
1.项目说明
通过对上海餐饮数据的分析,选择相对较好的餐饮类型和地段开店
2.项目具体要求 3.实现思路:
1.根据上海餐饮数据,有’口味’,’环境’,’服务’,’人均消费’这字段,因此可以计算’口味’,’性价比’,’人均消费’三个指标来计算得分,以此为依据来选择餐饮类型,评判标准是人均消费适中,性价比和口味得分较高。
可以先对数据进行清洗和查看,去除异常数据,然后筛选计算三个指标,对三个指标进行0-1标准化,然后用bokeh绘制图表。
2.选出开店的菜系之后再选择开店做好的地理位置,需要考虑消费人口,交通状况,餐饮热度,竞争大小,因此可以使用以下四个指标:
人口密度指标、道路密度指标、餐饮热度指标、同类竞品指标。这几个指标都需要使用QGIS进行地理空间分析得到。
评价方法:
人口密度指标 → 得分越高越好
道路密度指标 → 得分越高越好
餐饮热度指标 → 得分越高越好
同类竞品指标 → 得分越低越好
综合指标 = 人口密度指标*0.4 + 餐饮热度指标*0.3 + 道路密度指标*0.2 +同类竞品指标*0.1
使用上海人口网格图作为基础数据计算人口密度,道路密度,结合上海餐饮数据的餐饮店的经纬度计算餐饮密度和同类竞品密度。
对四个指标进行标注化处理之后加权平均得到综合指标,综合排序选出top10的区域作为备选区域。
可以使用bokeh根据经纬度绘制方形图绘制上海市地图,利用颜色和大小将备选区域标出。
4.实现过程:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
from bokeh.io import output_notebook
output_notebook()
# 导入notebook绘图模块
from bokeh.plotting import figure,show
from bokeh.models import ColumnDataSource
# 导入图表绘制、图标展示模块
# 导入ColumnDataSource模块
#加载数据
data =pd.read_excel(r'D:\IT\python数据分析师\项目7\上海餐饮数据.xlsx',sheet_name = 0)
#数据筛选和清洗
data1 = data[data!=0].dropna()[['类别','口味','环境','服务','人均消费']]
#计算获得性价比字段
data1['性价比'] = (data1['口味']+data1['环境']+data1['服务'])/data1['人均消费']
#创建函数,生成箱型图,查看数据分布情况
def f_boxplot(data,*cols):
fig,axs = plt.subplots(1,3,figsize = (10,4))
n = 0
for col in cols:
data.boxplot(column = col,ax = axs[n])
n +=1
#生成'口味','性价比','人均消费'数据的箱型图
f_boxplot(data1,'口味','性价比','人均消费')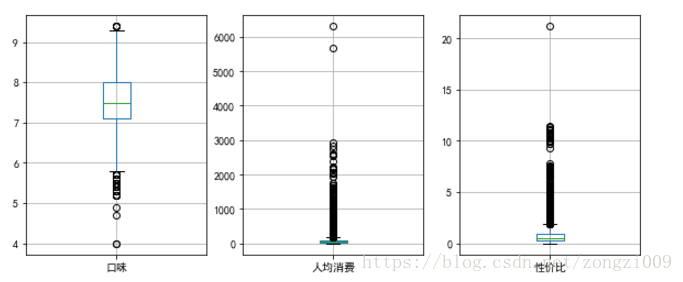
#创建函数,对清洗异常数据,并标准化
def dataProcess(data,col):
q1 = data[col].quantile(q = 0.25)
q3 = data[col].quantile(q = 0.75)
iqr = q3-q1
t1 = q1-3*iqr
t2 = q3+3*iqr
data_c = data[(data[col]>t1)&(data[col]'类别').mean()
data_g[col+'_nor'] = (data_g[col]-data_g[col].min())/(data_g[col].max()-data_g[col].min())
return data_g
#筛选得到'口味','性价比','人均消费'的单独数据
data_kw = data1[['类别','口味']]
data_xf = data1[['类别','人均消费']]
