
程序员的沉没成本论
沉没成本谬论是人类众多的认知偏见之一。 它指的是我们倾向于持续将时间和资源投入到失去的原因中,因为我们已经花了很多时间去追求无用的事情。沉没成本谬论适用于当我们花了很多成本也不会起作用的项目或工作。比如,当存在效率更高,互动性更强的选择时,我们依然继续使用Matplotlib。
在过去的几个月里,我意识到我使用Matplotlib的唯一原因是我花费了数百小时去学习它复杂的语法。这种复杂性让作者在StackOverflow上遭受了数小时的挫折去弄清楚如何格式化日期或添加第二个y轴。幸运的是,在探索了一些选项后,一个在易用性,文档和功能方面显著的赢家是Plotly库。
在本文中,我们将直接上手使用Plotly,学习如何在更短的时间内制作出更好的图表。
本文的所有代码都可以在GitHub上找到。 图表都是交互式的,可以在NBViewer上查看。
使用Plotly制作的样例
Plotly简介
Plotly Python包是一个基于plotly.js构建的开源库,而后者又建立在d3.js上。我们将用一个名为cufflinks的封装器来使用Pandas数据。因此,我们的整个堆栈是cufflinks> plotly> plotly.js> d3.js,这意味着我们可以通过d3的交互式图形功能去获得Python编码的效率。
(Plotly本身就是一家拥有多种产品和开源工具的图形公司。其Python版本的库可以免费使用,我们可以在离线模式下创建无限的图表,在线模式下最多可以创建25个图表,用于共享。)
本文中的所有工作都是使用Jupyter notebook完成的,其中的plotyl+cuffilinks可以在离线模式下运行。 在使用pip命令安装了plotly和cufflinks之后,在Jupyter中运行以下命令:
# Standard plotly imports import plotly.plotly as py import plotly.graph_objs as go from plotly.offline import iplot, init_notebook_mode # Using plotly + cufflinks in offline mode import cufflinks cufflinks.go_offline(connected=True) init_notebook_mode(connected=True)
单变量分布:直方图和箱线图
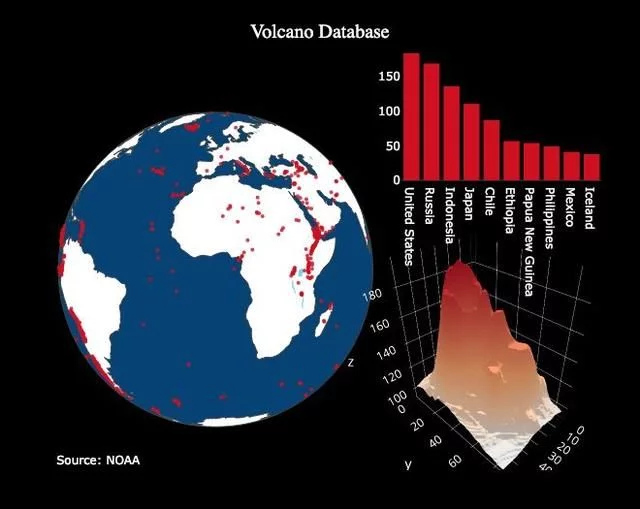
单变量—单因素—图是开始分析数据的标准方法,直方图是绘制分布图的首选图(虽然它有一些问题)。在这里,使用作者Medium文章的统计信息(你可以看到如何获取你的统计数据,或者你也可以使用我的),制作了关于文章点赞数量的交互式直方图(df是标准的Pandas数据帧):
df['claps'].iplot(kind='hist', xTitle='claps', yTitle='count', title='Claps Distribution')

使用plotly+cufflinks制作的交互式直方图
对于那些习惯使用Matplotlib的人来说,我们所要做的就是添加一个字母(使用iplot而不是plot),我们就可以得到一个更好看的交互式图表! 我们可以点击数据来获取更多细节,放大图的各个部分,我们稍后会看到,可以选择要高亮的内容。
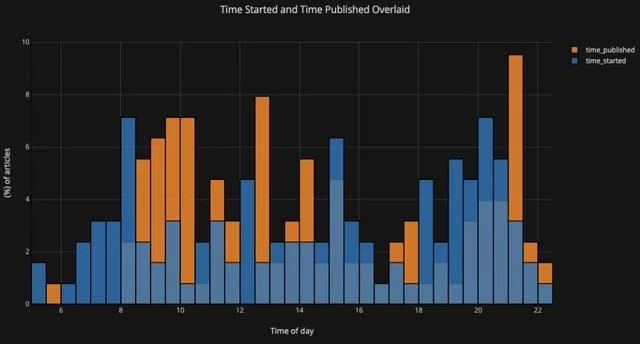
如果我们想要绘制叠加的直方图,使用如下代码,同样非常简单:
