
大家好,我是曹鑫老师,今天要给大家分享的是网上数据的自动批量搜集整理,大家更熟悉的名字是「爬虫」。

扫码预约九宫格数据
线下体验店
在课程开始之前,我要先说一段免责声明:这次课程对于数据抓取的相关知识,只做学术探讨,不要利用抓取到的数据做有损访问网站商业利益的事情,比如你也建立一个同样业务的网站;也不要对访问网站的服务器造成压力,影响正常用户的访问。以上也是大家以后在进行数据采集的时候需要注意的。那我们继续讲技术,数据采集对于我们日常的工作有什么帮助呢?我举个例子。
比如当我们来到CDA官网的直播公开课页面,我们可以看到这里有很多的课程,每个课程的组成部分是一致的,包含了它的主题海报、标题内容、授课老师的介绍和头像,同时我还可以翻页到下一页,看到更多的往期公开课,这种构造相信你在很多网站都看到过,你就要联想到,今天学到的内容,也差不多能应用到类似的网站去。
接下来,如果想要把这些内容全部整理到一张Excel表里面,你该怎么办?第一反应是不是:那就去挨个复制标题,复制老师的名字,复制介绍内容,一个个粘贴到Excel表里?没错,这是我们要做的,但真要拿着鼠标去挨个点,敲着键盘 `Ctrl+C`、 `Ctrl+V`,未免也太累了,这就是日常工作中比较典型的场景:任务操作一点不难,但需要不断重复操作,费时费力。
如果掌握了 Python 数据采集,我会怎么来解决这个重复操作的任务呢?我先给你演示一下效果。代码不难,就这么一段爬虫数据分析,你现在看肯定一头雾水,不要着急,我一段段带你来阅读理解。
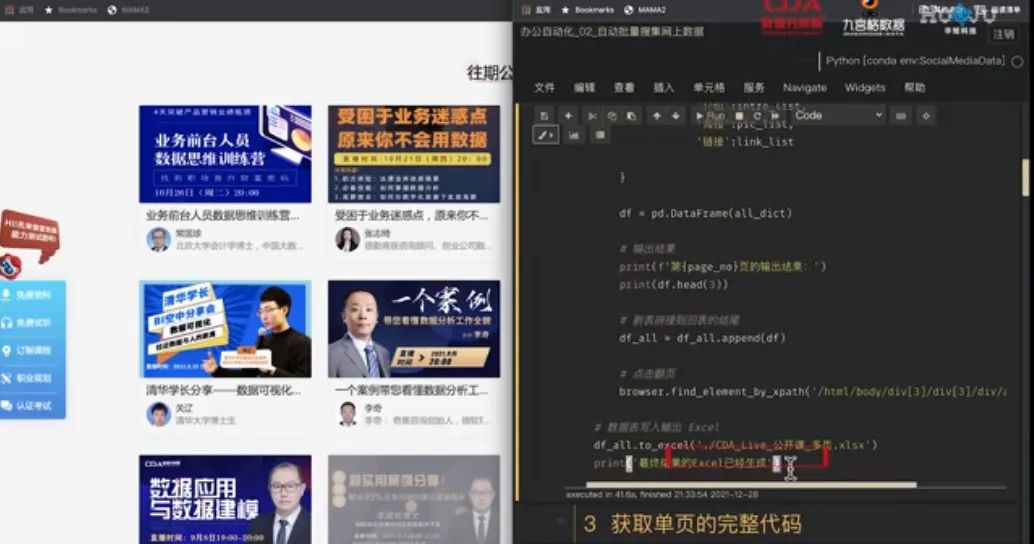
点击`Shift+回车`,我们运行一下代码看看:
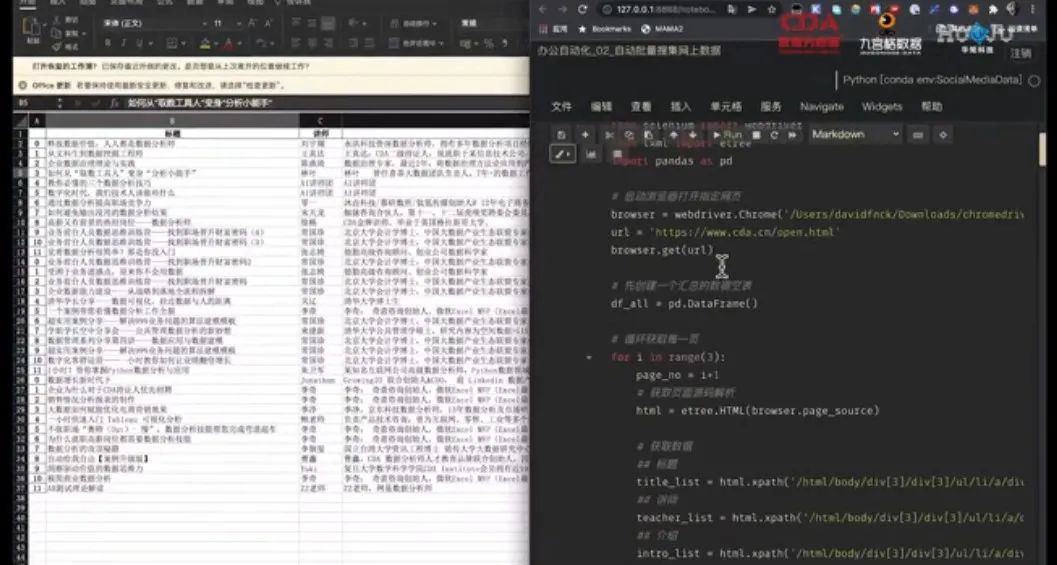
1. 浏览器自动打开指定的页面,也就是直播公开课的第一页。
2. Anaconda 中,星号表示该代码区域正在运行,而在代码区域下方会输出打印的结果。
3. 紧接着循环获取数据,代码获取到了第一页的内容,并整理成表格打印出来。
4. 然后,浏览器自动翻页到第二页,又一次获取第二页的内容,并整理成表格打印出来。
5. 继续,第三页,同样的输出。
6. 最后,输出了一个 Excel 文件,我们打开看一下,全部页数我需要的数据都整理好了。
我们想要的效果实现了,有几个好处:
1. 我只点了一下鼠标移动到代码区域;敲了一下键盘 `Shift+回车`启动程序,接下来我就不用再点鼠标或者敲键盘了,全部交给 Python 程序
2. 我现在是获取3页,我要获取10页,100页,1000页,我只要改一下循环这里的数字,让它循环10次、100次甚至是1000次,再也不用多花更多时间和体力,始终就是一点一运行,剩下的体力活全部交给 Python 。
一旦掌握了数据采集技术,类似的重复性工作你都可以自动化完成。
下面是分享给大家的代码,可以自行操作试试哦。
