
目录
1.背景
随着电商的不断发展,网上购物变得越来越流行。更多电商平台崛起,对于电商卖家来说增加的不只是人们越来越高的需求,还要面对更多强大的竞争对手。面对这些挑战,就需要能够及时发现店铺经营中的问题,并且能够有效解决这些实际的问题,从而提升自身的竞争力。
根据已有数据对店铺整体运营情况进行分析,了解运营状况,对未来进行预测,已经成为电商运营必不可少的技能。
2.分析目标
对一家全球超市4年(2011~2014年)的零售数据进行数据分析,分析目标如下:
①分析每年销售额增长率。
②各个地区分店的销售额。
③销售淡旺季。
④新老客户数。
⑤利用RFM模型标记用户价值。
3.数据准备
数据来源于数据科学竞赛平台Kaggle,网址为,总共51290条数据,24个字段。详情见下超市数据属性表。
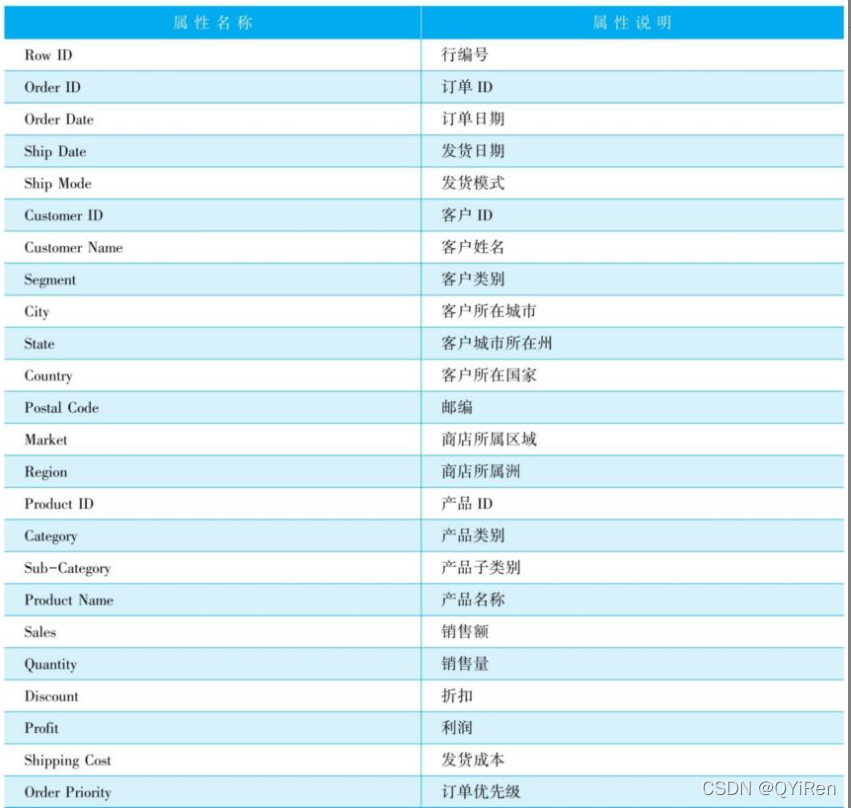
初步判断是否有缺失值,如下所示。

根据以上结果,对数据进行基本了解,24个字段中有7个字段是数字类型,这7个字段在计算时是不需要转换类型的,其他字段的数据都是object类型。在获取数据时要注意数据的类型,特别是日期字段的数据,整理数据时可以将其转换成时间格式,以方便获取数据。
同时发现数据缺失方面只有Postal Code(邮编)字段有缺失值,而该字段对分析并不会产生影响,可以不用处理。
4.数据清洗
数据清洗是数据分析的基础,也是最为重要的一步,因为数据清洗在提高了数据质量的同时也可以避免脏数据影响分析结果。
所谓数据清洗,实际上就是对缺失值、异常值的删除处理或填充处理,以及为了方便数据的获取和分析,对列名的重命名、列数据的类型转换或者是排序等操作。但是并不是所有的数据都需要将上述的所有操作都执行一遍,具体操作的选择可根据实际的数据和需求进行选定。
4.1查看是否含有缺失值
通过info函数了解到在数据集中的只有Postal Code字段含有缺失值。结果返回的是所有字段不为空的数据个数。
判断每个any()字段中的数据是否含有缺失值isna()数据分析 销售,如以下所示。
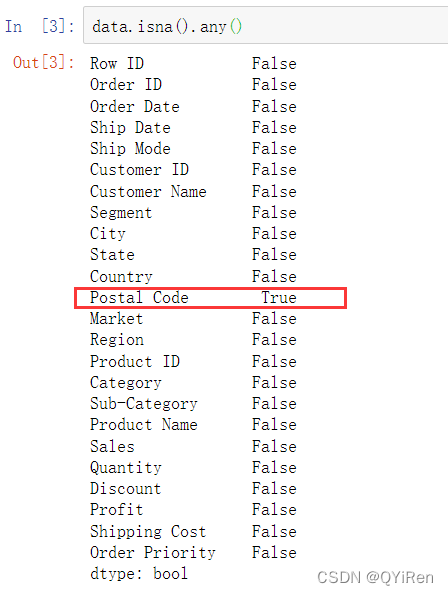