df[['time_started', 'time_published']].iplot( kind='hist', histnorm='percent', barmode='overlay', xTitle='Time of Day', yTitle='(%) of Articles', title='Time Started and Time Published')
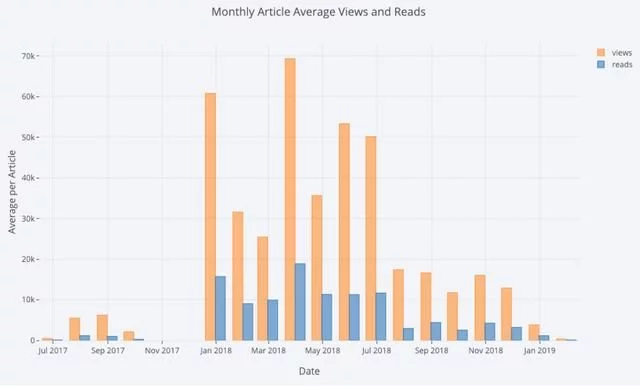
通过使用一点点Pandas相关的操作,我们可以做一个条形图:
# Resample to monthly frequency and plot df2 = df[['view','reads','published_date']].\ set_index('published_date').\ resample('M').mean() df2.iplot(kind='bar', xTitle='Date', yTitle='Average', title='Monthly Average Views and Reads')
正如我们所看到的,我们可以将Pandas与plotly+cufflinks结合起来。可对按出版物每个故事的粉丝,绘制箱线图:
df.pivot(columns='publication', values='fans').iplot( kind='box', yTitle='fans', title='Fans Distribution by Publication')

交互性的好处是我们可以根据需要探索和分组数据。 在箱线图中有很多信息,如果没有观察数字的能力,我们会错过大部分的信息!
散点图
散点图是大多数分析方法的核心。它允许我们看到变量随时间演变的过程或两个(或更多)变量之间的关系。
时间序列
相当一部分的真实数据会有一个时间维度。 幸运的是,plotly+cufflinks的设计考虑了时间序列的可视化。 接下来使用下面的代码制作一个关于作者TDS文章的数据框,看看趋势是如何变化。
Create a dataframe of Towards Data Science Articles tds = df[df['publication'] == 'Towards Data Science'].\ set_index('published_date') # Plot read time as a time series tds[['claps', 'fans', 'title']].iplot( y='claps', mode='lines+markers', secondary_y = 'fans', secondary_y_title='Fans', xTitle='Date', yTitle='Claps', text='title', title='Fans and Claps over Time')
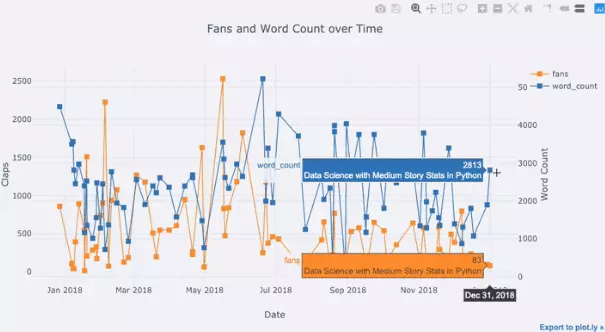
在这里,我们仅用一行代码做了很多不同的事情:
我们还可以非常轻松地添加文本注释:
tds_monthly_totals.iplot( mode='lines+markers+text', text=text, y='word_count', opacity=0.8, xTitle='Date', yTitle='Word Count', title='Total Word Count by Month')
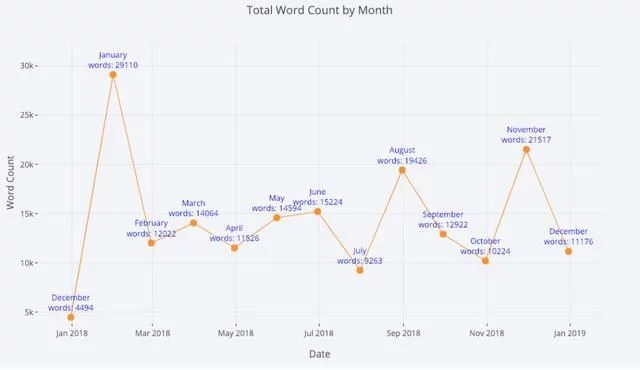
带注释的散点图
对于使用第三个变量来上色的双变量散点图,我们可以使用如下命令:
df.iplot( x='read_time', y='read_ratio', # Specify the category categories='publication', xTitle='Read Time', yTitle='Reading Percent', title='Reading Percent vs Read Ratio by Publication')
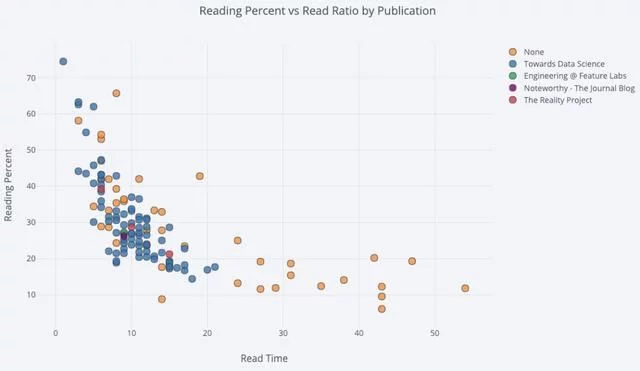
我们可以使用log轴(指定为绘图布局)(参见Plotly文档-中的布局细节-)以及数值变量来调整气泡,让图表更复杂一点:
tds.iplot( x='word_count', y='reads', size='read_ratio', text=text, mode='markers', # Log xaxis layout=dict( xaxis=dict(type='log', title='Word Count'), yaxis=dict(title='Reads'), title='Reads vs Log Word Count Sized by Read Ratio'))
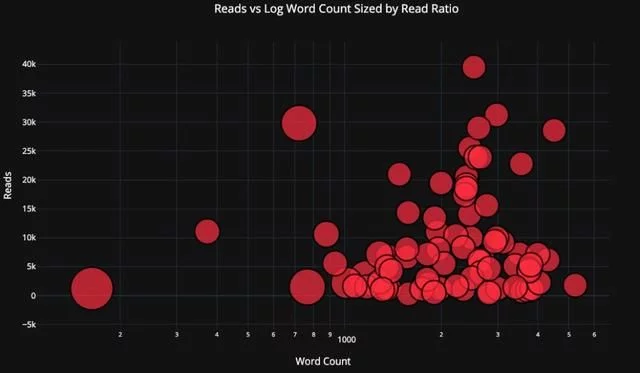
更进一步的工作(详见notebook),我们甚至可以在一个图表上放置四个变量(不建议)!

和之前一样,我们可以将pandas与plotly + cufflinks结合起来,用于获得有用的图表。
df.pivot_table( values='views', index='published_date', columns='publication').cumsum().iplot( mode='markers+lines', size=8, symbol=[1, 2, 3, 4, 5], layout=dict( xaxis=dict(title='Date'), yaxis=dict(type='log', title='Total Views'), title='Total Views over Time by Publication'))
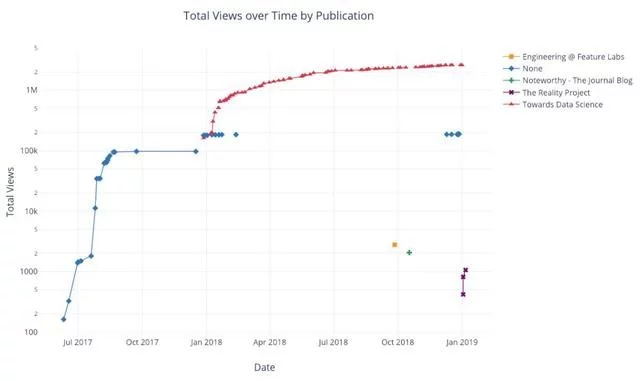
有关添加功能的更多示例,请参阅notebook或文档。 我们可以使用单行代码在文本中添加文本注释,参考线和最佳拟合线,并且仍然可以进行所有的交互。
进阶图表
现在我们将制作一些你可能不会经常使用的图表地图数据可视化,它可能会令人印象深刻。我们将使用plotly figure_factory,也仅使用一行代码来制作这些令人难以置信的图。
散点矩阵
当我们想要探索许多变量之间的关系时地图数据可视化,散点矩阵(也称为splom)是一个很好的选择:
df['claps'].iplot(kind='hist', xTitle='claps', yTitle='count', title='Claps Distribution')0
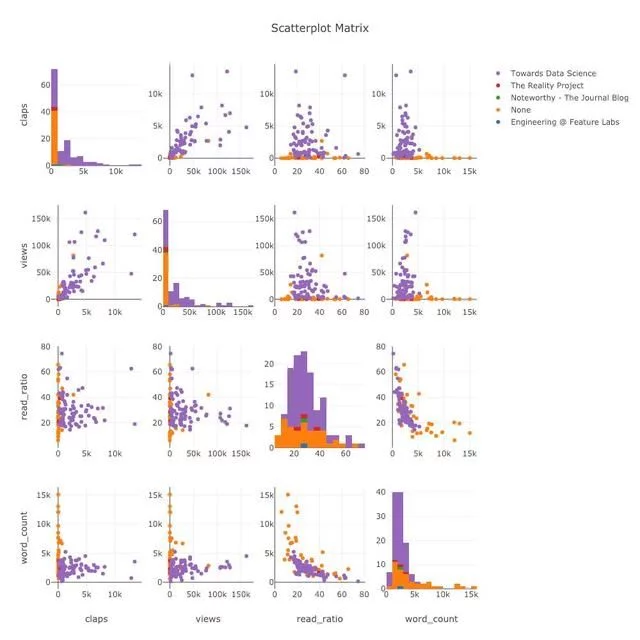
这个图也是可以完全人机交互的,用于探索数据。
相关性热力图
为了可视化数值变量之间的相关性,我们会计算相关性,然后制作带注释的热力图:
df['claps'].iplot(kind='hist', xTitle='claps', yTitle='count', title='Claps Distribution')1
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