data_xjb = data1[['类别','性价比']]
#调用函数'口味','性价比','人均消费'数据进行异常值清洗,并标准化
data_kw_score = dataProcess(data_kw,'口味')
data_xjb_score = dataProcess(data_xjb,'性价比')
data_xf_score = dataProcess(data_xf,'人均消费')
#将各个指标数据连接
data_zb = data_kw_score.join(data_xjb_score).join(data_xf_score)
#制作散点图,x轴为“人均消费”,y轴为“性价比得分”,点的大小为“口味得分”
#导入bokeh绘图的模块
from bokeh.models import HoverTool
from bokeh.models.annotations import BoxAnnotation
from bokeh.layouts import gridplot
#绘图数据准备
data_zb1 = data_zb[['人均消费','口味_nor','性价比_nor','人均消费_nor']].sort_values('人均消费')
data_zb1.columns=['consume_mean','kw_score','xjb_score','xf_score'] #重新命名各字段
data_zb1.index.name = 'category'
data_zb1['size'] = data_zb1['kw_score']*40 #创建size ,散点图的大小,以口味得分为维度
index = data_zb1.index.tolist() #用index作为柱状图横坐标类型
source = ColumnDataSource(data = data_zb1)
#设置标签内容
hover = HoverTool(tooltips =[('餐饮类型:','@category'),
('人均消费:','@consume_mean'),
('性价比得分:','@xjb_score'),
('口味得分:','@kw_score')])
#创建绘图空间
p1 = figure(plot_width = 800,height = 300,title = '餐饮类型得分情况',toolbar_location = 'above',
tools=[hover,'box_select,wheel_zoom,reset,crosshair'])
#绘制餐饮类型得分情况散点图
p1.circle(x='consume_mean',y= 'xjb_score',source = source,color = 'orangered',fill_alpha = 0.5,size = 'size')
#绘制人均消费中间价位区间
price_box = BoxAnnotation(left=40,right=80,fill_color = 'gray',fill_alpha = 0.2)
p1.add_layout(price_box)
p1.grid.grid_line_dash = [10,4]
#绘制口味得分柱状图
p2 = figure(x_range = index,plot_width = 800,height = 300,title = '口味得分',
tools = [hover,'box_select,wheel_zoom,reset,crosshair'])
p2.vbar(x ='category',bottom = 0,width = 0.9,top = 'kw_score',source = source,color = 'skyblue',alpha= 0.7)
p2.grid.grid_line_dash = [10,4]
#绘制人均消费得分柱状图
p3 = figure(x_range = p2.x_range ,plot_width = 800,height = 300,title = '人均消费得分', #x_range设置为p2一致,图表联动
