
[导读]本文选自百融金服CEO张韶峰和CRO季元于2017年9月14日晚在清华大数据“技术·前沿”系列讲座——大数据与AI技术在金融科技的应用上的分享。两位学长结合自己在金融行业和金融科技领域多年的探索,结合金融领域的反欺诈、信用风险识别、不良资产催收、精准营销等业务场景,深入浅出地阐述对抗生成网络、迁移学习、强化学习等方法的金融行业建模实践。

百融金服CEO张韶峰

百融金服CRO季元
张韶峰:首先非常激动能够回到母校跟各位校友,还有各位朋友,来分享这次报告。我们进入到金融科技领域是2012年,我们最早跟银行交流,想推动我们公司用机器学习算法作为模型在银行应用,银行那时候习惯运用的算法叫逻辑回归算法(Logistic regression algorithm),是一种比较简单的算法。但是我坚定地认为数据有用,至于有什么用,其实想不清楚,只是后来遇到金融行业的大爆发、变革,才发现数据在金融领域的应用那么直接。
金融领域一个非常重要的支柱就是信用体系。中国还有七八亿有金融需求的人没有信用记录,这是制约中国所谓普惠金融,刺激小微企业发展、消费发展,这是属于基础设施的问题。
大数据应用分层
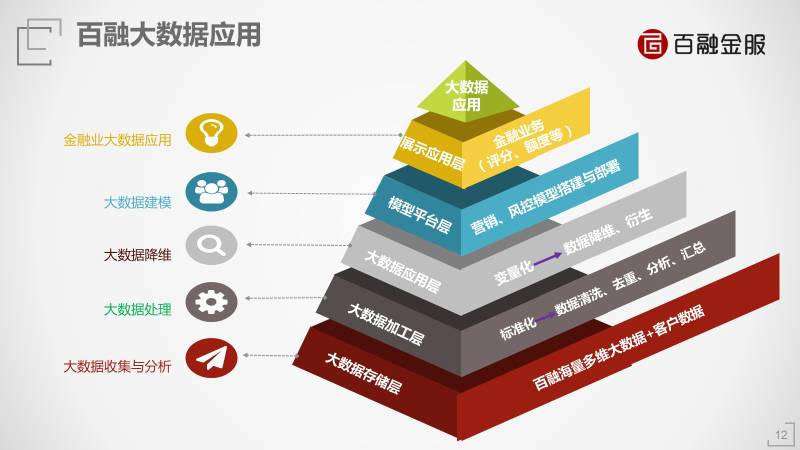
从大数据行业来看,有些是共通的。
第一步,收集数据。
第二步,数据处理。把数据进行标准化,清洗脏数据、不准的数据,或者做一些脱敏。
第三步,数据降维。如果表格的每一行是一个用户,一个表的列数多达50万列,这是非常庞大的一个维度,处理起来会导致效率下降,需要做一些数据的降维,需要做一些衍生变量。