使用isna( ).any( )方法会返回一个仅含True和False这两种值的Series,这个方法主要是用来判断所有列中是否含有空值。通过两次方法验证空值,得出的结论一致,只有Postal Code字段含有缺失值。而该字段并不在分析范围内,可以不处理该字段的缺失值,同时也保留了该字段所在数据其他字段的数据,这样可以确保分析的准确度。
4.2查看是否有异常值
在查看数据的缺失值之后还需要检查一下数据中是否含有异常值,Pandas的describe( )可以用来统计数据集的集中趋势,分析各行列的分布情况,因此在查看异常值时会经常用到,如以下代码所示。
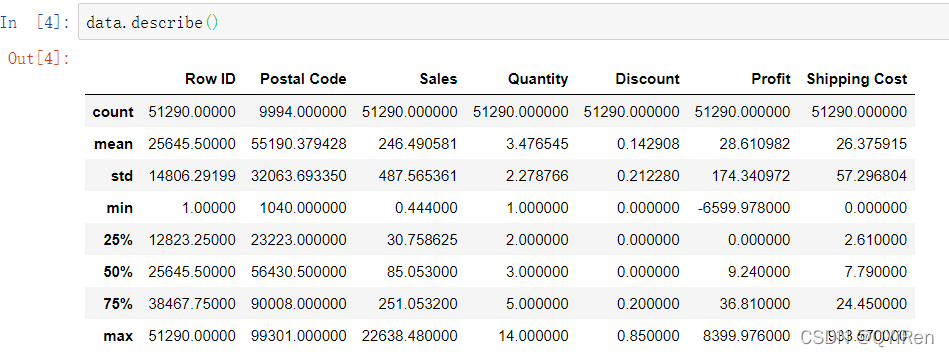
describe( )函数会对数值型数据进行统计,输出结果指标包括count、mean、std、min、max及下四分位数,中位数和上四分位数。通过观察该结果发现数据集并无异常值存在。
4.3数据整理
由于很多分析的维度都是建立在时间基础上的,通过数据类型的结果发现数据中的时间是字符串类型的,所以需要处理时间的类型,将其修改成datetime类型,如以下代码所示。
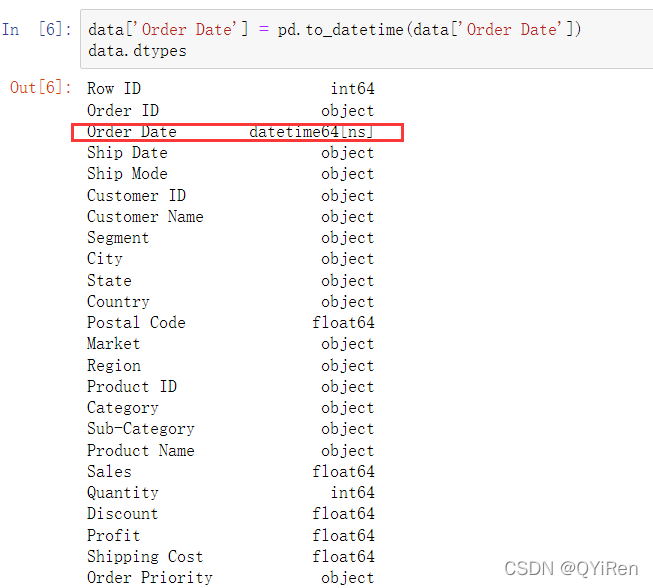
上面代码将Order Date(订单日期)列的数据类型成功修改成了datetime类型,因为通过datetime可以快速增加数据的维度,如年、月和季度等,如以下代码所示。
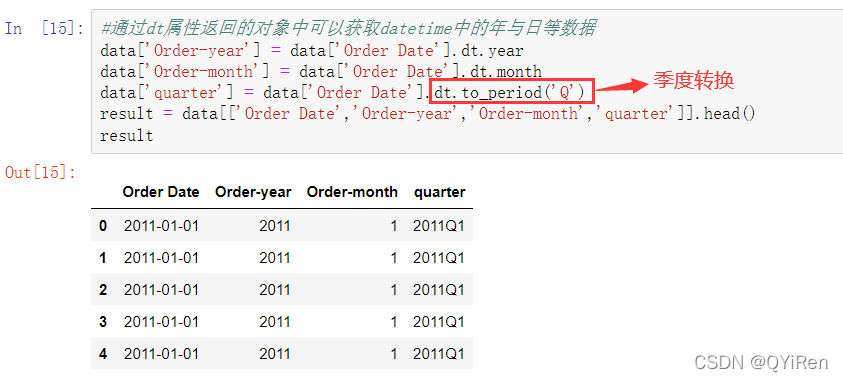
这样整理数据的优点已经一目了然,再根据不同的时间维度去获取数据时,会更加便捷。也可以根据不同的需求进行排序等操作,例如,需要获取2011年销售额前10的客户ID数据,如以下代码所示。
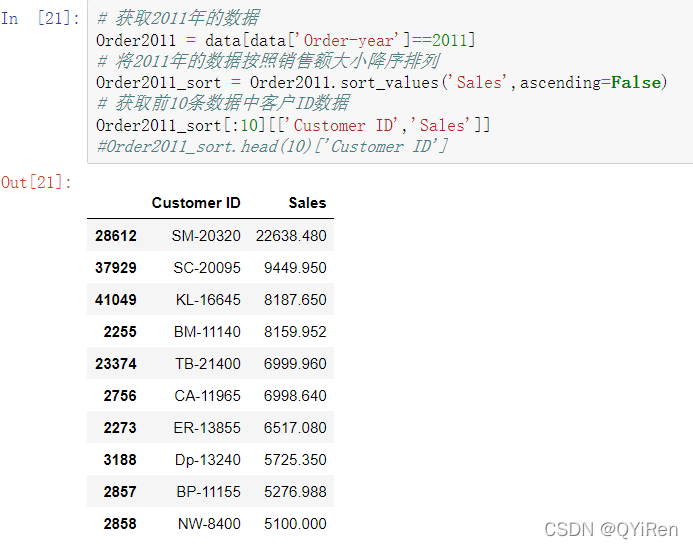
5.具体目标分析 5.1分析每年销售额的增长率
销售增长率是企业本年销售收入增长额同上年销售收入总额之比。
本年销售增长额为本年销售收入减去上年销售收入的差额,它是衡量企业经营状况和市场占有能力、预测企业经营业务拓展趋势的重要指标,也是企业扩张增量资本和存量资本的重要前提,该指标越大,表明其增长速度越快,企业市场前景越好。同样,也可以根据销售额的平均增长率,对下一年的销售额进行预测。
计算公式如下。或者将计算公式改型为(本年销售额/上年销售额 - 1),计算与原表达式一致。
