

作者 | 图特摩斯科技创始人闭雨哲
来源| AI科技大本营(ID:rgznai100)
前言
图特摩斯科技(Thutmose)基于自研的图形数据库AbutionGraph(实时多维数据存储与计算一体化的高可用平台)为核心,构建AI智能认知中台(认知图谱平台)来实现业务衔接,它不仅是一个能力中台,也是一个战略中台。
作为能力平台,Thutmose认知中台向下作为整合者融合大数据与人工智能技术能力,向上作为方案提供者赋能业务,上下资源的整合即体现出中台的价值.作为战略中台,不仅要实现AI技术的可落地方案,更要实现能力的复用,通过“业务场景复制”来进行业务扩张,取得规模化效应。
总体而言,Thutmose构建的知识图谱认知中台并非只是面向能力领域,而是基于大数据与AI能力来面向领域业务输出价值。
中台在数字化转型中的作用
在已过去2019年,“中台”的浪潮之风呼啸而来,伴随着大数据、人工智能等技术的发展,数字化转型成为了不少传统企业的“救命稻草”。各种企业数字化转型的解决方案也随之应声而出,一线互联网企业和传统巨头纷纷入局,数据中台,业务中台,技术中台……众多中台名词不断涌现。
人们已经习惯了从信息技术角度来理解和开展数字化转型,许多企业并没有意识到这一轮数字化转型的战略性、系统性和长期性,仅仅重视引入各种设备、机器人、IT系统,认为有了自动化、智能化的装备、生产链、销售渠道就是实现了数字化转型。其实不然,如企业真的要做产业互联网、数字化转型,可能PaaS比SaaS更重要。据埃森哲去年披露的中国企业数字化转型的报告指出:中国企业数字化转型成功的企业比例只占7%,中台并不能代表企业数字化转型的需求,中台它是个重要的事,但是它也不是数字化全部的事。
根本原因在于,“数据”的价值正在越来越受到企业的重视,数据正在成为企业最核心以及最重要的生产资料,成为决定企业业务转型的关键因素。企业需要一个源源不断的输出数据服务,数据洞察的能力源泉。即,数字化的本质是网络聚合思维,以数据驱动、网络效应为主,在辅以算法模型,形成一个统一的数字化智能平台数据业务化,支撑企业数据的处理和业务的敏捷创新。
构建以知识图谱为核心的数据中台
虽然数据中台的概念才火不过一年,但是关于数据中台的解释却有很大不同,各有道理,但如果我问你数据中台与数据仓库、数据平台、数据湖等有什么本质区别,你不一定说得清楚。
《思考|谈谈数据管理的原则》的作者说过,数据中台起码有3个特征:业务化、服务化及开放化。我认为基于知识图谱的中台还应具备知识化的特征,业务是根本,服务是手段,知识化是能力,开放是价值。这4点是传统的数据平台很难兼顾的,也是我们较于其他中台的优化之处。
一、数据知识化
用知识的相互作用来表现数据
传统数据库中的数据是静态的,每一条数据代表一个事件,我们首先要做的是将这些数据知识化,如图所示,把每一个事件关联起来,做成一个反映真实世界的事件动态变化的认知图谱。

