
许多企业数据科学团队正在使用Cloudera的机器学习平台进行模型探索和培训,包括使用Tensorflow机器学习损失函数,PyTorch等创建深度学习模型。但是,训练深度学习模型通常是一个耗时的过程,因此采用GPU和分布式模型训练方法来加快训练速度。
这是我们关于在Cloudera机器学习平台上进行深度学习的分布式模型训练的博客系列的第一篇文章,其中包括Cloudera数据科学工作台(CDSW)和Cloudera机器学习(CML),这是为云构建的新一代CDSW。在下文中,为简单起见,我们仅指“CML”,且此文的内容也适用于CDSW安装。
在这篇文章中,我们将介绍:
深度学习的分布式模型训练的技术基础
通常使用随机梯度后裔(SGD)算法训练深度学习模型。对于SGD的每次迭代,我们将从训练集中采样一个小批量,将其输入到训练模型中,计算观察值和实际值的损失函数的梯度,并更新模型参数(或权重)。众所周知,SGD迭代必须顺序执行,因此不可能通过并行化迭代来加快训练过程。但是,由于使用CIFAR10或IMAGENET等许多常用模型处理一次迭代要花费很长时间,即使使用最先进的GPU,我们仍然可以尝试并行化前馈计算以及每次迭代中的梯度计算以加快速度加快模型训练过程。
在实践中,我们将训练数据的微型批次分为几个部分,例如4、8、16等(在本文中,我们将使用术语“子批次”来指代这些拆分的部分),并且每个培训工人分一个批次。然后,培训人员分别使用子批进行前馈、梯度计算和模型更新,就像在整体培训模式中一样。在这些步骤之后,将调用称为模型平均的过程,对参与培训的所有工作人员的模型参数求平均,以便在新的培训迭代开始时使模型参数完全相同。然后,新一轮的训练迭代又从数据采样和拆分步骤开始。
形式上,上面的分布式模型训练过程的模型平均的一般思想可以使用以下伪代码表示。
# Suppose w0 is the initial global parameters, K is the number of workers, T is the overall iterating number, ftk(wt) is the output of the kth worker under the parameters wt at time t, and lr is the learning rate. FOR t = 0, 1, …, T-1 DO Read the current model parameters wt Stochastically sample a batch of data itk Compute the stochastic gradients ftk(wt) at each worker Accumulate all of the gradients of K workers Update the global parameters wt+1=wt-ltKftk(wt) END FOR
如上所示,在每次迭代结束时,我们一直等到模型参数达到一致性为止,因此可以在新的迭代开始之前使模型同步。这种方法称为同步SGD,这是我们将在本文中考虑的方法。(另一种方法是异步SGD,在异步SGD中,模型参数存储在称为参数服务器的集中位置,并且工作线程在每次迭代结束时自行独立于参数服务器进行更新,而与其他工作线程的状态无关。同步SGD、异步SGD的整体训练速度不会受到单个“慢”工人的影响,但是,如果训练集群中的GPU处理速度大致相同(通常是这种情况),在实际情况中显然很“慢”,因此,同步SGD在ML应用领域中是一个不错的选择。)
上述算法中的每个工作人员在训练过程中还具有模型参数的完整副本,只有训练数据分配给不同的工作人员。这种方法称为数据并行性,这是我们将在此处考虑的方法。另一种称为模型并行性的方法也可以拆分模型参数。模型并行性的优点是能够训练大于内存容量(主内存或GPU内存)的模型。但是,如果模型的大小小于内存容量,则数据并行性将更加高效,因为在每次迭代的前馈期间它不需要工作人员之间的通信。
“参数服务器”对比“MPIAllreduce”
许多深度学习框架,例如Tensorflow,PyTorch和Horovod,都支持分布式模型训练。它们在模型参数的平均或同步方式上有很大不同。当前,有两种模型同步方法:1)基于参数服务器,和2)MPI Allreduce。
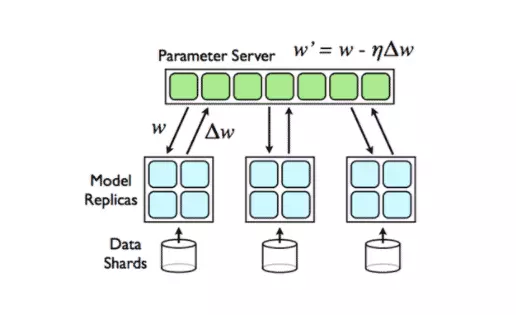
上图显示了基于参数服务器的体系结构。在这种方法中,计算节点被划分为工作程序和参数服务器。每个工作人员“拥有”一部分数据和工作负载,并且参数服务器共同维护全局共享的参数(使用参数服务器扩展分布式机器学习)。在每次迭代的开始,工作人员会提取完整的模型参数副本,并在迭代结束时将新更新的模型推回参数服务器。对于同步SGD,参数服务器将平均所有工作人员推送的模型参数,从而创建更新的“全局”模型供工作人员在下一次迭代开始时提取。
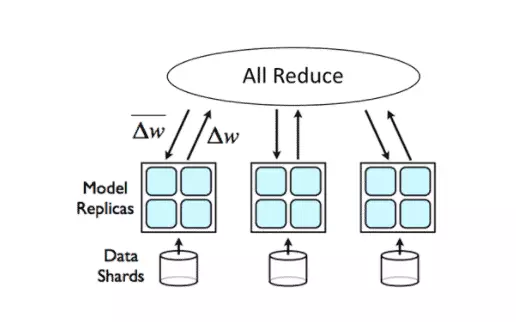
