

作者 | IAN JOHNSON
编译 | CDA数据分析师
尽管对于可视化高维数据非常有用,但t-SNE图有时可能是神秘的或误导性的。通过探索它在简单情况下的行为方式,我们可以学习如何更有效地使用它。
一种用于探索高维数据的流行方法是在2008年由t-SNE引入的 van der Maaten和Hinton]。该技术在机器学习领域已经变得普遍,因为它具有几乎神奇的能力,可以从具有数百甚至数千维度的数据创建引人注目的双维“地图”。虽然令人印象深刻,但这些图像很容易被误读。本说明的目的是防止一些常见的误读。
我们将通过一系列简单的例子来说明t-SNE图可以和不可以显示什么。t-SNE技术确实很有用 - 但前提是你知道如何解释它。
在潜入之前:如果您之前没有遇到过t-SNE,那么您需要了解它背后的数学知识。目标是在高维空间中获取一组点,并在较低维空间(通常是2D平面)中找到这些点的忠实表示。该算法是非线性的,并且适应底层数据,在不同区域上执行不同的变换。这些差异可能是混乱的主要原因。
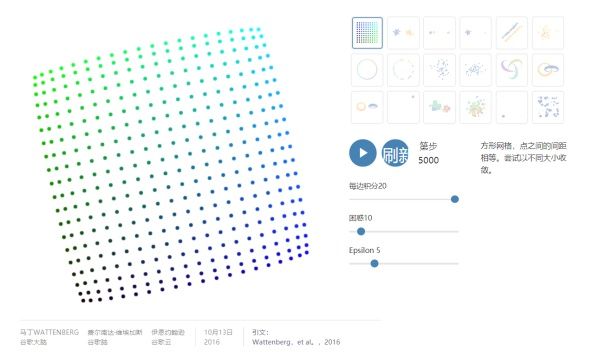
t-SNE的第二个特征是可调参数,“困惑”,它(松散地)说明如何在数据的本地和全局方面之间平衡注意力。在某种意义上,该参数是关于每个点具有的近邻的数量的猜测。困惑值对得到的图像具有复杂的影响。原始论文说:“SNE的表现对于困惑的变化是相当强大的,典型的值在5到50之间。”但这个故事比那更加微妙。从t-SNE中获取最大收益可能意味着分析具有不同困惑的多个图。
这不是复杂的结束。例如,t-SNE算法并不总是在连续运行中产生类似的输出,并且存在与优化过程相关的附加超参数。
1.那些超参数真的很重要
让我们从t-SNE的“hello world”开始:两个广泛分离的集群的数据集。为了使事情尽可能简单,我们将考虑2D平面中的聚类,如左图所示。(为清楚起见,两个簇是彩色编码的。)右边的图显示了五个不同的困惑值的t-SNE图。
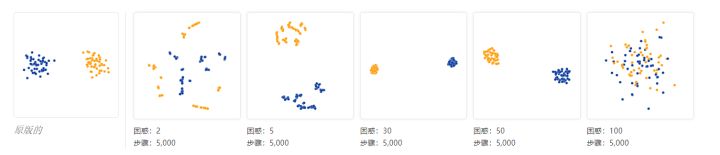
由van der Maaten和Hinton建议的范围(5 - 50)中的困惑值,图表确实显示了这些簇,尽管形状非常不同。在这个范围之外,事情变得有点奇怪。由于困惑2,局部变化占主导地位。具有合并的簇的困惑图像100示出了陷阱:为了使算法正确地操作,困惑确实应该小于点的数量。否则,实现可能会产生意外行为。
上面的每个图都是5000次迭代,学习率(通常称为“epsilon”)为10,并且已经达到了步骤5,000的稳定点。这些价值观有多大区别?根据我们的经验,最重要的是迭代直到达到稳定的配置。

上面的图像显示了困惑30的五个不同的运行。前四个在稳定之前停止。在10,20,60和120步之后,您可以看到具有看似群集的一维甚至点状图像的布局。如果你看到一个奇怪的“捏”形状的t-SNE图,那么这个过程很可能太早停止了。不幸的是,没有固定数量的步骤可以产生稳定的结果。不同的数据集可能需要不同的迭代次数才能收敛。
另一个自然的问题是,具有相同超参数的不同运行是否产生相同的结果。在这个简单的双集群示例中,以及我们讨论的大多数其他示例中,多次运行给出了相同的全局形状。但是,某些数据集在不同的运行中会产生明显不同的图表; 我们稍后会给出一个例子。
从现在开始,除非另有说明,否则我们将显示5,000次迭代的结果。这通常足以在本文的(相对较小的)例子中收敛。然而,我们会继续表现出一系列的困惑,因为这似乎在每种情况下都会产生很大的不同。
2. t-SNE图中的簇大小没有任何意义
到现在为止还挺好。但是如果这两个集群有不同的标准偏差,那么大小不同呢?(按尺寸,我们指的是边界框测量值,而不是点数。)下面是平面中高斯混合物的t-SNE图,其中一个是另一个的10倍。