第四步,数据建模。金融里有两个模型最重要:第一类是营销获客模型,预测什么人需要什么样的金融服务,主要是预测客户的需求。第二类是风控模型。
第五步,大数据应用。不同的行业做的应用不同。
金融行业可以在哪些方面具体使用呢
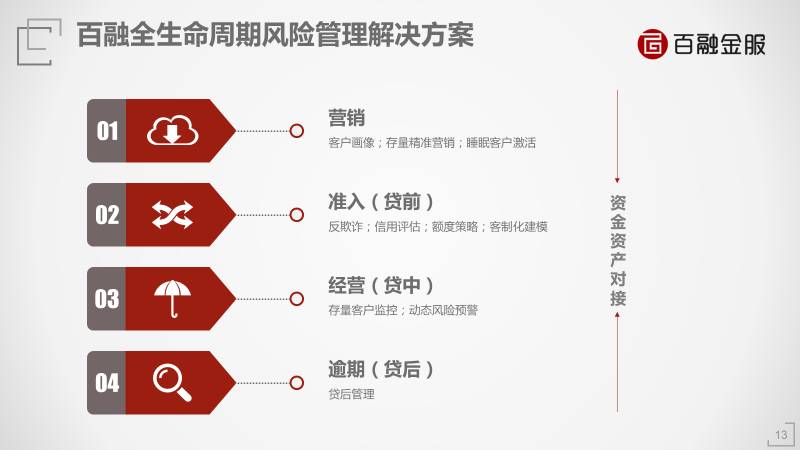
第一步,解决精准营销。找好的而且有需求的客户,这两个标准要叠加。金融行业的精准营销难度远远超过普通消费品,这是金融行业精准营销的特殊性。
第二步,准入。他如果来申请你的贷款,或者买你的保险,你能不能把他放进来?你得审批一次。比如你去银行办个贷款,或者办一个信用卡,让你填一大堆资料。
第三步,存量客户的经营或者贷中管理。
第四步,逾期。这是贷后管理。
从营销、准入、经营、逾期,这四步每一步都可以充分使用大数据和人工智能算法来提升效率。
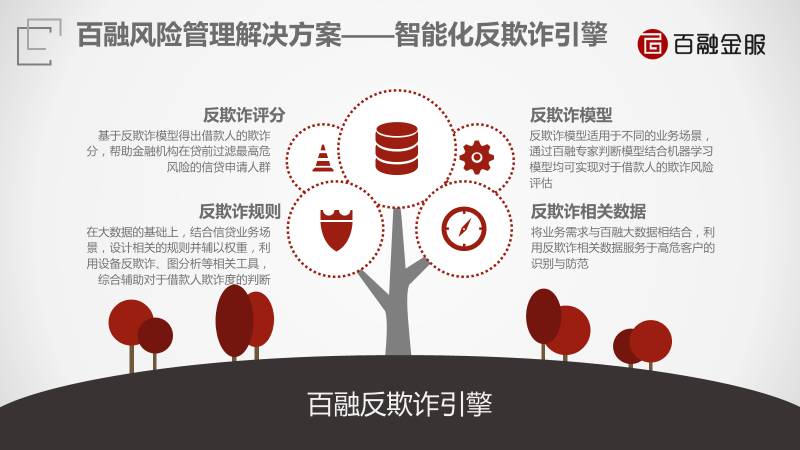
我们完善了一套反欺诈引擎评分,评估你有多大概率会欺诈。规则是遇到什么情况要采取什么措施。模型是抽像出决策逻辑以及跟欺诈相关的数据。
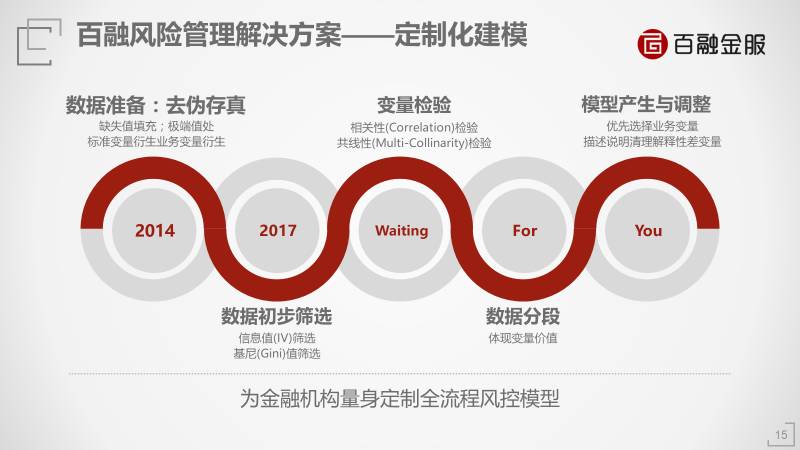
我们为金融机构提供定制化的服务,因为你的产品和你的客户跟别的金融机构不可能一模一样。我们的模型可以有差异化,数据的准备、初步筛选、交验检验,筛选相关性比较高的变量、数据的分段,最后建立模型。
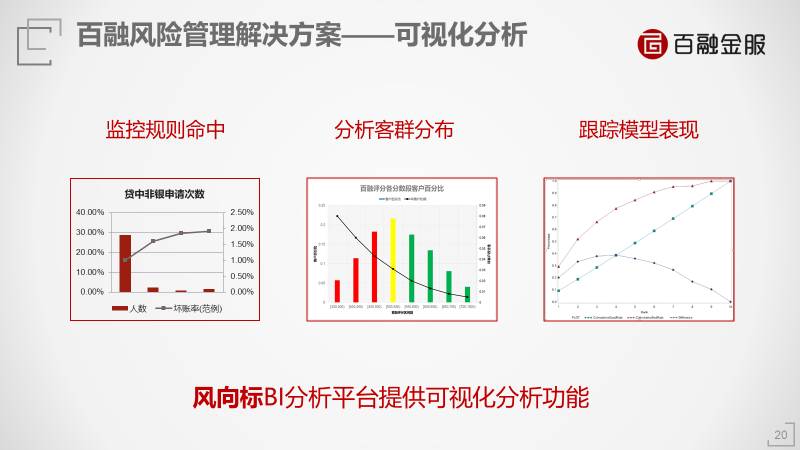
