
IBM SPSS Statistics的K均值聚类分析,是一种采用欧式距离作为分类指标的迭代聚类分析方法。其优点是操作简单,运算速度快,但由于其聚类原理是将欧式距离相似的数据归为一个类别,因此需采用连续型的数据变量。
接下来,我们通过实例来演示一下K均值聚类分析。
一、数据准备
本例使用的是一组店铺的销售数据,包含客流量、销售额与销售量三个连续型变量。我们会使用到以上三个连续变量对数据个案进行K均值聚类分析。
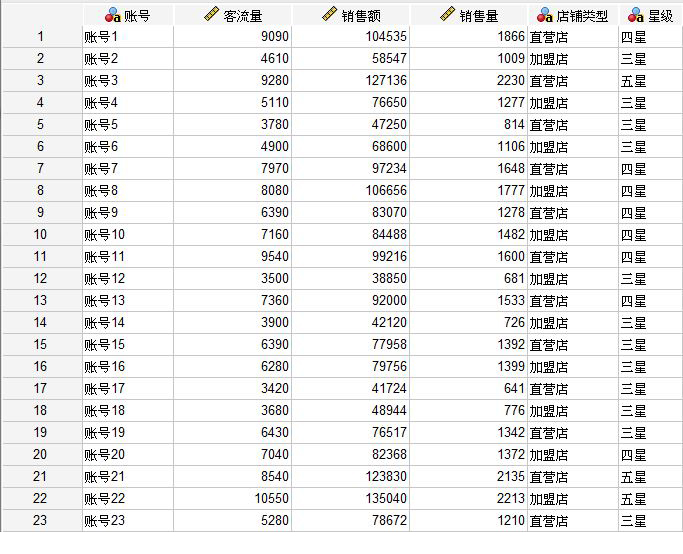
图1:店铺数据
二、K均值聚类参数设置
K均值聚类分析是SPSS分类分析法中的一种,由于其运算的快速性,也被称为“快速聚类”。
图2:K均值聚类
如图3所示,K均值聚类分析设置面板包含变量、聚类中心等设置参数。
图3:参数设置面板
按照数据分析目的,如图4所示,我们需将客流量、销售额、销售量添加为变量,然后再单击右侧的“保存”按钮,保存“聚类成员”与“与聚类中心的距离”两个新变量。
图4:变量与保存设置
接着,打开“迭代”设置怎么运用spss进行数据分析,设置最大迭代次数,一般按照默认即可,如果默认次数过小,应尽量调大。