现在根据当前的数据对该超市进行2011~2014年的销售增长率的趋势分析,并给出下一年的销售建议。
将数据按照年份进行分组,并计算出每年的销售总额,如以下代码所示。
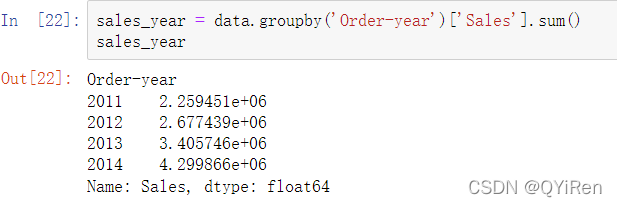
根据销售额增长率公式分别算出2012年、2013年和2014年的销售额增长率,如以下代码所示。
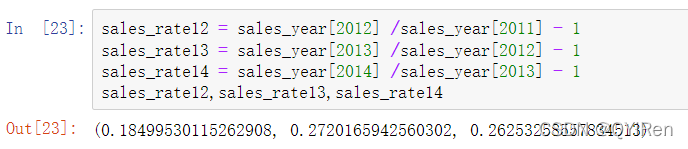
若想使用百分数的结果形式,可以用下面的方式将小数改成百分数,如以下代码所示。
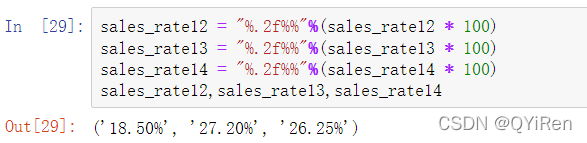
用图表呈现每一年的销售额和对应的增长率。用表格展示销售额和对应的增长率,如以下代码所示。
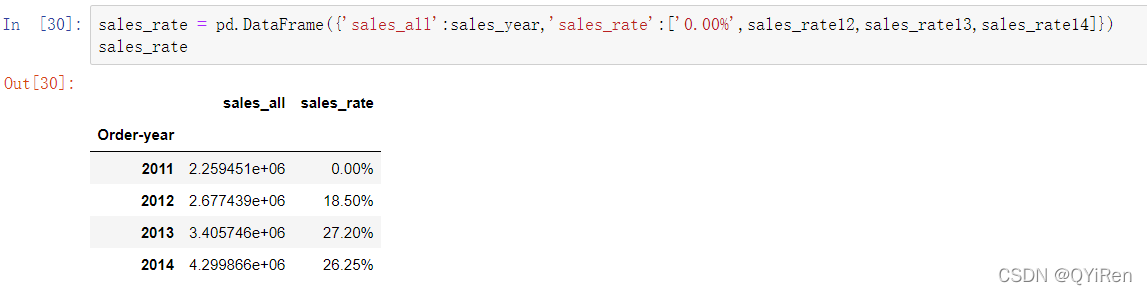
为了能更加直观地展示数据,可以将数据进行图像展示,如以下代码所示。
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
# 由于百分比数据不支持绘图,所以重新求占比
sales_rate_12 = sales_year[2012] / sales_year[2011] - 1
sales_rate_13 = sales_year[2013] / sales_year[2012] - 1
sales_rate_14 = sales_year[2014] / sales_year[2013] - 1
# 设置风格
plt.style.use('ggplot')
sales_rate = pd.DataFrame({'sales_all':sales_year,'sales_rate':[0,sales_rate_12,sales_rate_13,sales_rate_14]})
y1 = sales_rate['sales_all']
y2 = sales_rate['sales_rate']
x = [str(value) for value in sales_rate.index.tolist()]
# 新建figure对象
fig = plt.figure()
# 新建子图1
ax1 = fig.add_subplot(1,1,1)