我们用一些可视化的算法使金融机构和我们监管人员看得更清楚,规则有没有命中,客群分布怎么样。在客观的分数段中,比如我们公司是300分到1000分,比如700分的人对应100个人里只有3个人违约,而500分的人对应100个人里头有7个人违约,不同的分数段意味着不同的违约率,这个时候你就知道我应该给700分以上的放贷。这个评分对金融机构很重要,你算清楚每给500分的人放款一万块钱出去会亏多少钱,评分系统会帮你预测。
随后,百融金服CRO季元先生与大家分享了具体的应用案例。
案例一:图深度学习应用于团伙欺诈侦测
季元:百融在群体欺诈的跟踪、反欺诈方面主要通过无监督-异常行为监测,还有通过监督学习-地理位置异常分析(Geohash)
,具体的实现方式是通过图特征学习算法。
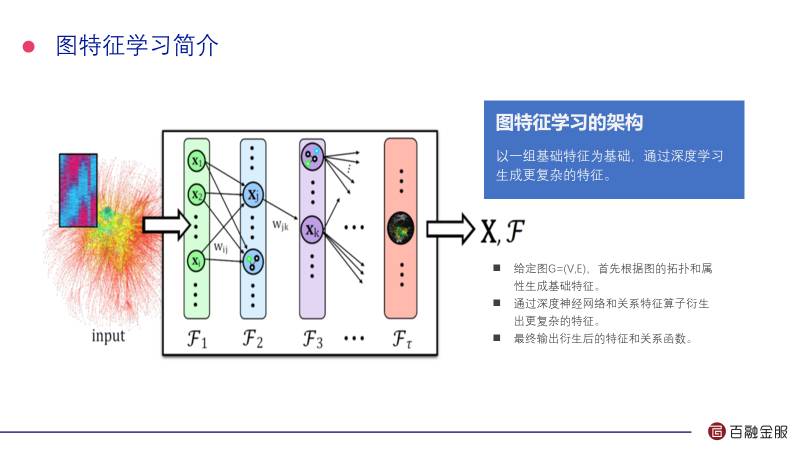
这是图特征学习算法大概的框架。因为我们输入的是我们客户图的特征,这张图包括边和点,图的拓谱和节点的这些属性构造了客户的基本特征。通过深度神经网络,从这些基本特征出发衍生出更复杂的特征。最终我们输出的是什么?一个是衍生后的特征,再一个是观察,观察为了从基础端衍生数学特征,把这个算法形成好东西移植到其他部分。
左边这个表是我们常用的一些特征算子。这个图反映了某个局部的具体的阶段,百融从DI特征出发通过Faier做衍生,衍生出新的特征。这个算法其实有四个优点:
第一它支持不同的属性图,因为通常我们的图只是节点和边,只能反映拓扑结构;
第二它能输出复杂关系函数用于跨网络迁移学习;
第三它能够学习出稀疏特征。
第四它支持并行,算法效率高。
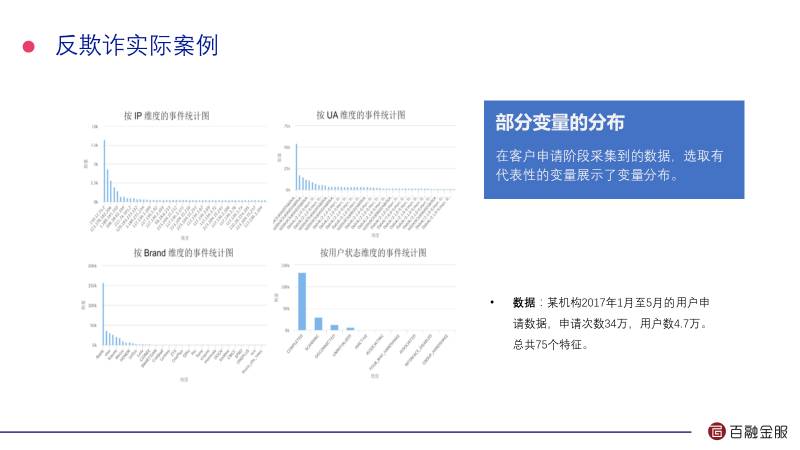
这是我们某个客户在2017年1月到5月份的用户申请数据,申请次数34万,用户数4.7万,总共70个特征。通过我们的算法识别出了它有12000多欺诈用户,隶属于238个团体。
