
一起聊有趣的数字~~
最近跟很多朋友在聊对专业术语和流行话题的认知。的确随着应用场景的变化很快,大数据处理环节的边界也在不断演变,不断在挑战认知的宽度。 本着不断学习,不断尝试的心态去探索新的好玩的方法,会其乐无穷~~
· 正 · 文 · 来 · 啦 ·
数学建模:是数学的一个分支,理论上是根据实际问题来建立数学模型,对数学模型来进行求解,然后根据结果去解决实际问题。用数学符号,数学式子,程序,图形等对实际课题本质属性的抽象而又简洁的刻画,它或能解释某些客观现象数据分析与建模方法,或能预测未来的发展规律,或能为控制某一现象的发展提供某种意义下的最优策略或较好策略。数学模型一般并非现实问题的直接翻版,它的建立常常既需要人们对现实问题深入细微的观察和分析,又需要人们灵活巧妙地利用各种数学知识。这种应用知识从实际课题中抽象、提炼出数学模型的过程就称为数学建模。
如果想要用一句话总结说明,就是从具体事务中总结归纳相似相异性,抽象提炼出特征的过程。举个特别好理解的例子吧:比如在教小朋友们认识立体图形时:
1、只有球面的立体图形,只能滚动;称为--球体, 足球、篮球等;
2、有球面和一个平面的立体图形,可以滚动和移动;称为--椎体,三角锥,圣诞树等;
3、有球面和两个平面的立体图形,可以滚动、移动和堆放;称为--圆柱体,保温杯,泡沫滚轴等;
4、没有球面只有平面的立体图形,可以移动和堆放;称为--立方体,魔方、铅笔盒等;
小朋友在学习这些立体图形时,总结的特征:滚动、移动和堆放,具备什么条件,就会有什么特征,这样简单的归类统计,其实就是最简单的数学建模过程。这样的思维训练就是在训练逻辑思考力。
应用数学去解决各类实际问题时,建立数学模型是十分关键的一步,同时也是十分困难的一步。建立数学模型的过程,是把错综复杂的实际问题简化、抽象为合理的数学结构的过程。要通过调查、收集数据资料,观察和研究实际对象的固有特征和内在规律,抓住问题的主要矛盾,建立起反映实际问题的数量关系,然后利用数学的理论和方法去分析和解决问题。
现在越来越多的数学建模比赛走进校园,开设了各种形式的数学建模课程和讲座,为培养学生利用数学方法分析、解决实际问题的能力开辟了一条有效的途径。全国大学生数学建模竞赛由国家教育部高教司和中国工业与应用数学学会共同主办。竞赛评奖以假设的合理性、建模的创造性、结果的正确性和文字表述的清晰程度为主要标准。

数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
在我看来,数据挖掘首先是提取有含义的数据,通过针对性的清洗数据分析与建模方法,高质量剔除干扰数据,分析并发现高度相关的数据。这里有个最经典且流传已久的数据挖掘成功案例:"尿布与啤酒"的故事。
在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。这不是一个笑话,而是发生在美国沃尔玛连锁店超市的真实案例,并一直为商家所津津乐道。沃尔玛拥有世界上最大的数据仓库系统,为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。沃尔玛数据仓库里集中了其各门店的详细原始交易数据。在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。一个意外的发现是:"跟尿布一起购买最多的商品竟是啤酒!经过大量实际调查和分析,揭示了一个隐藏在"尿布与啤酒"背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
根据一般经验,很难想到尿布与啤酒的关联性会那么大,但是沉淀下来的历史销售数据通过挖掘提炼清洗过滤,尿布和啤酒的销售关联度就凸显出来了。
数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,即使知道也是不确定的,因此关联分析生成的规则带有可信度。关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。Agrawal等于1993年首先提出了挖掘顾客交易数据库中项集间的关联规则问题,以后诸多的研究人员对关联规则的挖掘问题进行了大量的研究。他们的工作包括对原有的算法进行优化,如引入随机采样、并行的思想等,以提高算法挖掘规则的效率;对关联规则的应用进行推广。关联规则挖掘在数据挖掘中是一个重要的课题,最近几年已被业界所广泛研究。
