
数据集是从uci下载的,某家银行电话营销与是否购买定期存储的数据。
模拟目标是知道客户数据,预测购买理财产品概率
我认为将电话营销的数据消除只保留基本属性可以模拟实际银行能够获取的数据。
电话营销数据代表一些对用户决定由影响但是获取难度较大的数据。比如说,买房、买车、小孩上学,这些数据银行不能立刻获得,或者获取成本较高。这里不使用这些数据参与预测。虽然预测准确度会降低,但是更符合实际情况。
然后定期存储是一种产品,可以当做一种理财,如果能对一种进行预测行进实现和验证,那么可以扩展到多种产品的预测
数据情况,见下表
Age
年龄
Job
工作
Marital
婚姻情况
Education
教育情况
Default
违约情况 no无违约 yes有违约
Balance
账户余额
House
是否买房子 no无房产 yes有房子
Loan
贷款 no无贷款 yes有贷款
数据处理
数据清洗常规套路(空值检查,去重,去异常值)
由于数据集较好,基本不需要处理,但实现数据很有可能需要清洗,比如说,年龄缺失不能简单补0。
balance处理的尝试
balance的分布在较大值较少,需要处理balance不处理
对数据one-hot encoding,对yes,no等2分类用0,1替换
处理之后数据为
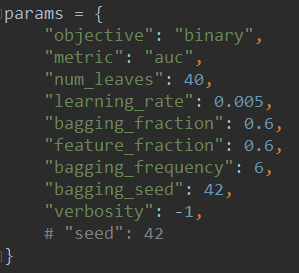
使用lightgbm建模,参数如下
对测试集预测的结果左边为客户序号,predict为预测购买的可能性(推荐度),real为真是购买情况(0为未购买,1为已购买)
评价模型的好坏,对于少部分人购买(大部分预测都低于百分之50),很难用accurate去评价
举个例子,
真实情况是A类人购买率0.1,B类人购买率0.2,C类人购买率0.2。
即真实100个A,100个B,100个C分别购买为10,20,20
2个模型经过训练对A,B,C机器学习 股票分析,3类人的购买可能性预测为0.3,0.2,0.1;0.15,0.2,0.2模型认为A,B,C三类人都不会购买。
accurate为预测正确人数/总人数
accurate(模型1)=accurate(模型2)=250(250没买东西,模型预测所有人都不会购买)/300=83%
如果用accurate去评价,模型1的性能是等于模型2的。
但是显然模型2更符合真实情况,所以这里不再使用accurate来作为标准。
这里使用的方法是,对预测值进行排序,如果预测准确,那么可能性高的人一定会多买产品。通过下图来衡量模型的好坏,红色为随机推荐,绿色为安概率排序后推荐。
如果绿线开始上升越快,说明模型效果越好。
这图除了来衡量模型好坏,也是一个有用的结论:
对一个人群范围,可以先通过模型排序,然后选取一定范围进行营销活动,提高转换率。
这里用1000的人来做标准,之后的模型也使用这个数据来做判断标准。排序前推荐1000人,购买率为104/1000=10.4%,排序后推荐1000人,购买率为270/1000=27%,差距最大点为1362。在推荐1362人是使用排序算法都购买人数和随意推荐差距最大。
特征值的重要程度如下图,可以看出账户余额和年龄是最重要的2个特征值
通过dnn和xgboost建模(具体见py代码)
3种建模的效果比较
1000人时,实际购买人数如下图
3种取现
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