另一方面,MPI Allreduce方法不需要一组专用服务器来存储参数。取而代之的是,它利用环减少(将HPC技术带入深度学习)算法和MPI(消息传递接口)API来实现模型同步。对于由N个节点组成的模型训练集群,模型参数将被划分为N个块,并且参与环归约算法的每个节点都将与其两个对等节点进行2∗(N−1)次通信。因此,从理论上讲,模型平均时间仅与模型的大小有关,而与节点的数量无关。在此通信期间,节点发送和接收数据缓冲区的块。在前N-1次迭代中,将接收到的值添加到节点缓冲区中的值。在第二次N-1迭代中,接收到的值替换了保存在节点缓冲区中的值。MPI API是由高性能计算社区开发的,用于实现模型参数同步,而Open MPI是由学术,研究和行业合作伙伴组成的联盟开发和维护的,广泛使用的MPI实现之一。
关于与MPI Allreduce方法相比基于参数服务器的方法的性能,在Uber和MXNet中的基准测试结果表明,在小数量的节点(8-64)上,MPI Allreduce的性能优于参数服务器(Horovod:快速而轻松在TensorFlow中进行分布式深度学习,并通过MPI AllReduce扩展MXNet分布式培训)。
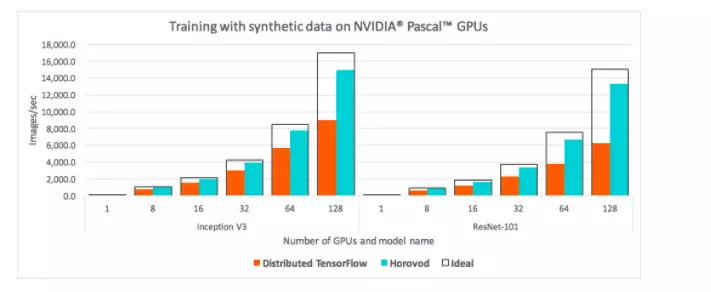
上图是Uber的基准测试,参数服务器(Tensorflow本机)与MPI Allreduce(Horovod)的结果,当在不同数量的NVIDIA Pascal GPU上运行分布式培训作业时,将每秒处理的图像与标准分布式TensorFlow和Horovod进行比较适用于基于25GbE TCP的Inception V3和ResNet-101 TensorFlow模型。同时,下面的MXNet基准测试结果还显示,即使参数服务器和辅助服务器的数量均为8,MPI Allreduce方法的性能仍高于参数服务器方法。
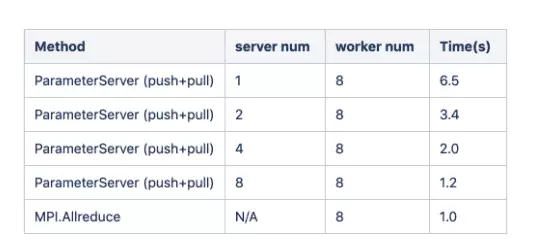
从性能数据中,我们可以得出以下结论(由MPI AllReduce扩展MXNet分布式培训):1)MPI Allreduce方法不需要额外的服务器节点,并且可以获得比基于参数服务器的方法更好的性能。同步SGD多节点训练。(在基于参数服务器的方法中,如果配置不当,则不足的服务器将成为网络带宽的热点。)2)此外,MPI Allreduce方法更易于硬件部署。(在基于参数服务器的方法中,需要精心计算服务器:工人比率的配置,并且该比率不是固定的(取决于拓扑和网络带宽)。)
传统上,Tensorflow支持基于参数服务器的方法,而PyTorch和Horovod支持MPI Allreduce方法。但是,从r1.3开始,Tensorflow也开始支持MPI Allreduce方法(在r1.4中具有实验支持)。
注意:基于参数服务器的方法能够支持同步和异步SGD,例如Tensorflow。据我们所知,MPI Allreduce方法的所有当前实现仅支持同步SGD。
有了这些基础知识,让我们继续进行分布式模型训练的编程部分,同时使用基于参数服务器的参数和MPI Allreduce方法,并了解如何在CML中使用这两种方法。
使用CML中基于参数服务器的方法进行编程
本节将概述用CML编写基于参数服务器的分布式模型训练代码的概述。我们将使用Tensorflow本机分布式API和CML的分布式API(cdsw.launch_worker)进行演示。
首先机器学习损失函数,分布式Tensorflow中的每个参数服务器或工作程序都是一个Python进程。因此,我们很自然地使用CML工作器(或容器)来表示TF参数服务器或TF工作器,并使用cdsw.launch_workers(…)函数在主CML会话中调用这些CML工作器。在cdsw.launch_workers(…)中,我们还可以为TF参数服务器和TF工作者指定不同的Python程序文件。然后,主要的CML会话需要收集每个容器的主机名或IP地址,并将它们发送给所有CML子工作程序,以创建集群规范(tf.train.ClusterSpec)。在CML中,实际上有许多方法可以获取每个子工作者的IP地址,我们将介绍一种使用新的await_workers函数的方法,该函数在CML Docker引擎V10中正式可用。
await_workers函数用于等待其他由其会话ID指定的CML容器的启动。 await_workers的返回值是一个Python字典,带有一个项的键名是ip_address,并带有其IP地址。下面的代码显示了如何在CML主会话中使用cdsw_await_workers。请注意,如果某些容器在指定的时间(例如,以下代码为60秒)后无法启动,则await_workers的返回值将导致键名失败的项,其中包含失败人员的会话ID。
# CML main session import cdsw workers = cdsw.launch_workers(NUM_WORKERS, cpu=0.5, memory=2, script=”...”) worker_ids = [worker["id"] for worker in workers] running_workers = cdsw.await_workers(worker_ids, wait_for_completion=False, timeout_seconds=60) worker_ips = [worker["ip_address"] for worker in \ running_workers["workers"]]
在获取并分配所有TF参数服务器和TF工作程序的IP地址之后,每个工作程序都需要构造实例。在下面的代码段中,PS1:PORT1代表第一个TF参数服务器进程的IP地址和端口号,PS2:PORT2代表第二个TF参数服务器进程的IP地址和端口号,而WORKER1:PORT1代表第二个TF参数服务器进程的IP地址和端口号。 第一个TF工作程序的IP地址和端口号等