人工智能技术实现了从感知到认知的能力跨越,最重要的具备像人类大脑对知识的关联、联想和探索能力,而知识图谱是目前最趋近与人类大脑思维本质的AI 底层技术,亦是人工智能技术最重要的基础设施。Thutmose在大数据存储之上创新再创新,将传统数据表映射成图谱结构,再将图谱存储升级成实时图谱,再赋予实时图谱动态的认知能力,最后升级成多维认知图谱,它是一个包含多方面信息的领域画像,这是我们的技术平台AbutionGraph所支持的知识化能力。
企业可通过多维感知的实体、关系、事件挖掘实现对客观世界的逻辑认知,是计算机能够实现推理、预测等类似人类思考能力的关键。这也是物联网时代“万物互联”的数据表达形式,每一条数据知识化后都将会获得语境感知,增强的处理能力和更好的感应能力。将这些原本静止的内容物(人、物、信息)抽象到知识图谱中,你将会得到一个集合十亿甚至万亿连接的行业网络,企业的自身“价值”也将来自网络不断增加的“内容物的数量”与网络能表征“信息的丰富程度”。这些连接将会创造前所未有的机会并带来更加丰富的体验和前所未有的经济发展机遇。
二、数据业务化
用业务驱动数据的建设
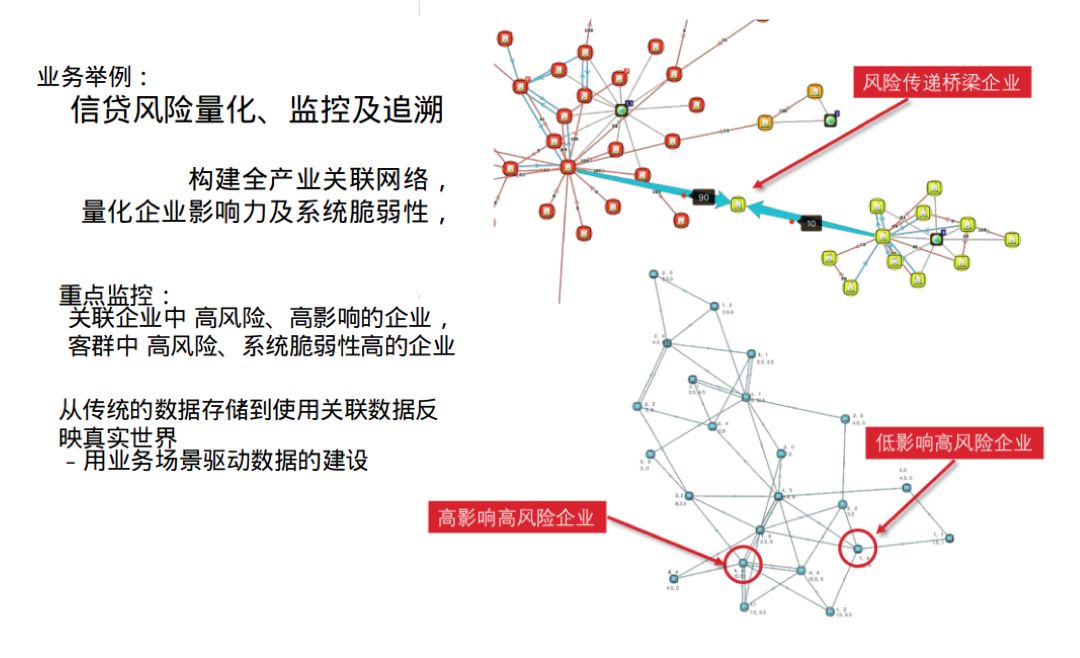
为什么仅使用数据仓库不能作为数据中台?因为数据仓库只是实现了数据的平台化,平台化就是把那些有共性的资源、有共性的能力合并在一起,然后把那些面向客户的价值独立出来,这样的话,基于这个数据库专业的人做专业的事情,不揉在一块了,更加的清晰,这就是平台化的思路,当然了,仅仅依靠一个单一的数据存储进行数据分析已不能很好解决问题。如上图所示,使用数据仓库可以存储事件数据,但不能以网络的思维反映事件数据业务化,传统方法想要达到相同效果的业务可能需要付出大得多的开发周期,质量也很难得到提升。当业务的进化使得系统需要升级时,即是业务场景驱动数据建设的时候。
一个优秀的数据中台底座对企业实现业务敏捷是非常重要的,尤其在大型企业中,要想在增量市场逐渐向存量市场转变的环境中生存,需要应对不断变化的市场环境,出路唯有——创新,产品创新、业务创新、服务创新、销售创新。敏捷高效地支持这些创新,就是企业数字化转型的真正需求。
基于赋能业务创新的思路,图特摩斯科技研发的AbutionAI技术栈核心架构结合了数据仓库,时间序列数据库和图形矩阵存储的创意,并加入大规模实时处理与计算架构,数据存储是我们平台的共性,也是基础,是我们重点设计的部分。与一般的ETL流程不同,图形存储AbutionGraph通过实时大数据计算框架Flink/Kafka/MQ/Spark将各方的数据资源汇聚在一起(E)后,直接使用自身的框架存储与计算架构实现业务指标的的计算+存储(TL),简化了数据转化与计算环节。
AbutionGraph还将大多数目前热门的大数据与人工智能技术壁垒打通,提供一个通用的数据存储+数据计算+数据分析的一体化平台,这是业务化平台的基石,您可以依据业务按需使用满足的技术组合进行实现分层建模,最终实现数据的共享,整个过程就是柔性数据处理"流水线",从而满足不断丰富、变化的数据分析、挖掘类需求,使您可以非常高效的完成业务模型开发,同时减少技术研发与维护成本。
