
在上一节的学习中,我们主要认识了什么是深度学习,深度学习有哪些成功的应用以及深度学习的优点与缺点,总体来说就是让我们深度的了解何为深度学习,就如文字开头所说的“人们往往为技术而兴奋。但深度学习是企业用来解决实际问题的工具。仅此而已,毋庸夸大,也无需贬低。”
对于还不了解什么是深度学习的朋友可以先阅读《干货|简单易懂的深度学习指南,不服来辩!(一)》学习一下。
本篇文章我们不在对深度学习的基础做讲解了,而是介绍Cloudera数据和机器学习的统一平台,并提供六个实用技巧,帮助您的组织开始进行深度学习。
话不多说,开始我们今天的学习吧!
Cloudera 的深度学习
Cloudera是数据和机器学习的统一平台。使用Cloudera,您可以深度学习您的数据,而不是相反。
对于当今复杂的技术环境,企业需要选择和灵活性。 Cloudera 具有多种方式来训练和部署深度学习模型,无需新的孤岛或数据迁移。
Cloudera 数据科学工作台
Cloudera 数据科学工作台(CDSW)可实现快速,简单,安全的自助数据科学。缺 省条件下就是安全及合规的,支持完整的 Cloudera 认证、授权、加密和治理。
CDSW 为数据科学家提供了一个基于浏览器的开发环境,适用于 Python,R 和 Scala。用户可以在自定义设置中下载和实验最新的库和框架,并轻松地与同行共 享项目。该软件包括内置的调度,监控和邮件警报。
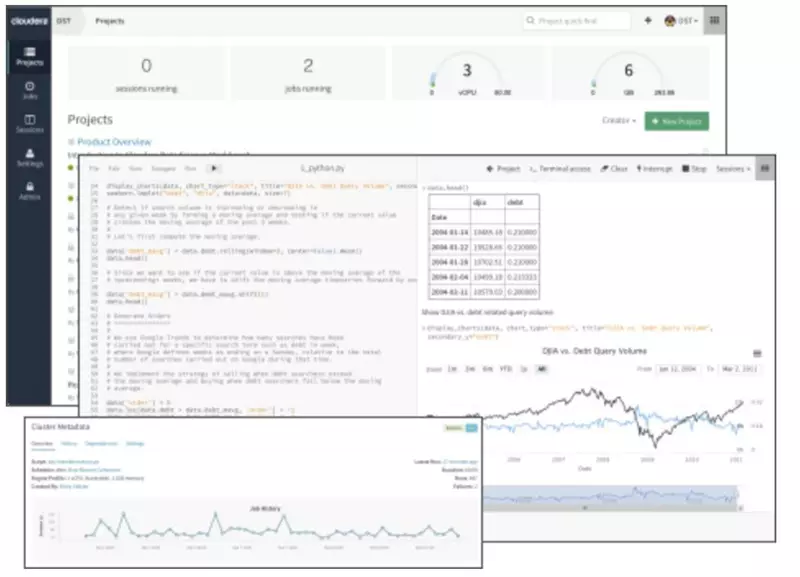
图:Cloudera 数据科学工作台
最新的 CDSW 版本支持 GPU 的设备。 GPU 是加速计算密集型工作负载的专用处理器。 GPU 特别适合于深度学习模型的训练步骤。 CDSW 使数据科学家可以将传统硬件用于数据准备和发现等任务,并在 GPU 加速的机器上训练深度学习模型。
CDSW 用户共享可用的 GPU 资源。用户请求特定数量的 GPU 实例,最多可达一个节点上的总数。 CDSW在运行期间将GPU分配给作业。项目可以使用隔离版本的库,甚至通过 CDSW 的可扩展引擎功能,使用不同的 CUDA 和 cuDNN 版本。
使用CDSW的数据科学家可以使用任何具有Python,R或Scala API的深度学习框架,包 括 TensorFlow,Keras,Theano,Microsoft Cognitive Toolkit(CNTK),Caffe,PyTorch,DL4J,Apache MXNet,Torch 和 BigDL。
如何开始进行深度学习
在最近的数据科学和机器学习 Hype Cycle 报告中,Gartner 将深度学习定位成“膨胀中期望的高峰”:
在这个过份狂热和不现实的预测阶段中,技术领导者的广泛宣传活动取得了一些成功,但更多的是失败,因为技术被推向极限。唯一赚钱的企业是会议组织者和 杂志出版社。
关于深度学习的炒作给企业架构师同时带来机会和风险。一方面,广为传播的成 功案例增加了高管的兴趣寻求深度学习获得竞争优势。另一方面,过度的热情可 能导致组织机构投资昂贵而无用,或将股价拉低,因而从长远角度,削弱了从深度学习中获利的能力。

与大多数新技术一样,快速变化的标准使投资具有挑战性。谷歌发布了用于深度 学习的 TensorFlow 软件并在 2015 年 11 月开放源代码;在几个月内,它成为开源生态系统中最为积极开发的机器学习项目。自从谷歌发布以来,亚马逊,微软和英特尔都已经发布了深度学习的开源项目。虽然 TensorFlow 是当今最受数据科学家欢迎的深度学习框架,但是我们并不确认它会永久保持这种状态。
鉴于深度学习的力量和潜力,我们有几个务实的提示。
专注于解决业务问题。谷歌,微软和百度并没有因为深度学习很酷,或者因为咨询顾问告诉他们创新是重要的,而成为深度学习的重磅力量。他们这样做是因为他们有紧迫的业务问题,深度学习为解决这个问题提供了一个办法。
深度学习也可能是您企业机构的正确工具。但是,如果您没有仔细地定义业务问题, 概括出捕获和管理数据的策略,并先尝试使用简单的技术,您可能会构建一个没 人会用的深度学习功能。
仔细选择试点项目。如果您的机构没有接触过深度学习,计划的长期成功可能取决于您最初几个项目的结果。深度学习最有可能对以下项目产生影响:
这些问题通常具有上述我们认为的深度学习的属性:高基数结果,维度和未标记 的数据。
尝试用深度学习改进现有的以常规技术为基础的模型,大多数时间都会产生令人 失望的结果。为了获得更好的结果,数据科学家将向建模过程引入新的数据。例如深度学习 图像, 医院通过添加医疗专业人员所记录的患者数据来提高预测再住院模型的准确性。
首先整理数据。大概很有冲动让你的团队一头扎进训练深度学习的模型吧。这种做法可能有助于学习。但请记住,在每一个深度学习的成功故事背后,都有一个数据的成功故事。
成功的深度学习应用基于三个不同流程的定义数据流:
如何设计这些流程将决定您的应用的成功。例如,尽管可以将大型数据集复制到 一个离线平台进行初始训练,但是对于模型的更新,因为要不断重复执行,而可 能变得成本高昂。在今天快节奏的业务中,模型的频繁更新是机器学习所有分支 的常态。除非您允许这样做深度学习 图像,否则您的项目可能会成为高维护费用“孤儿”。
同样,除非您的团队已经想清楚如何使用一个深度学习模型来进行推论,否则您 很有可能会创建一个没有人用的伟大模型。使用该应用的业务可能需要具有服务 级别保证的低延迟推论。您的深度学习项目规划要考虑这一点,否则项目将失败。
拥抱开源。数据科学家更喜欢开源软件。所有最广泛使用
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