# ax2与ax1共享x轴
ax2 = ax1.twinx()
ax1.bar(x,y1,color='blue')
ax2.plot(x,y2,marker='*',color='r')
ax1.set_xlabel('年份/年')
ax1.set_ylabel('销售额/元')
ax2.set_xlabel('增长率')
ax2.set_ylabel('销售额与增长率')
plt.title('销售额与增长率')
plt.show()结果如下。
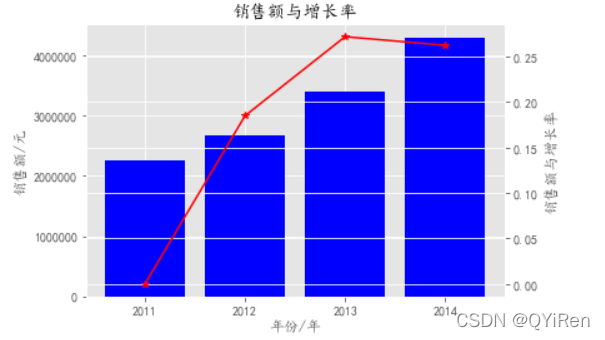
将销售额和增长率绘制在一个图中,使用twinx( )方法共享了x轴,并且建立了两个y轴,左侧的y轴代表的是销售额,右侧的y轴代表是对应的销售额增长率。
初步分析:结合销售额与增长率2011~2014年该超市的销售额在稳步上升,说明企业市场占有能力在不断提高,2012~2014年增长率在增长后趋于平稳,说明企业经营在逐步稳定。同样根据销售和增长率,可以初步制定下一年度的销售额指标是530万元左右,当然具体销售额指标的制定还要结合公司的整体战略规划。
5.2各个地区分店的销售额
了解了该超市的整体销售额情况之后,再对不同地区分店的销售额占比情况进行分析,以便对不同地区分配下一年度的销售额指标,和对不同地区分店采取不同的营销策略
首先按照Market字段进行数据分组,整体看一下不同地区分店2011~2014年的总销售额占比,如以下代码所示。
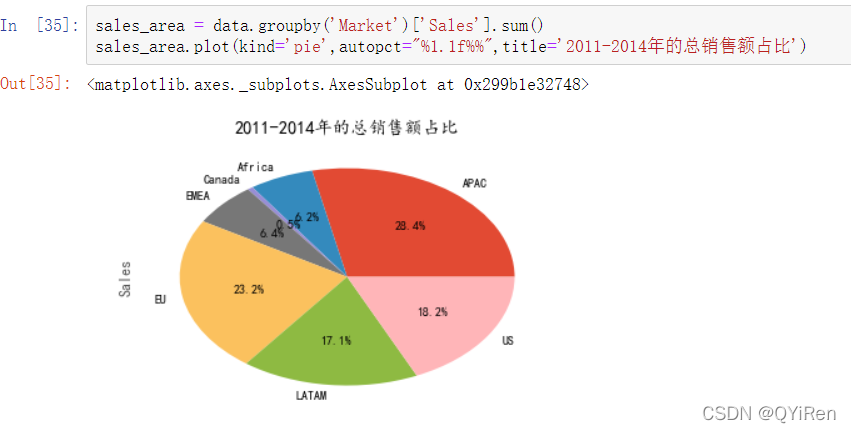
从占比图中可以看出APAC地区销售额占比最大,为28.4%,而Canada地区的销售额占比最少,只有0.5%,说明市场几乎没有打开,可以根据公司的总体战略部署进行取舍,从而根据销售额占比分配下一年的销售额指标。
接下来,为了能更清晰地了解各地区店铺的经营状况,可以再对各地区每一年的销售额进行分析,如以下代码所示。
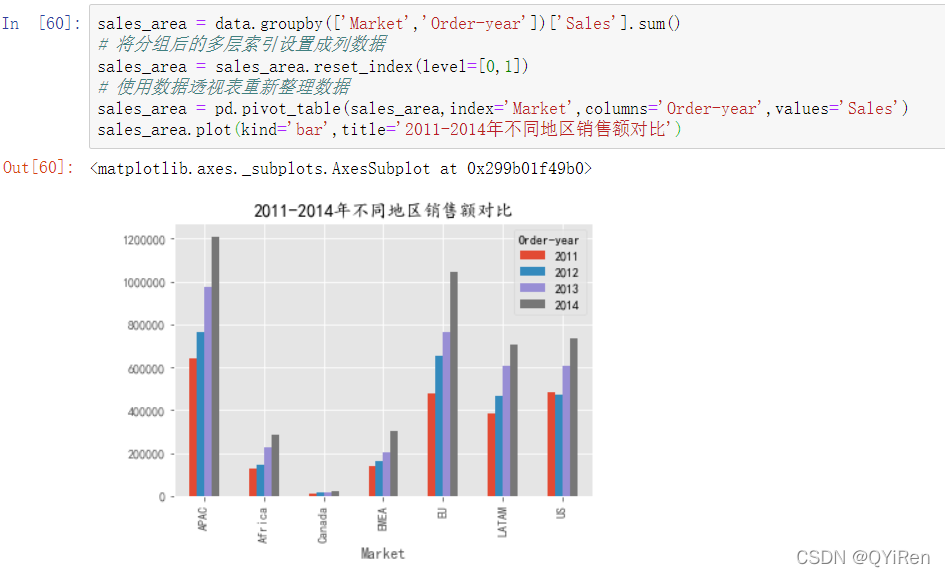
下面是另一种操作:(两者效果一样)
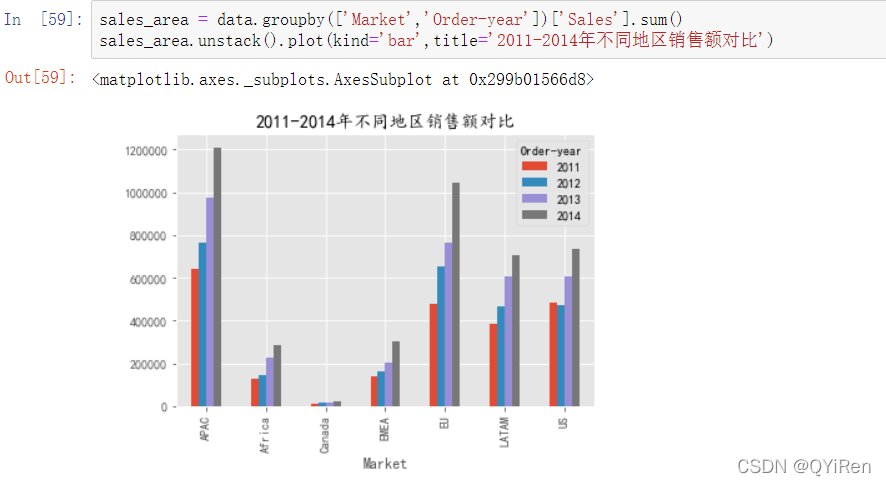
