明智的选择可以使解决方案具有成本效益。
不过这个方案对于初创公司来说并不是很有用,因为他们往往会利用典型的10万美金的云积分,在AWS、GCP和Azure之间跳跃是很普通的生活方式。这个事实必须提前澄清,必须提出更多的云无关技术来代替。通常,工程师会区分以下成本:
我们来逐一解决这些问题。
开发成本
云技术无疑简化了工程工作,它有几个方面的积极影响。
首先是架构和设计决策。无服务器堆栈提供了一套丰富的模式和可重用的组件,为解决方案的架构提供了一个坚实而一致的基础。
只有一个问题可能会拖慢设计阶段的进度--大数据技术的本质是分布式的,所以相关解决方案在设计时必须考虑到可能出现的故障和中断,以便能够确保数据的可用性和一致性。作为一种奖励,解决方案需要较少的努力才能被扩展出来。
第二个是集成和端到端测试。无服务器堆栈允许创建隔离的沙箱,发挥、测试、解决问题,因此减少了开发回环和时间。
另一个优势是,云实施了解决方案部署过程的自动化。不用说这个功能是任何成功团队的必备属性。
维护成本
云提供商宣称要解决的主要目标之一是减少监控和维持生产环境的工作量。他们试图建立某种几乎零devops参与的理想抽象。不过现实情况有些不同。关于这个想法在线培训解决方案,通常维护还是需要一些努力的。下表重点介绍了最主要的几种。
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。