案例二:强化学习应用于催收模型构建
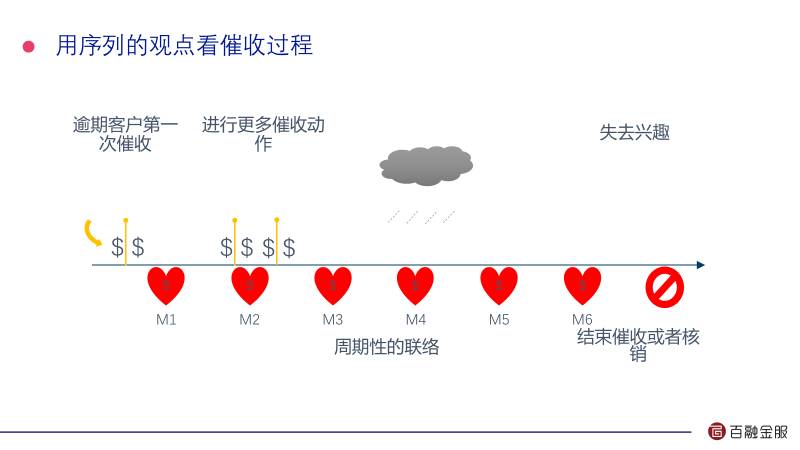
在你借了金融机构的钱之后,如果你一旦逾期不还钱,这个时候金融机构在内部是按照你逾期的时间给你划分的,M1代表逾期一个月,M2是两个月,在不同的逾期时间,它会给你不同的催收动作。

我们应该从序列的观点看,因为不同的人对不同动作的响应是不一样的。实际上你每一步的动作都会影响到后续的结果,应该以整个过程的最大的回馈,来决定我们在什么环节采取什么样的动作。这块我们就把催收过程定义成一个马尔科夫决策过程。

通过强化学习来求解马尔科夫决策过程。首先要定一个价格函数,其次就是你在不同时间段收回的钱,用折现因子折算到当前来看你的最大值,我们要求价值函数的最优点,这个算法是通过价值迭代来实现。
案例三:迁移学习应用于客群评分构建

我们的信用评分体系包括一个通用评分加上6个客群评分,通用评分类似于芝麻评分。这个评分在金融机构是怎么用的呢?我们可以看到这个图,柱状图表示不同分数段人数的占比,线图是不同分数段人数的的违约率,我们看到最低的300分数段违约率达到20%以上,最高的700分以上的不到1%。所以一个金融机构如果选择了500分以上的人,那么就意味着500分左边的这些人他都要拒绝掉,而且如果只要500分以上的人的不良率在8%以下,如果他想降低不良率,比如降低4%,那就意味着他要提高准入标准,可能把准入的门槛提高到600或者更高。
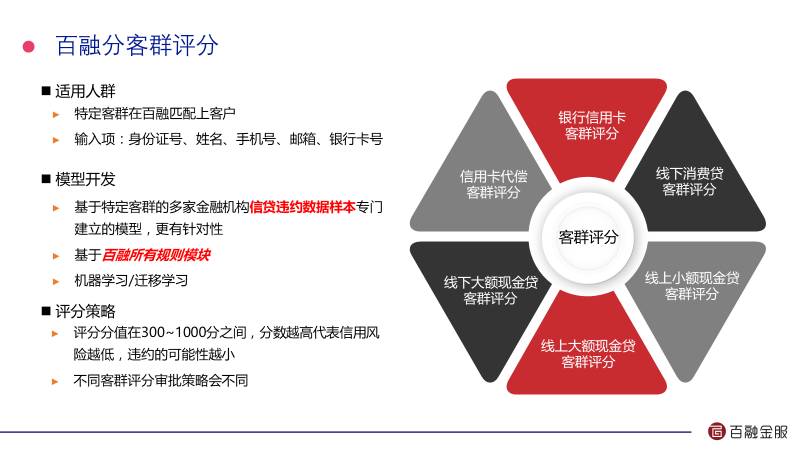