从图可以看出,各个地区2011~2014年的销售总额均是增长的趋势,APAC地区和EU地区的增长速度比较快,可以看出市场占有能力也在不断增加,企业市场前景比较好,下一年可以适当加大运营成本,其他地区可以根据自身地区消费特点,参考上面两个地区的运营模式。
根据不同类型产品在不同地区的销售额占比,可以适当地改善经营策略,如以下代码所示。
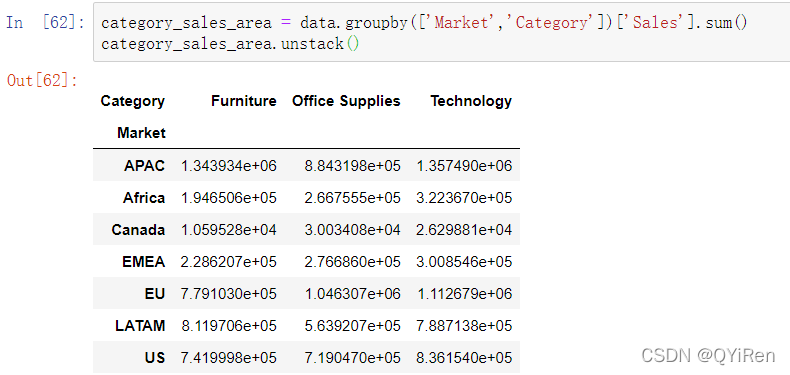
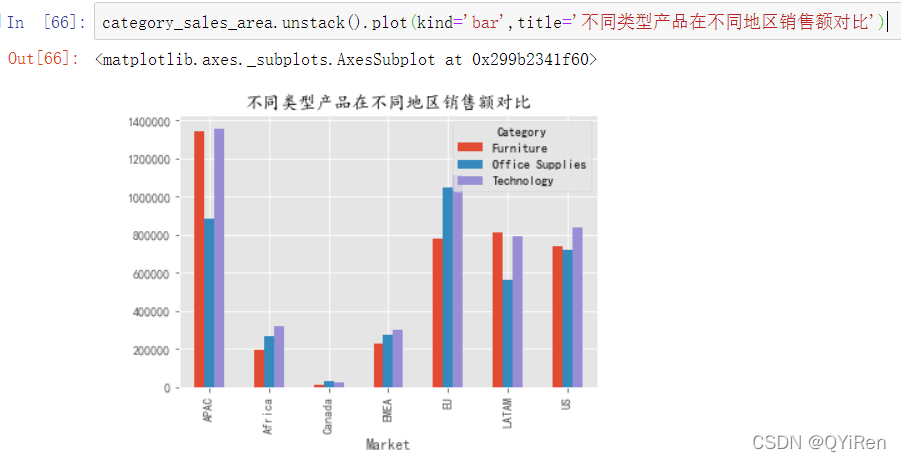
所有产品按照三个大的类型进行了区分,分别是Furniture(家具)、Technology(电子产品)和Office Supplies(办公用品)。通过上图大致可以看出,在各大地区销售额都比较高的是电子产品,可以根据企业的整体战略部署适当加大对各地区该品类的投入,以便扩大优势。
5.3销售淡旺季分析
根据超市的整体销售额情况和不同类型产品在不同地区的销售情况,再对每年每月的销售额进行分析,根据不同月份的销售情况,找出重点销售月份,从而制定经营策略与业绩月度及季度指标拆分。
为了方便观察数据,需要将数据根据年和月进行分组,并计算出每年每月的销售总额,再将其制作成年、月、销售额的数据透视表,最后通过折线图进行展示,如以下代码所示。
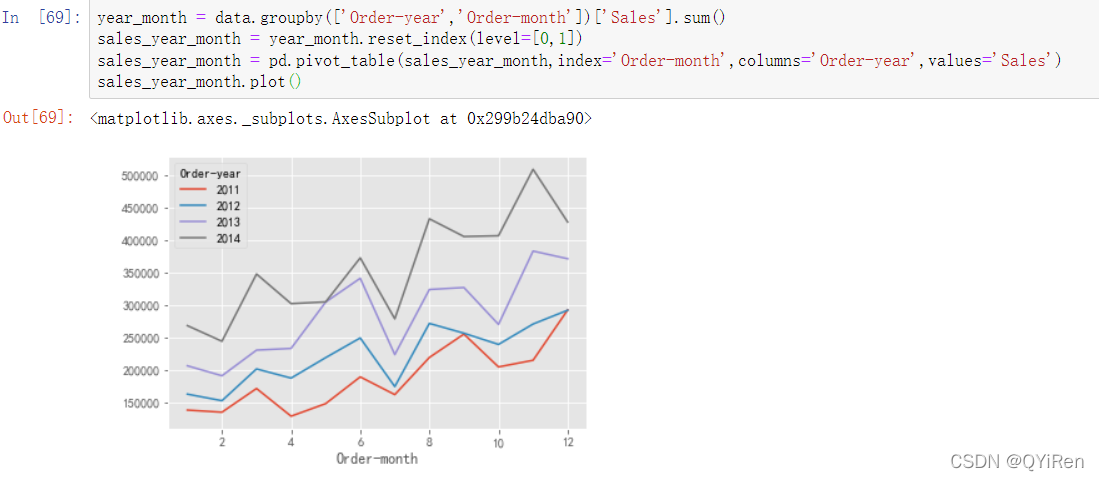
通过图基本可以看出,该超市2011~2014年每一年的销售额同比上一年都是上升趋势,而且很容易发现该超市的旺季是下半年,另外在上半年的销售额中发现6月份的销售额也是比较高的,所以可以在6月份开始加大一些运营成本,进而更大一步提高销售额,但是需要注意是下半年的7月份和10月份销售额会有明显的下降,可以针对这些下降的月份多举行一些营销活动。
5.4新老客户数
企业的老客户一般都是企业的忠诚客户,有相对较高的黏度,也是为网站带来价值的主要客户群体;而新客户则意味着企业业务的发展,是企业价值不断提升的前提。可以说“老客户是企业生存的基础,新客户是企业发展的动力”,企业的发展战略往往是在基于保留老客户的基础上不断地提升新客户数。
分析新老客户的意义就在于:通过分析老客户,来确定企业的基础是否稳固,是否存在被淘汰的危机;通过分析新客户,来衡量企业的发展是否顺利,是否有更大的扩展空间。
