
t-SNE实践——sklearn教程
t-SNE是一种集降维与可视化于一体的技术,它是基于SNE可视化的改进,解决了SNE在可视化后样本分布拥挤、边界不明显的特点,是目前最好的降维可视化手段。
关于t-SNE的历史和原理详见从SNE到t-SNE再到LargeVis。
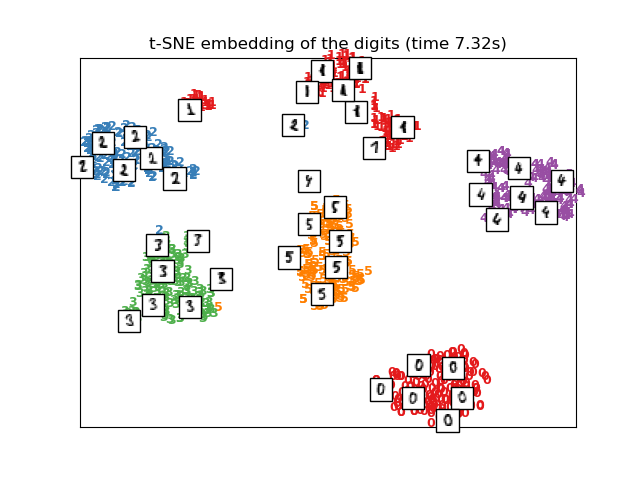
代码见下面例一
TSNE的参数
函数参数表:
parameters描述
n_components
嵌入空间的维度
perpexity
混乱度,表示t-SNE优化过程中考虑邻近点的多少,默认为30,建议取值在5到50之间
early_exaggeration
表示嵌入空间簇间距的大小,默认为12,该值越大,可视化后的簇间距越大
learning_rate
学习率,表示梯度下降的快慢高维数据可视化,默认为200,建议取值在10到1000之间
n_iter
迭代次数,默认为1000,自定义设置时应保证大于250
min_grad_norm
如果梯度小于该值高维数据可视化,则停止优化。默认为1e-7
metric
表示向量间距离度量的方式,默认是欧氏距离。如果是precomputed,则输入X是计算好的距离矩阵。也可以是自定义的距离度量函数。
init
初始化,默认为random。取值为random为随机初始化,取值为pca为利用PCA进行初始化(常用),取值为numpy数组时必须shape=(n_samples, n_components)
verbose
是否打印优化信息,取值0或1,默认为0=>不打印信息。打印的信息为:近邻点数量、耗时、σσ、KL散度、误差等
random_state
随机数种子,整数或RandomState对象
method
两种优化方法:barnets_hut和exact。第一种耗时O(NlogN),第二种耗时O(N^2)但是误差小,同时第二种方法不能用于百万级样本
angle
当method=barnets_hut时,该参数有用,用于均衡效率与误差,默认值为0.5,该值越大,效率越高&误差越大,否则反之。当该值在0.2-0.8之间时,无变化。
返回对象的属性表:
Atrtributes描述
embedding_
嵌入后的向量
kl_divergence_
KL散度
n_iter_
迭代的轮数
t-distributed Stochastic Neighbor Embedding(t-SNE)
t-SNE可降样本点间的相似度关系转化为概率:在原空间(高维空间)中转化为基于高斯分布的概率;在嵌入空间(二维空间)中转化为基于t分布的概率。这使得t-SNE不仅可以关注局部(SNE只关注相邻点之间的相似度映射而忽略了全局之间的相似度映射,使得可视化后的边界不明显),还关注全局,使可视化效果更好(簇内不会过于集中,簇间边界明显)。
目标函数:原空间与嵌入空间样本分布之间的KL散度。
优化算法:梯度下降。
注意问题:KL散度作目标函数是非凸的,故可能需要多次初始化以防止陷入局部次优解。
t-SNE的缺点:
t-SNE的优化
在优化t-SNE方面,有很多技巧。下面5个参数会影响t-SNE的可视化效果:
PS:一个形象展示t-SNE优化技巧的网站How to Use t-SNE Effectively.
代码 例一
import numpy as np
import matplotlib.pyplot as plt
from sklearn import manifold, datasets
digits = datasets.load_digits(n_class=6)
X, y = digits.data, digits.target
n_samples, n_features = X.shape
'''显示原始数据'''
n = 20 # 每行20个数字,每列20个数字
img = np.zeros((10 * n, 10 * n))
for i in range(n):
ix = 10 * i + 1
for j in range(n):
iy = 10 * j + 1
img[ix:ix + 8, iy:iy + 8] = X[i * n + j].reshape((8, 8))
plt.figure(figsize=(8, 8))
plt.imshow(img, cmap=plt.cm.binary)
plt.xticks([])
plt.yticks([])
plt.show()
'''t-SNE'''
tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)
X_tsne = tsne.fit_transform(X)
print("Org data dimension is {}.
Embedded data dimension is {}".format(X.shape[-1], X_tsne.shape[-1]))
'''嵌入空间可视化'''
x_min, x_max = X_tsne.min(0), X_tsne.max(0)
X_norm = (X_tsne - x_min) / (x_max - x_min) # 归一化
plt.figure(figsize=(8, 8))
for i in range(X_norm.shape[0]):
plt.text(X_norm[i, 0], X_norm[i, 1], str(y[i]), color=plt.cm.Set1(y[i]),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.show()
t-SNE高维数据可视化(python)
t-SNE(t-distributedstochastic neighbor embedding)是目前最为流行的一种高维数据降维的算法。在大数据的时代,数据不仅越来越大,而且也变得越来越复杂,数据维度的转化也在惊人的增加,例如,一组图像的维度就是该图像的像素个数,其范围从数千到数百万。
对计算机而言,处理高维数据绝对没问题,但是人类能感知的确只有三个维度,因此很有必要将高维数据可视化的展现出来。那么如何将数据集从一个任意维度的降维到二维或三维呢。T-SNE就是一种数据降维的算法,其成立的前提是基于这样的假设:尽管现实世界中的许多数据集是嵌入在高维空间中,但是都具有很低的内在维度。也就是说高维数据经过降维后,在低维状态下更能显示出其本质特性。这就是流行学习的基本思想,也称为非线性降维。
关于t-SNE的详细介绍可以参考:
下面就展示一下如何使用t-SNE算法可视化sklearn库中的手写字体数据集。
import numpy as np
import sklearn
from sklearn.manifold import TSNE
from sklearn.datasets import load_digits
# Random state.
RS = 20150101
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import matplotlib
# We import seaborn to make nice plots.
import seaborn as sns
sns.set_style('darkgrid')
sns.set_palette('muted')
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
digits = load_digits()
# We first reorder the data points according to the handwritten numbers.
X = np.vstack([digits.data[digits.target==i]
for i in ran来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





