

没有人的生活可以脱离金融而独立存在,虽然随着科技的发展,人们变得越来越聪明,但金融是生活的基本必需品,因为每个人都需要钱来吃饭、旅行和买东西。目前已经形成了一个人与机器协同合作的金融市场,而人们正发明越来越多的方法来拖欠贷款、从其它账户偷钱、制造虚假信用评级等。今天,从审批贷款到资产管理,再到风险评估,机器学习在金融生态系统的许多阶段都起着不可或缺的作用。然而,只有少数懂技术的专业人士真正明白机器学习是如何在人们的日常财务生活中发挥作用的。
机器学习是什么?
机器学习是设计与应用算法的科学,构建算法可从数据中进行学习和预测。机器学习的应用在今天已很普遍,你可能每天不知不觉中使用了几十次。机器学习也提供了大量的用例,比如自动驾驶汽车、产品推荐引擎、预测分析、语音识别等等。数据科学家使用机器学习的主要目的是减少人类工作量,将人类在阅读、理解、分析大数据上的时间花费减少到几秒钟。
实施机器学习最常用的两种方法是监督学习和无监督学习。监督学习算法使用带标签的例子进行训练,输入数据对应的输出结果是预先可知的。而在无监督学习中,学习算法没有任何标签可使用,只能自己发现输入数据中的结构。
金融业中的机器学习特色?
与机器相比,大脑容量对思维有一定的限制作用。人类最多只能同时集中处理 3-4 件事情,而机器的处理能力是人类的几千倍。除了速度,在金融领域的其他方面,机器也将比人类表现得更好。
可靠性:在处理财务问题时,建立个体信用评级系统是十分必要的。银行、投资公司、股票市场每天都要进行多达数十亿美元的交易。因此,我们必须信任处理此事的公司或个人。由于人性中可能存在的偏见和自私,有些人往往会在金钱交易过程中进行诈骗。为了解决这类问题,嵌入了机器学习的机器在处理请求时可以做到零腐败。
速度:我们都知道在股票市场进行股票交易非常困难。人们通常在历史数据、图表和公式中进行大量的分析,以预测股票的未来,还有些人仅仅是随机下注。所有这些行为听起来都十分忙乱且耗时。机器学习算法能够对成千上万个数据集进行精确的深入分析,并可以在短时间内给出简洁准确的预测,有助于减轻人们在大数据整理和分析方面的麻烦。
安全:此前,勒索软件 WannaCry 攻击了世界各地的计算机,这表明,我们仍然易受黑客和网络安全方面的威胁。机器学习则通过将数据分为三个以上的类别,建立模型,以此预测欺诈或异常情况。而手工审查成本高、耗时长、误报率高,并不适用于金融业。
精度:人们没有能力或不喜欢做重复单调的任务,这种重复劳动往往会产生许多错误机器学习 股票分析,而机器可以在无限时地执行重复任务。机器学习算法会做数据分析的苦活,并在人类需要的情况下推荐新策略,还能够比人类更有效地检测到微妙的或非直觉的模式,从而识别出欺诈交易。此外,无监督机器学习模型可以不间断地分析和处理新数据,然后自动更新自身模型以反映最新趋势。
如何在信用评分中应用机器学习?
即使银行极度谨慎并认真核实公司信誉,但跨国公司拖欠银行债务,在金融领域似乎依然是一个普遍的现象。一些金融机构利用评分模型来降低信贷评估、发放和监督中的信贷风险。基于经典统计理论的信用评分模型得到了广泛应用。然而,当涉及到大量的数据输入时,这些模型的弹性表现较差。因此,经典统计分析中的一些假设就不能成立,这反过来又影响了预测的准确性。