根据该企业的新老客户分布,对超市客户维系健康状态进行了解。在分析之前需要定义一下新客户,将只要在该超市消费过的客户就定义为老客户,反之为新客户。由于2011年的数据为起始数据,根据定义大部分客户皆为新客户,其数据没有分析价值,如以下代码所示。
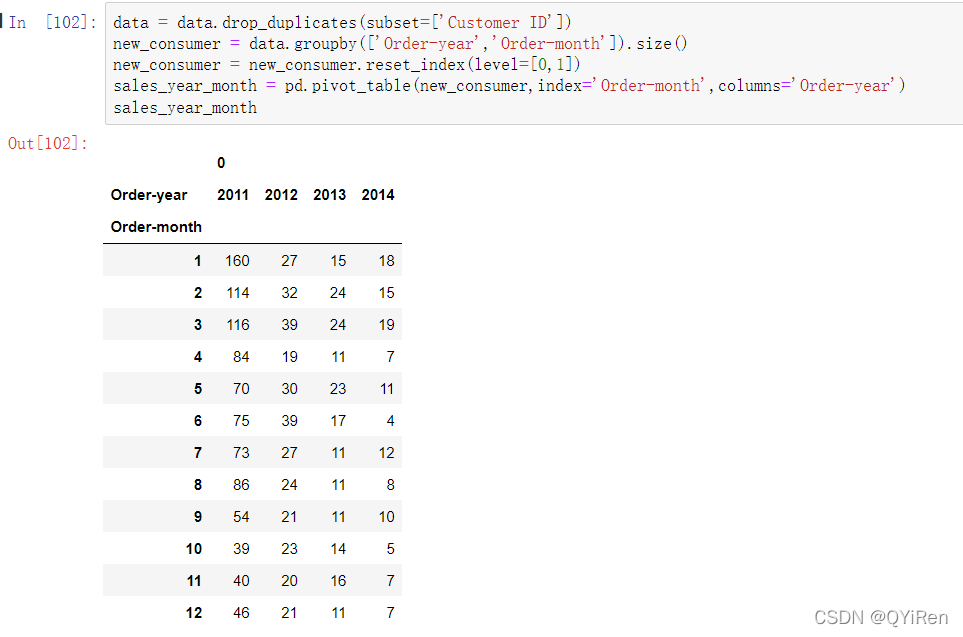
代码解析如下。
1)根据Customer ID列数据进行重复值的删除,保证数据集中所有的客户ID都是唯一的。
2)根据Order-year和Order-month两个字段进行分组,并使用size( )函数对每个分组进行计数。
3)为了方便使用透视表对数据进行整理,需要先将索引转化成数据列。
4)使用数据透视表功能,将年份作为数据的列索引,月份作为数据的行索引。
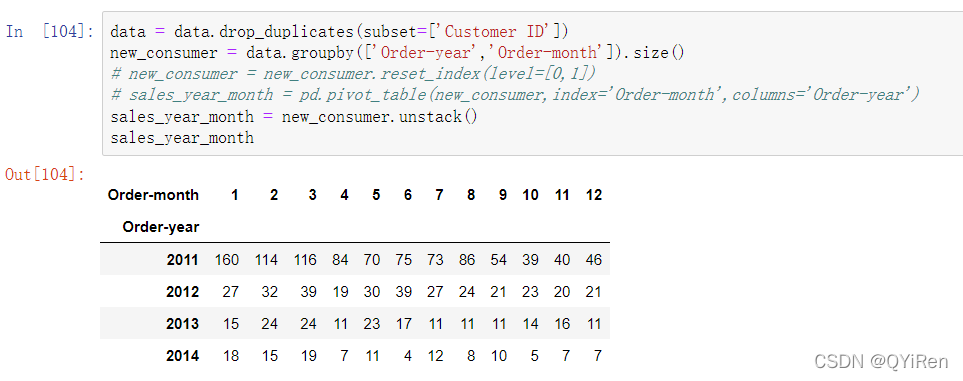
根据图表可以看出,2011~2014年每一年的新增客户数是逐年减少的趋势,可以看出该网站对保持老客户是有效的,网站的运营状况较为稳定。但是,新客户获取率比较低,可以不定期地进行主动推广营销,从而增加新客户数。
或者这样操作:
5.5用户价值度RFM模型分析
目前几乎所有企业业务都是以客户的需求为主导,都希望服务好客户,促进销售转化,最好能让客户对产品和品牌产生黏性数据分析 销售,长期购买。于是市场和运营人员都会绞尽脑汁的做活动、上新品、蹭热点、做营销,不断地拓展客户和回访以维系客户感情。但是,这些工作除了少数运气好的之外,大部分效果都不是很好,真正有价值的客户没有几个。不同阶段、不同类型的客户需求点不同,有的客户图便宜,有的客户看新品,有的客户重服务,粗狂式的营销运营方法最后的结果往往都是事与愿违,企业的资源利润无法发挥其最大效用去创造最大化的利润。
那么如何进行客户价值分析,甄选出有价值的客户,让企业精力集中在这些客户上,有效地提升企业竞争力使企业获得更大的发展呢?解决的方法很简单,就是客户精细化运营。通过各类运营手段提高不同类型的客户在产品中的活跃度、留存率和付费率。而如何将客户从一个整体拆分成特征明显的群体决定了运营的成败。在客户价值领域,最具有影响力并得到实证验证的理论与模型有: 客户终生价值理论、客户价值金字塔模型、策论评估矩阵分析法和RFM客户价值分析模型等。这里介绍一个最经典的客户分群模型,即RFM模型。
RFM的含义如下。