基于AbutionGraph的数据中台可以允许不同的业务隔离、不同的用户隔离,依据业务您可以轻松在上层构建一个时序的图谱、传统的图谱、实时的图谱、离线的图谱、可融合的多个图谱..不同业务的图谱天然的隔离在一个平台上,AbutionGraph一个强大的功能允许知识融合(数据合并),将天然隔离的业务图(eg. 订单图,好友图,历史消费图等)以不影响各自存储的情况下,做多图合并查询、多图路径搜索,得出多个业务数据间的关联结果,就像是在知识图谱领域的多表关联查询,通过查询,我们可以轻松的知道张三身边的好友的消费状况等,深入了解您的用户并不断优化您的服务,就是在创造价值。
业务的创新升级离不开技术的更新换代,比如企业以前使用大数据技术Spark做某项业务指标分析,在分钟内可以得到分析报告,但是现在有另一个大数据技术Flink可在多秒内得到分析报告,这对于实时分析与洞察类业务可带来的业务创新空间是相当乐观的,值得企业去做技术升级,也是基于这样的企业数字化本质需求,为其提供分析和判断能能力,就是所谓的中台。所以,在数字化转型中需要先建设一个数字化的智能平台,这个平台理所当然需要有一个功能强大的技术核心进行构建,然后再把SaaS(企业应用软件)里面的数据做一些整合和创新应用,从而实现业务智能。
需求还是原来的需求,我们通过技术创新与优化落地,现在可以把它实现的更好。这是大数据与人工智能技术的成熟带给我们最切实的赋能,需求没变,但是衡量标准变了。这就叫业务化,用业务驱动数据的建设,这是数据中台希望达到的目标。
三、数据服务化
将数据以共享的方式服务于多项业务
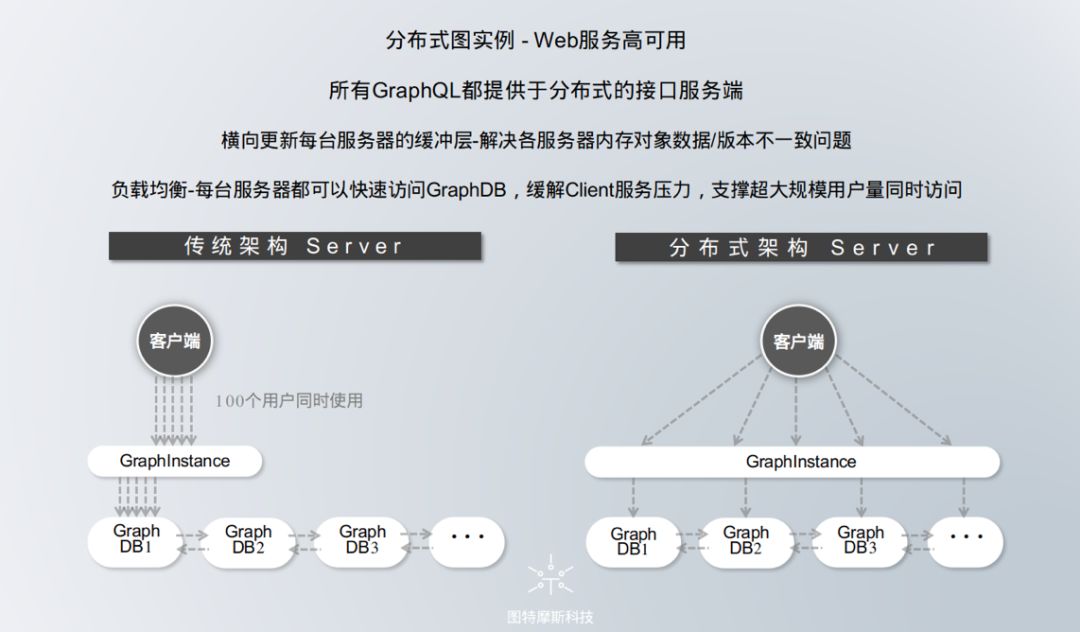
服务化的概念最初是为了解决代码功能的使用问题,以及应对单体应用无法承载不断发展和演进的后台接口服务。随着各项业务的落地,单体应用不断裂变成成百上千个包含独立业务服务的垂直应用,数据支撑服务成为企业发展中的一个难题。为这些应用提供能够被共享使用的数据,在前端被业务人员或者其他机器快速方便的使用或调用,减少重复开发和维护的工作量及随之带来的风险,同时能够让系统各模块解藕,减少关联风险,这些是数据服务化的作用。
图特摩斯科技负责人认为,基于知识图谱的数据中台平台应具备解决以下用户痛点的能力:
1.代码重复
各部门或各个业务线都是自己通过DAO写SQL访问数据库来存取相同的数据,这无形中就导致了代码的重复。应开发适配的接口,让相同功能的代码得以复用,避免重复开发。
2.复杂性扩散
随着并发量的越来越高,数据的访问成了瓶颈,需要加入缓存机制来降低数据库的读压力,由于没有统一的服务层,各个业务线都需要关注缓存的引入导致的复杂性。这就需要我们去做一个统一的分布式缓存,不管业务线怎样,按需挂取。一个成熟的数据中台应该隐藏掉缓存开发,较少复杂性,变成一个通用接口,开发者实现业务逻辑的时候只需记住自己放了什么缓存,用完后删除释放资源。当用户量上升时,可动态的增加缓存服务器,实现动态扩容,原有的缓存也会重新均衡到每台服务器上。