tools = [hover,'box_select,wheel_zoom,reset,crosshair'])
p3.vbar(x ='category',bottom = 0,width = 0.9,top = 'xf_score',source = source,color = 'olive',alpha= 0.4)
p3.grid.grid_line_dash = [10,4]
p = gridplot([[p1],[p2],[p3]]) #组合图表
show(p)
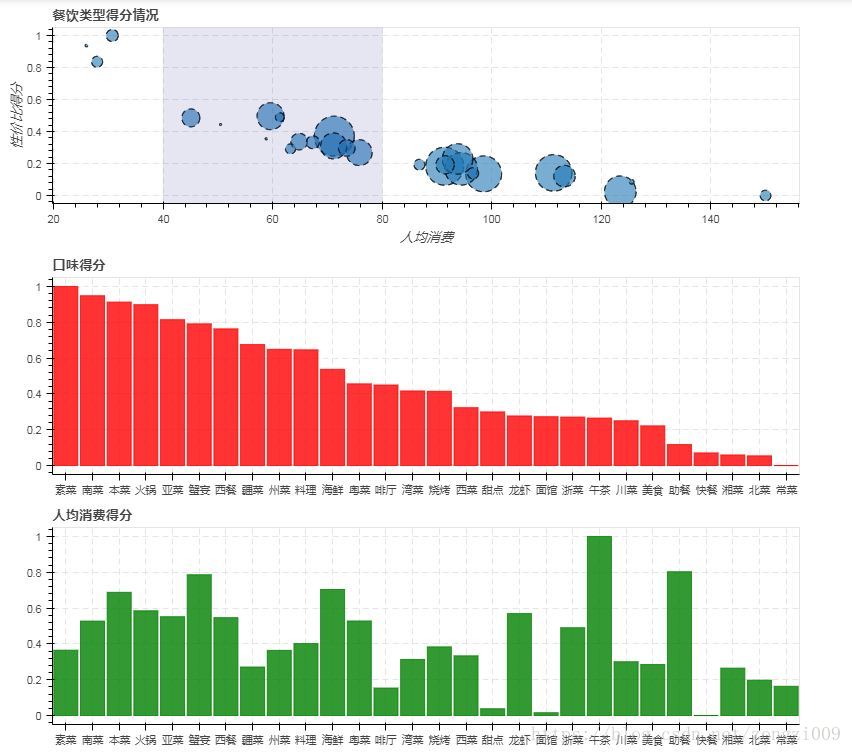
说明:
1.这里创建两个函数完成数据的查看和清洗,第一个函数f_boxplot(data,*cols)传入餐饮基础数据和字段,循环完成传入字段的箱型图绘制。
第二个函数dataProcess(data,col)传入餐饮基础数据和字段名,对该字段进行数据清洗,去除异常值,并根据餐饮类型进行分组求均值,
2.对每一个餐饮类型的均值进行标准化处理。返回的数据用于数据可视化绘图。
bokeh是python中基于网页的绘图工具库,图像以html保存,并不是基于pandas数据结构的绘图工具库,因此不能直接使用pandas生成的数据进行绘图,需要转化成bokeh绘图所需格式的数据。同时其绘图方法可和matplotlib以及seaborn也有比较大的差别,绘图比较麻烦,但是有更大的灵活性,并且可以设置图形联动以及丰富的可视化交互。
3.使用bokeh绘图餐饮类型的’性价比’散点图,’口味’和’人均消费’的柱状图,散点图中使用’口味’得分来设置散点大小上海餐饮数据分析,并用矩形标注何时的价格区间,这样可以得到几个何时餐饮类型, ‘口味’和’人均消费’的柱状图按照人均消费从小到大的顺序绘制每种餐饮类型的柱状图,可以明显看出在符合价格区间的集中餐饮类型中’素菜’的口味得分是最高的。因此可以选择’素菜’作为开店的餐饮类型。
#读取经过空间分析后计算得到的人口密度指标、道路密度指标、餐饮热度指标、同类竞品指标数据
df_net = pd.read_excel(r'D:\IT\python数据分析师\项目7\项目7-2.xlsx',sheet_name = 0)
df_net.fillna(0,inplace = True)
df_net.columns = ['population','roadLenght','cy_count','sc_count','lng','lat']
#将人口密度指标、道路密度指标、餐饮热度指标、同类竞品指标数据数据进行标准化
#人口密度指标 → 得分越高越好
#道路密度指标 → 得分越高越好
#餐饮热度指标 → 得分越高越好
#同类竞品指标 → 得分越低越好
df_net['population_nor'] = (df_net['population']-df_net['population'].min())/(df_net['population'].max()-df_net['population'].min())
df_net['roadLenght_nor'] = (df_net['roadLenght']-df_net['roadLenght'].min())/(df_net['roadLenght'].max()-df_net['roadLenght'].min())
df_net['cy_nor'] = (df_net['cy_count']-df_net['cy_count'].min())/(df_net['cy_count'].max()-df_net['cy_count'].min())
df_net['sc_nor'] = (df_net['sc_count'].max()-df_net['sc_count'])/(df_net['sc_count'].max()-df_net[来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