根据客户的国籍、职业、薪酬、经验、行业、信用记录等信息来确定客户的信用风险评分,甚至是在向客户提供任何服务之前就进行此类评定,这对银行来说至关重要,这是银行在提供信贷或其它金融产品之前一个重要的关键绩效指标(KPI)。
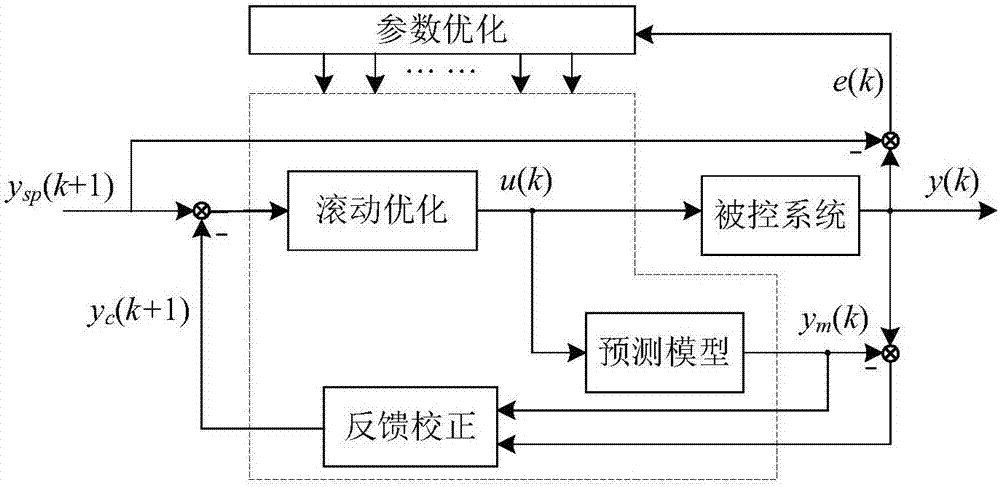
引入一个可以立即为客户服务的中央集成的金融风险机制是目前面临的主要挑战。即使是现在,由于无法预测客户的风险评分,银行也无法立即通过贷款审批。机器学习则可以加快放贷过程,且能避免耗时而必要的尽调程序。回归算法可以确定客户的信用评分,这些算法使用统计过程来估计变量之间的关系,在预测和预报方面得到了广泛的应用,在机器学习领域的应用也得到了迅速的发展。这种方法的第一步是定义客户历史信用记录的可用性,然后选择目标人群,并确定基准来界定满意/不满意的表现。这部分将作为回归算法启动操作的基本数据集。下一步则是选择样本,选择标准如下:
1. 确定公司系统中的可用变量
2. 定义利息期和样本大小
3. 验证数据的一致性和完整性
所选的可能的零散信息也被称为人口统计学变量:性别、年龄、职业、公司、教育、婚姻状况等,一般推荐登记时长为 12-18 个月的客户样本。这段时间足以检查延迟付款和违约的情况,且能巩固优质客户的支付行为模型。
通过变量选择、变量属性分组以及创建虚拟变量,则可以进行初步分析。使用列联表来计算与独立变量级别相关的相对风险(RR)指数,最后计算各个单一变量级别的优质客户与劣质客户之比。比例越大,该变量对未来业绩的预测作用就越大。而RR 通常介于 0 到 2 之间,0 代表极劣,2 代表极优。但是,分析过程不会使用类别为中性(Neutral)的样本,因为其优/劣程度相差不大。
模型的建立包括对多元统计技术的选择。之后确定要使用的软件、选择独立变量并检验技术假设,一旦数据减少到聚类级别,则可以使用判别分析、逻辑回归和神经网络,判别分析和逻辑回归则采用不同方法的统计技术。除此之外,还要对所选软件进行有关实施与易用性分析的检查。
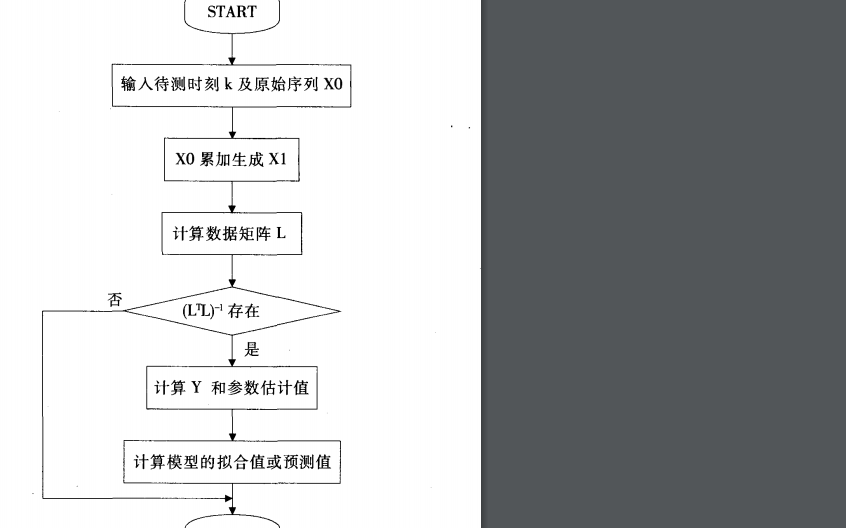
最后,为了评估性能好坏,需要找出两个样本的 KS 检验。需要找出两个集群之间的差异,比如由各自的预测结果所界定的优/劣付款人,确定每个预测中的优/劣付款人分布之间的差异,而 KS 测试的值是该模块中差异最大的一个。由于从模型得到的最终结果通常介于 0-1,当结果小于 0.5 时,客户会被定义为劣质付款人;反之则为优良付款人。
机器学习的其它优点
欺诈检测:使用机器学习进行欺诈检测时,先收集历史数据并将数据分割成三个不同的部分,然后用训练集对机器学习模型进行训练,以预测欺诈概率。最后建立模型,预测数据集中的欺诈或异常情况。与传统检测相比,这种欺诈检测方法所用的时间更少。由于目前机器学习的应用量还很小,仍然处于成长期,所以它会在几年内进一步发展,从而检测出复杂的欺诈行为。
股票市场预测:买卖股票而成为亿万富翁是常有的事,但是,如果不了解股票运作方式和当前趋势,要想击败市场则非常困难。随着机器学习的使用,股票预测变得相当简单。这些机器学习算法会利用公司的历史数据,如资产负债表、损益表
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