3.分布式服务层-高可用
目前市场化的图数据库都只实现了数据的分布式存储,却没有实现服务的分布式。以较知名的图数据库JanusGraph来说,所有的数据访问都通过集群中的某台机器进行使用,当多用户频繁查询与写入数据,就可能导致该台机器资源过度使用而宕机,服务就无法使用了。也有些开发者通过嫁接Ngix来制造负载均衡,这其实只是把单个服务变成了很多的单个服务,Cache层并没有分布式,即图实例没有共享。举个简单的例子:
张三在机器A上新建了Graph1,在机器B上李四是不知道数据库中有了Graph1的,需要张三告诉李四,我建了个Graph1,你初始化一下图连接吧,这时,李四才可以使用到这个Graph1。
4.复杂SQL质量得不到保障,业务相互影响
对于业务线数据的抽取调用,一般通过DAO访问数据库,在图形数据查询中,有专门面向图形数据的查询语义,常见的如Gremlin和Cypher。不论是普通的SQL还是GraphQL,不同的开发人员实现的质量和效率可能会大有不同,比如业务线A写了一个全表扫描的SQL,导致数据库的 CPU100%,影响的不只是一个业务线,而是所有的业务线都会受影响。
基于此问题,我们对不同的graph赋予不同的资源使用率,合理的分配每个graph在总资源中的占比。比如集群总CPU内核为20个,数据图graph1承载的业务量较大,我们赋予它可以使用15个内核,数据图graph2承载的业务量较小,我们赋予它可以使用2个内核。给我们带来的好处是,2个grpah同时执行数据查询使不会相互影响,也不会导致数据库的 CPU100%。
就服务化来说,我们不应该谈到SQL层,而是应该尽量简化的提供到接口层,不管你使用的开发语言是什么,只要数据能够被共享使用,在前端被业务人员或者其他机器快速方便的使用或调用,这就是好的服务化。
5.疯狂的DB耦合-知识融合,单图结构越来越大
DB耦合是针对传统数据库而言的,面对传统数据库我们可以做多表关联操作,典型的,通过join 数据表来实现各自业务线的一些业务逻辑。
这样的话,业务线A的table与table-A耦合在了一起,业务线B的table与table-B耦合在了一起,业务线C的table与table-C耦合在了一起,结果就是:table,table-A,table-B,table-C都耦合在了一起。
这是传统数据库的缺陷,但却是图形数据库所不具备的优点。因其天生的不支持跨图关联查询,要实现多业务线关联,就要将所有有关联的这些A/B/C数据表都放在一个大图里,随着数据量的越来越大,业务线 ABC 的数据库便很难垂直拆分开,造成过度的知识融合。所以我们希望在不影响各个业务数据图存储的情况下,对多种业务图的关联合并查询,就像传统数据库的表关联查询一样,以解决知识融合遇到的问题。
四、开放化
吸纳建议,融入更多优秀开源方案,使受众面更广
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