这是我们的6个客群评分,这个评分实际上对金融机构来讲非常重要,因为大家希望我们把坏人全过滤掉,好人全放进来,这是不可能实现的。现实中我们的评分通常居于两者之间,我们的目标是尽可能的靠近最好的那个部分。除了这7个标准评分之外我们还有定制产品,刚才邵峰介绍的给客户做定制化的建模大数据应用场景 ppt,因为好的客户希望结合他的内部数据和我们百融数据一起构建一个专属于他的评分,这样效果会比标准评分更好。
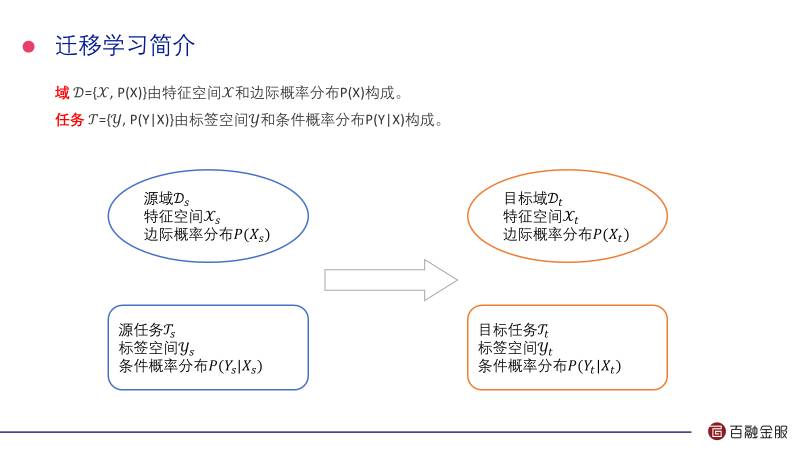
在信用评分构建的过程中存在一些现实问题,在讲这些问题之前我先给大家简单介绍一下什么叫迁移学习。两个基本概念:
第一个是域,域实际上包括两个元素,X是特征区间,这些变量的维度, P(X)是特征空间上的概率分布,实际上是我们的样本和这些特征的分布。
第二个是任务,任务包括一个标签空间,是在样本特征空间上好或者坏甚至更多的内容,属于监督学习的一部分。
我们知道域和标签空间来求这个条件概率。
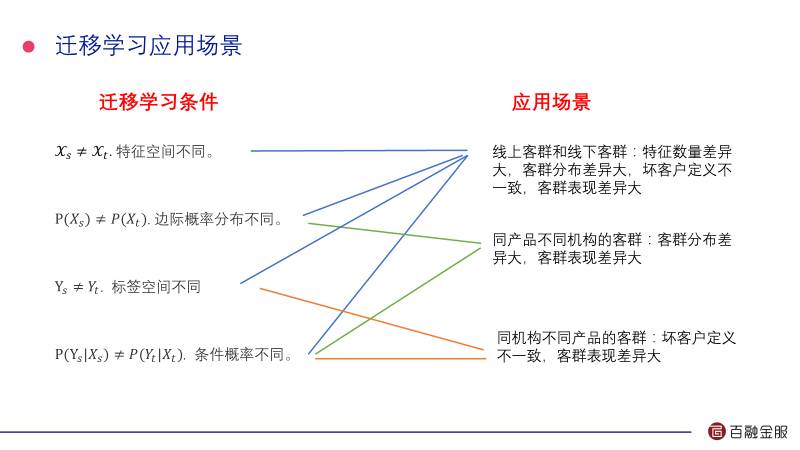
在迁移学习里面需要两个域和目标,一个是源域和源任务,一个是目标域和目标任务。按照刚才定义我们现在有四种情况:
第一,源域的特征空间和目标域的特征空间不同;
第二,边际概率分布不同;
第三,标签空间不同;
第四,条件概率不同。
这四种组合起来就是16个,但是现实生活中这16种组合不会都存在。包括比较典型的就是这三类:
第一种是线上客群和线下客群,它们的特点不一样,因为线上客群我们能采集的特征的维度更多;
第二种是同产品不同机构的
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