# 调用包 from selenium import webdriver from lxml import etree import pandas as pd # 启动浏览器打开指定网页 browser = webdriver.Chrome('/Users/davidfnck/Downloads/chromedriver') url = 'https://www.cda.cn/open.html' browser.get(url) # 先创建一个汇总的数据空表 df_all = pd.DataFrame() # 循环获取每一页 for i in range(3): page_no = i+1 # 获取页面源码解析 html = etree.HTML(browser.page_source) # 获取数据 ## 标题 title_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/h2/text()') ## 讲师 teacher_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/div/h4/text()') ## 介绍 intro_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/div/p/text()') ## 图片 pic_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/img/@src') ## 链接 link_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/@href') # 组合成字典,生成数据表 all_dict = {'标题':title_list, '讲师':teacher_list, '介绍':intro_list, '海报':pic_list, '链接':link_list } df = pd.DataFrame(all_dict) # 输出结果 print(f'第{page_no}页的输出结果:') print(df.head(3)) # 新表拼接到旧表的结尾 df_all = df_all.append(df) # 点击翻页 browser.find_element_by_xpath('/html/body/div[3]/div[2]/div/a[4]').click() # 数据表写入输出 Excel df_all.to_excel('./CDA_Live_公开课_多页.xlsx') print('最终结果的Excel已经生成')
当下企业数字化转型正快速发展,在越来越严苛的外部监管及越来越激烈的市场竞争驱动下,各行各业都在急迫地对数据进行最大化的价值挖掘。然而,大多数企业在推动落地时,都会遇到诸多问题。快速了解“数据从治理到分析”的落地流程与产出效果,以最低成本实现团队协同,快速解决深奥数据问题,成为越来越多企业加大数字化转型投入的核心动力。
CDA数据分析师作为专注于数字化人才培养及服务的教育品牌, 一直致力于大数据在产、学、 研的融合应用。以“培养企业需要的专业数字化人才, 搭建引领数字化时代的企业人才梯队” 为使命, 为DT时代数字化人才的数据能力提升及企业数字化转型提供标准化、 高效率、 可落地的数据应用侧解决方案。成立15年来, 始终在总结凝练先进数字化商业数据策略及技术应用实践, 以实际行动提升了数字化人才的职业素养与能力水平, 以建设高质量生态圈层促进了行业的持续快速发展。
CDA数据分析师携手华矩科技,以数据治理与数据分析为特色爬虫数据分析,联合开设九宫格数据体验店北京分店并对外运营。

来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