1)R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
2)F(Frequency):值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
3)M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
RFM模型是衡量客户价值和用户创利能力的经典工具,依托于客户最近一次购买时间、消费频次及消费金额。在应用RFM模型时,要有客户最基础的交易数据,至少包含客户ID、交易金额和交易时间3个字段。
根据R、F、M这3个维度,可以将客户分为以下8种类型,如图所示。
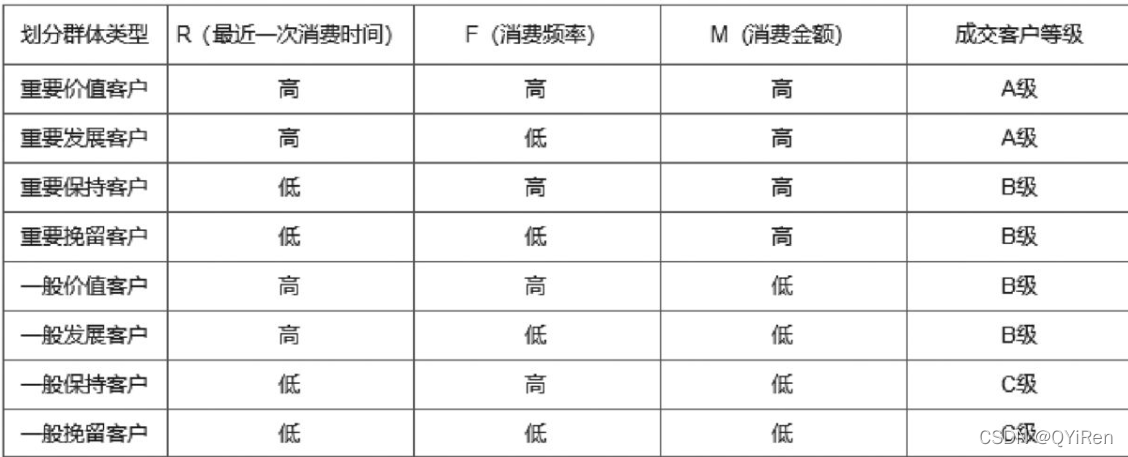
在这个表中将每个维度都分为高和低两种情况,进而将客户群体划分为8种类型,而这8种类型又可以划分成A、B、C3个等级。例如,某个客户最近一次消费时间与分析时间的间隔比较大,但是该客户在一段时间内的消费频次和累计消费总金额都很高,这就说明这个客户就是RFM模型中的重要保持客户,为了避免该客户的流失,企业的运营人员就要专门针对这种类型的客户设计特定的运营策略,这也就是RFM模型的核心价值。
R、F、M每一个值是如何计算的。
例如,该超市某用户的2014年的消费记录见表。
在这个数据中列出了5个字段,根据RFM模型只需要关注Customer ID、OrderDate、Sales 3个字段的计算即可,假设分析的时间是5/1/2014,下面分别计算该客户的R、F、M的值。
1)R:5/1/2014 - 3/9/2014 = 53。
2)F:消费次数 = 2。
3)M:消费金额 = 128.736 + 795.408。
计算出结果之后还是无法直接通过R、F、M单独的数据衡量客户的价值。那么如何根据这3个数值,分别对不同维度进行高低等级的划分?
当R、F、M每个值计算出来之后,可以使用评分的方式对每一个维度的数据进行评分。然后再根据所有数据的平均评分,对每一个评分进行高低等级的标记。
评分方式就是根据R、F、M值的特征,设定数值的区间,然后给每个区间对应不同的评分值,把每一个统计出来的数据值,对应上一个相应的评分值。R的评分值设置与F、M的略有不同,因为R的值越大说明与最近一次的购买时间间隔越大,所以可以将R、F、M值的评分机制设置如下。