当然想要在日常处理的场景中快速定位到可能存在关联度的范围,是需要很多算法和经验的。现在有两种说法,一种认为现在数据的集聚太快,人们的行为变化太快,经验已经过时了,跟不上现在的变化趋势,不能凭经验找目标数据去做关联证明;另一种认为,就是因为数据量太大,耗用大量人力物力和时间成本去处理海量数据,得到的结论往往因为质量过低的数据干扰,产生与实际情况差异较大的结论;其实这两种观点都有各自的立场,也都是存在的大数据运营问题。当然数据挖掘算法的使用要依据不同的场景进行选择,初期要减少弯路,经验的判断也是很重要的一种校验维度。
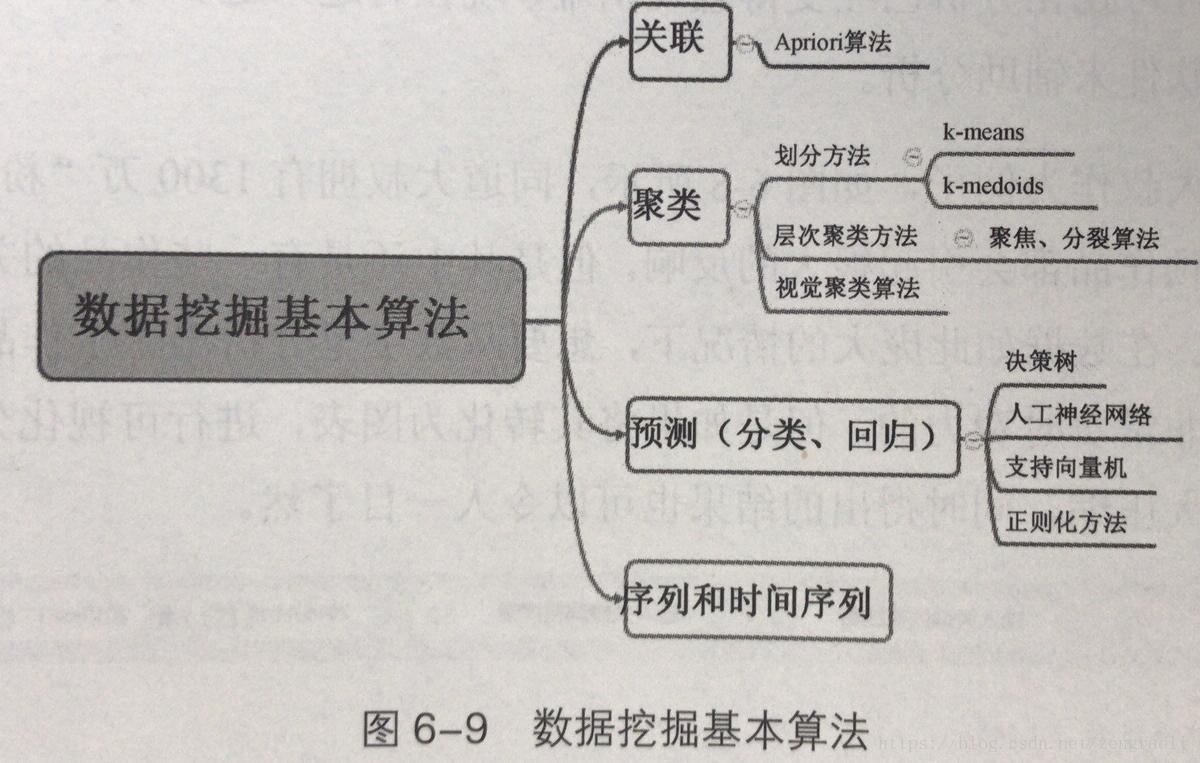
目前最常用,最流行的挖掘算法有聚类降维、最大邻近值、决策树、还有Google最经典的paperank算法(我的偶像充分利用Google算法的特点,成功让自己的推文在一个月内推送到了首页Top3的位置,改天给大家安利一下:大牛的脑洞就是与一般人不一样)
C4.5:是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。
K-means算法:是一种聚类算法。
SVM:一种监督式学习的方法,广泛运用于统计分类以及回归分析中
Apriori :是一种最有影响的挖掘布尔关联规则频繁项集的算法。
EM:最大期望值法。
Adaboost:是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器然后把弱分类器集合起来,构成一个更强的最终分类器。
KNN:是一个理论上比较成熟的的方法,也是最简单的机器学习方法之一。
Naive Bayes:在众多分类方法中,应用最广泛的有决策树模型和朴素贝叶斯(Naive Bayes)
Cart:分类与回归树,在分类树下面有两个关键的思想,第一个是关于递归地划分自变量空间的想法,第二个是用验证数据进行减枝。
数据分析,相对前两个概念来看,更偏重于对数据结果的透视,对技术上的处理和效果实现相对而言要求低一些。但是数据分析是对挖掘数据的价值提升,再举个特别简单的,就在身边的例子来说明:(如下是经过清洗,并剔除了干扰项的按照时间切分整理后的数据,不多,但可以发现很多分析角度,制定相应的营销策略)
某男士的一周消费记录:
月初 工作日:周一:20 30 1200 100小计:1350
工作日:周二:22 33 50 18小计:123
工作日:周三:20 33 200 500小计:753
工作日:周四:2.8 30 0 60小计:92.8
公共假期: 周五:2.8 60 150 699小计:911.8
公共假期: 周六:50 66 500 350小计:966
公共假期: 周日:0 0 200 450小计:650
乍一看,从消费账单上清洗并提炼出如上数据,数据不多,很清晰,这时候周密的数据分析就可以再一次提升数据挖掘的价值。
由于篇幅的关系,不能写得太多,其实如果结合调整策略后的数据,还可以分析出更多有意思得场景预测,结合预测做一些策略,观察数据的变化,又能发现新的场景预测。当然如果分析目的不同,比如上面的例子,如果收支比只有30%,或者是老婆想观察老公是否有小三的消费倾向,那分析的角度又会完全不一样了。
是不是有种数据挖掘是技术活, 数据分析是艺术活的感觉~~
数据模型 是数据特征的抽象。数据是描述事物的符号记录,模型是现实世界的抽象。数据模型从抽象层次上描述了系统的静态特征、动态行为和约束条件,为数据库系统的信息表示与操作提供了一个抽象的框架。
数据以什么样的关系形成彼此联系,并以什么样的结构进行存储,同时也要考虑用什么方式方便查询和调取,这些都与数据模型有关。
数据发展过程中产生过三种基本的数据模型,它们是层次模型、网状模型和关系模型。这三种模型是按其数据结构而命名的。层次模型的基本结构是树形结构;网状模型的基本结构是一个不加任何限制条件的无向图。关系模型为非格式化的结构,用单一的
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。