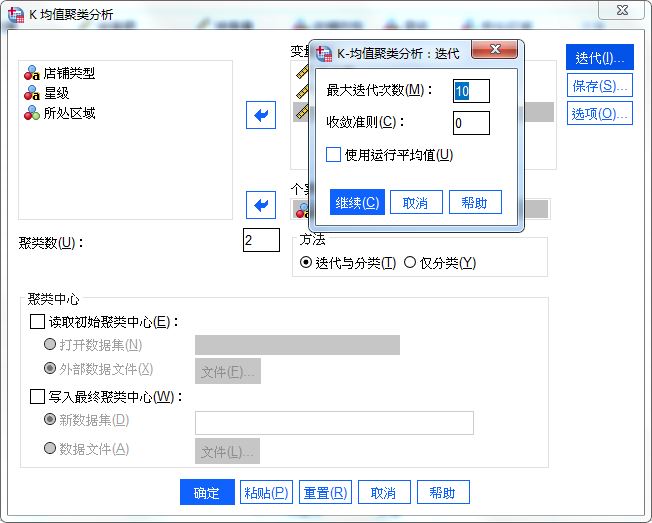
图5:迭代次数
最后,设置分析的选项,如图6所示,勾选“初始聚类中心”与“每个个案的聚类信息”,以了解初始聚类与最终聚类的个案数目;勾选“ANOVA表”,检验分析的置信水平。
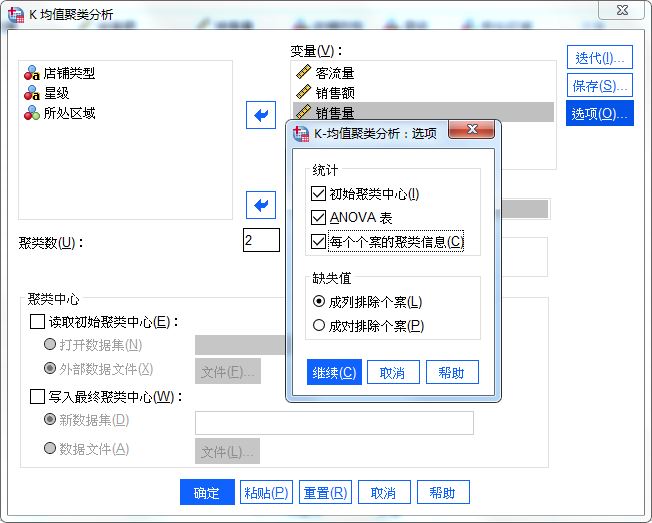
图6:选项设置
三、结果解读
运行分析后怎么运用spss进行数据分析,回到数据表,如图7所示,原数据表末端出现了两个新变量,分别是“聚类成员”与“与聚类中心的距离”。我们可以从中观察到每个个案所属的聚类,以及该个案与聚类中心的距离。
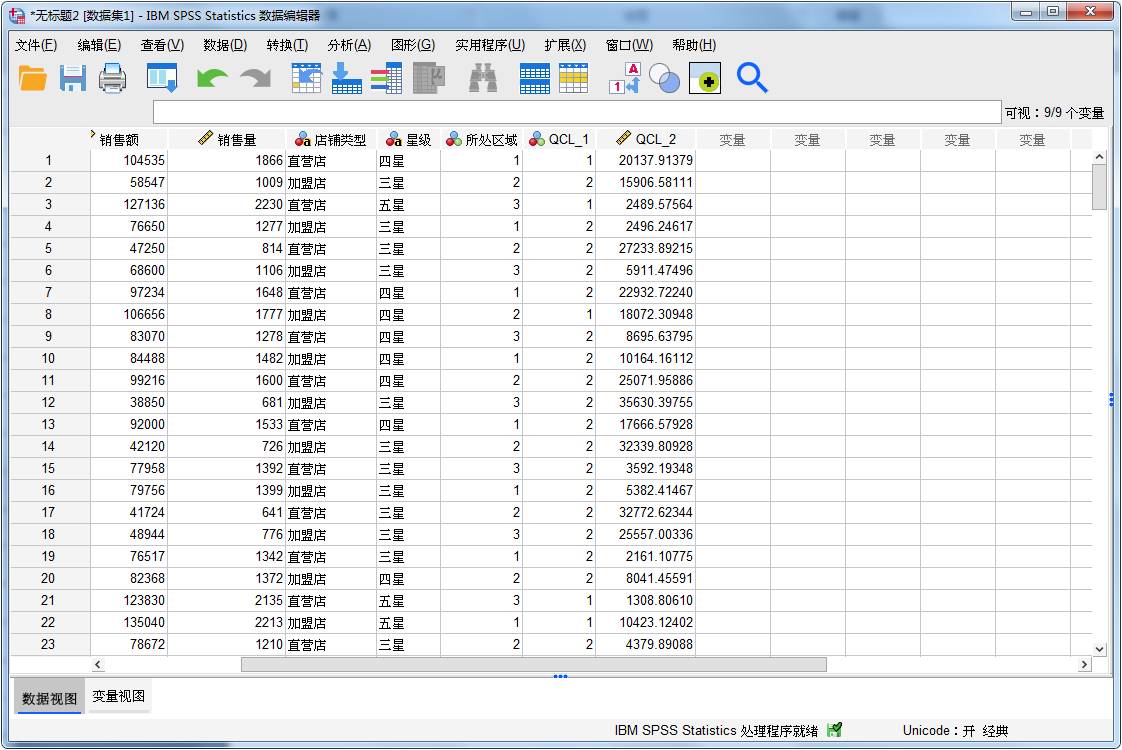
图7:生成新变量
而从分析结果看到,SPSS初始设定了两个聚类。
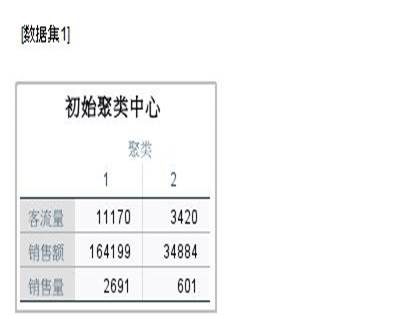
图8:初始聚类中心
而经过2次迭代运算后,最终聚类中心仍设定为两个不变。

来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。



")