令人惊讶的是,这两个簇在t-SNE图中看起来大小相同。这是怎么回事?t-SNE算法使其“距离”概念适应数据集中的区域密度变化。结果,它自然地扩展了密集的集群,并且收缩了稀疏集群,使集群大小缩小。需要明确的是,这与任何降维技术都会扭曲距离的普通事实不同。(毕竟,在这个例子中高维数据可视化,所有数据都是二维的开始。)相反,密度均衡是通过设计发生的,并且是t-SNE的可预测特征。
然而,底线是你无法在t-SNE图中看到聚类的相对大小。
3.集群之间的距离可能没有任何意义
集群之间的距离怎么样?下图显示了三个高斯分别为50分,一对分别是另一对的5倍。

在困惑50时,该图给出了对全局几何的良好感觉。对于较低的茫然值,群集看起来是等距的。当困惑度为100时,我们看到全局几何结构很好,但其中一个集群看起来错误地比其他集群小得多。由于困惑50在这个例子中给了我们一个好的画面,如果我们想看到全局几何,我们是否总能将困惑设置为50?
可悲的是没有。如果我们为每个群集添加更多点,则必须增加困难以进行补偿。以下是三个高斯群集的t-SNE图,每个群集有200个点,而不是50个。现在没有一个试验困惑度值给出了良好的结果。

看到全球几何需要微调困惑是个坏消息。真实世界的数据可能会有多个具有不同数量元素的集群。可能没有一个困惑值可以捕获所有集群的距离 - 遗憾的是,困惑是一个全局参数。解决这个问题可能是未来研究的一个有趣领域。
基本信息是t-SNE图中分离良好的簇之间的距离可能没有任何意义。
4.随机噪声并不总是随机的。
一个经典的陷阱是认为你看到的是真正随机数据的模式。当你看到它时,识别噪音是一项关键技能,但要建立正确的直觉需要时间。关于t-SNE的一个棘手的事情是,它抛出了很多现有的直觉。下图显示了真实的随机数据,从100维的单位高斯分布中抽取了500个点。左图是前两个坐标上的投影。
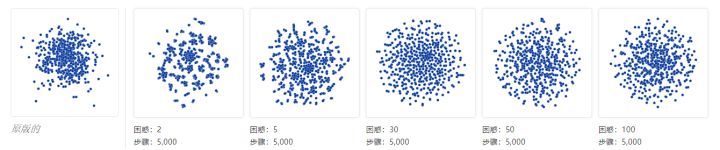
困惑2的情节似乎表现出戏剧性的集群。如果你正在调整困惑以在数据中显示结构,你可能会认为你已经中了大奖。
当然,因为我们知道点云是随机生成的,所以它没有统计上有意义的集群:那些“团块”没有意义。如果回顾前面的例子,低茫然度值通常会导致这种分布。将这些团块识别为随机噪声是读取t-SNE图的重要部分。
不过有其他一些有趣的东西,这可能是t-SNE的胜利。起初,困惑30的情节根本看起来不像高斯分布:云的不同区域之间只存在微小的密度差异,并且这些点看起来可疑地均匀分布。事实上,这些特征是关于高维正态分布的有用的东西,它们非常接近球体上的均匀分布:均匀分布,点之间的间距大致相等。从这个角度来看,t-SNE图比任何线性投影都准确。
5.你有时可以看到一些形状
数据以完全对称的方式分发很少见。让我们看一下50维的轴对齐高斯分布,其中坐标i的标准偏差是1 / i。也就是说,我们正在研究一个长椭圆形的点云。
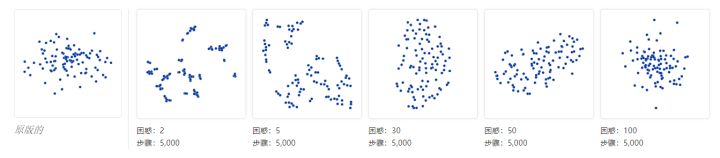
对于足够高的困惑值,细长的形状易于阅读。另一方面,在低度困惑的情况下,局部效应和无意义的“聚集”成为焦点。更加极端的形状也会出现,但同样只有正确的困惑。例如,这里是两个75个点的集群高维数据可视化,每个集群在2D中,以平行线排列,带有一点噪声。
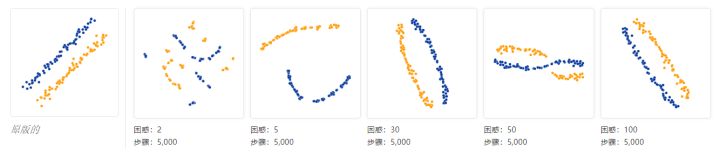
对于一定程度的困惑,长簇看起来接近正确,这是令人放心的。
然而,即使在最好的情况下,也存在一种微妙的失真:在t-SNE图中线条略微向外弯曲。原因在于,像往常一样,t-SNE倾向于扩展更密集的数据区域。由于群集的中间周围的空白空间少于末端,因此算法会放大它们。
6.对于拓扑,您可能需要多个绘图
有时您可以从t-SNE图中读取拓扑信息,但这通常需要多个困惑的视图。最简单的拓扑属性之一是遏制。下图显示了50维空间中的两组75个点。两者都是从以原点为中心的对称高斯分布中采样的,但其中一个比另一个分散50倍。“小”分布实际上包含在大的分布中。
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