cluster = tf.train.ClusterSpec({"ps": ["PS1:PORT1","PS2:PORT2",...],
"worker": ["WORKER1:PORT1","WORKER2:PORT2",...]})
server = tf.train.Server(cluster, job_name="PS or WORKER",
task_index=NUM)对于TF参数服务器容器,请调用server.join()等待,直到所有其他参数服务器进程和辅助进程都加入集群。
server.join()
对于TF工作人员,所有的建模和培训代码都需要进行编程。如果您使用数据并行性,那么建模部分实际上与整体式Tensorflow程序相同。但是,该训练代码与整体Tensorflow程序至少有2个明显的不同。
optimizer = tf.train.AdamOptimizer(learning_rate=...) sr_optim = tf.train.SyncReplicasOptimizer( optimizer, replicas_to_aggregate=NUM_WORKER, total_num_replicas=NUM_WORKER)
注意:在最新版本的Tensorflow中不推荐使用tf.train.Supervisor,现在建议使用tf.train.MonitoredTrainingSession代替tf.train.Supervisor。
每次我们编写分布式Tensorflow代码时,重复上述上述编程过程不仅很耗时,而且容易出错。因此,我们将它们包装在一个函数(cdsw_tensorflow_utils.run_cluster)中,该函数随此文章一起发布,从而使整个过程自动化,因此数据科学家仅需指定参数服务器,工作程序和培训代码的数量即可。可以在此处找到包含该功能的脚本。以下程序演示了如何使用cdsw_tensorflow_utils.run_cluster创建分布式Tensorflow集群。
cluster_spec, session_addr = cdsw_tensorflow_utils.run_cluster( n_workers=n_workers, n_ps=n_ps, cpu=0.5, memory=2, worker_script="train.py")
文件train.py是模型定义和训练代码所在的地方,它看起来很像单片Tensorflow代码。train.py的结构如下:
import sys, time
import tensorflow as tf
# config model training parameters
batch_size = 100
learning_rate = 0.0005
training_epochs = 20
# load data set
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# Define the run() function with the following arguments
# And this function will be invoked within CML API
def run(cluster, server, task_index):
# Specify cluster and device in tf.device() function
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % task_index,
cluster=cluster)):
# Count the number of updates
global_step = tf.get_variable(
'global_step',
[],
initializer = tf.constant_initializer(0),
trainable = False)
# Model definition
…
# Define a tf.train.Supervisor instance
# and use it to start model training
sv = tf.train.Supervisor(is_chief=(task_index == 0),
global_step=global_step,
init_op=init_op)
with sv.prepare_or_wait_for_session(server.target) as sess:
# Model training code
…
# Stop the Supervisor instance
sv.stop()下面的屏幕快照显示了使用上面介绍的CML内置API在CML上平均异步模型的分布式模型训练程序的执行过程。

来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