1)R:R值越大,评分越小。
2)F:F值越大,评分越大。
3)M:M值越大,评分越大。
当R、F、M3个维度对应的评分值设置完成之后,再利用每个维度评分值的平均值,对数据的R、F、M进行高低维度的划分。即当评分值大于等于对应的平均值时表示高,同理当评分值小于对应的平均值时表示低。这样就可以将数据整理成上面8种类型的表的结构,进而得到该用户是什么类型的客户。
下面开始利用Python探索该超市2014年的客户群体。
第1步,分析的数据是该超市2014年全年的数据,并假设统计的时间为2014年12月31日。现在利用下面代码获取2014年全年的数据,如以下代码所示。
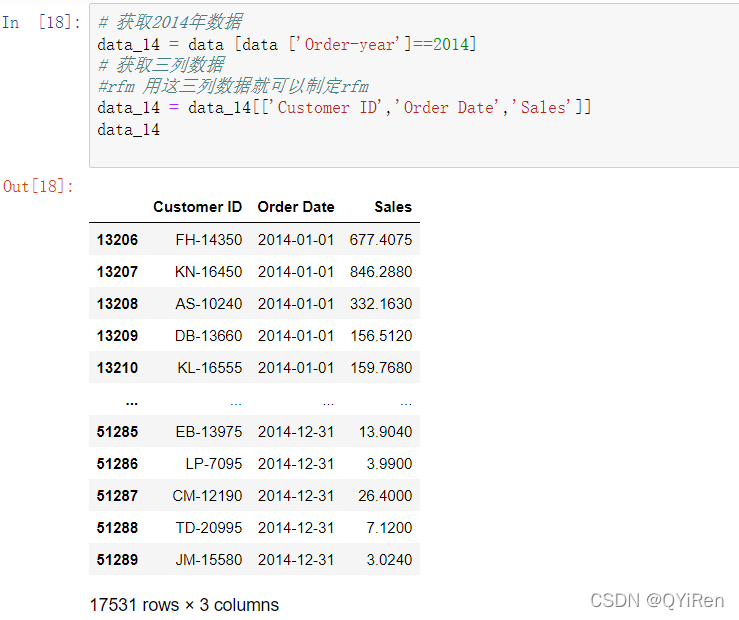
第2步,对2014年数据按照Customer ID进行分组,然后再对每个分组的数据按照Order Date进行排序并获取出日期最大的那个数据,如以下代码所示。
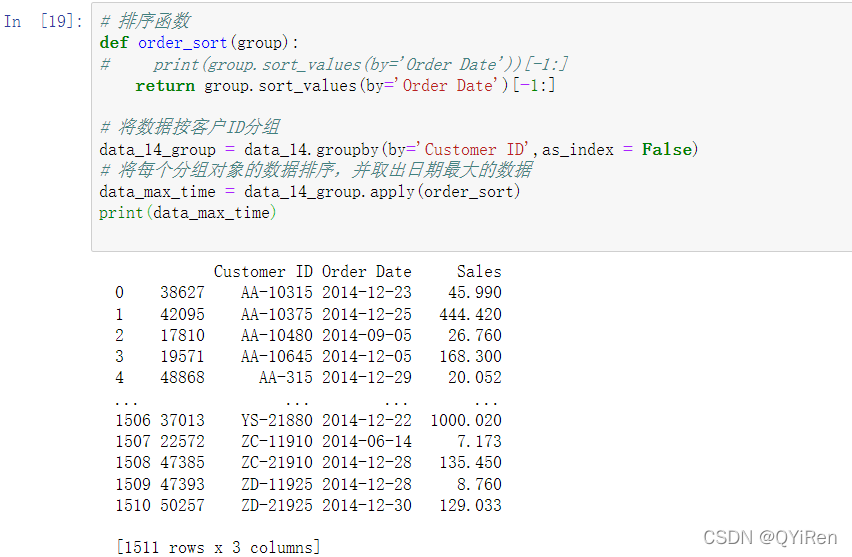
第3步,经过分组之后同样可以快速算出RFM模型中的F(购买次数)和M(销售额总数),如以下代码所示
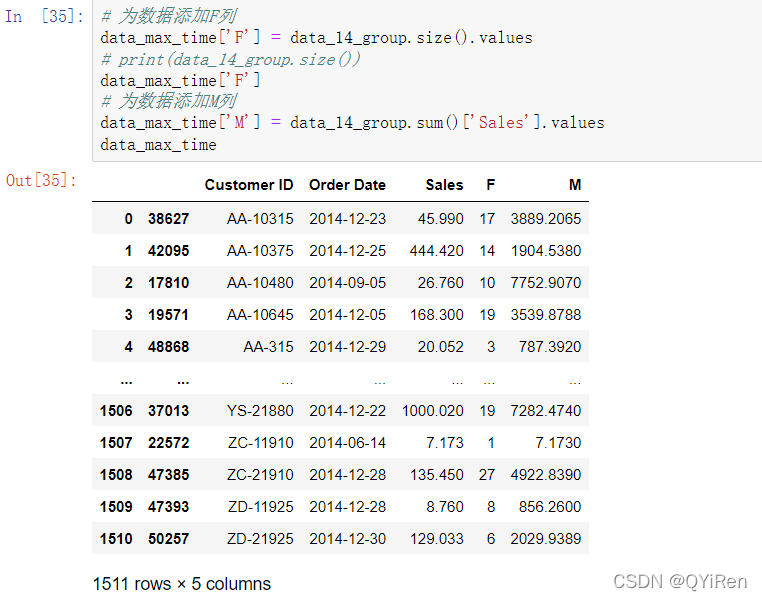
第4步,目前已经获取到了2014年每个客户最后一次的购买时间了,现在需要根据假定时间计算出最近一次交易时间的间隔,如以下代码所示。
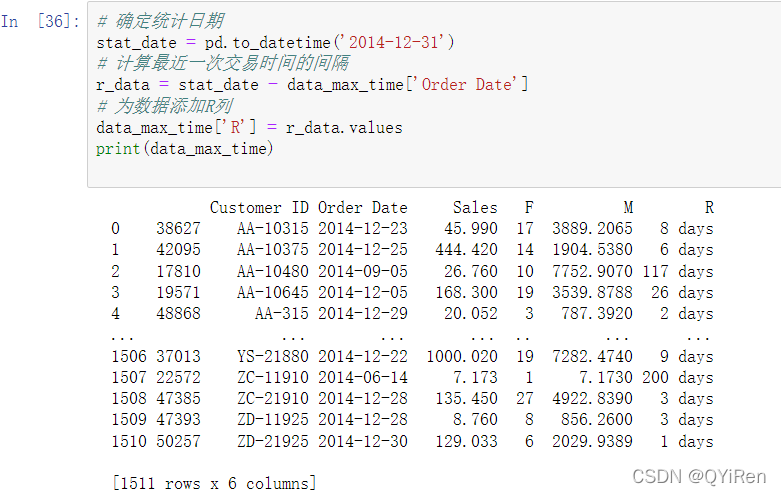
第5步,经过上面四步分别计算出了RFM各个维度的数值,现在可以根据经验及业务场景设定分值的给予区间。本项目中给定F的区间为[0,5,10,15,20,50],然后采用5分制的评分规则与上面分值区间一一对应,例如,1~5对应的为1、5~10对应的为2,依此类推,如以下代码所示。
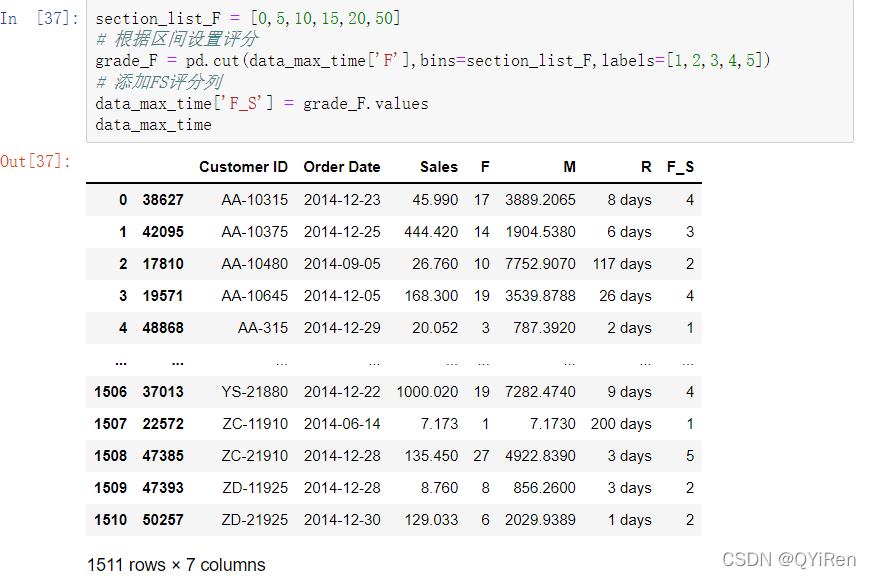
第6步,根据第5步的思路,首先确定M维度的区间为[ 0,500,1000,5000,10000,30000],然后采用5分制的评分规则与上面分值区间一一对应。同理,确定R维度的区间为[-1,32,93,186,277,365],但是R维度所对应的评分顺序应该与F和M的相反,如以下代码所示。
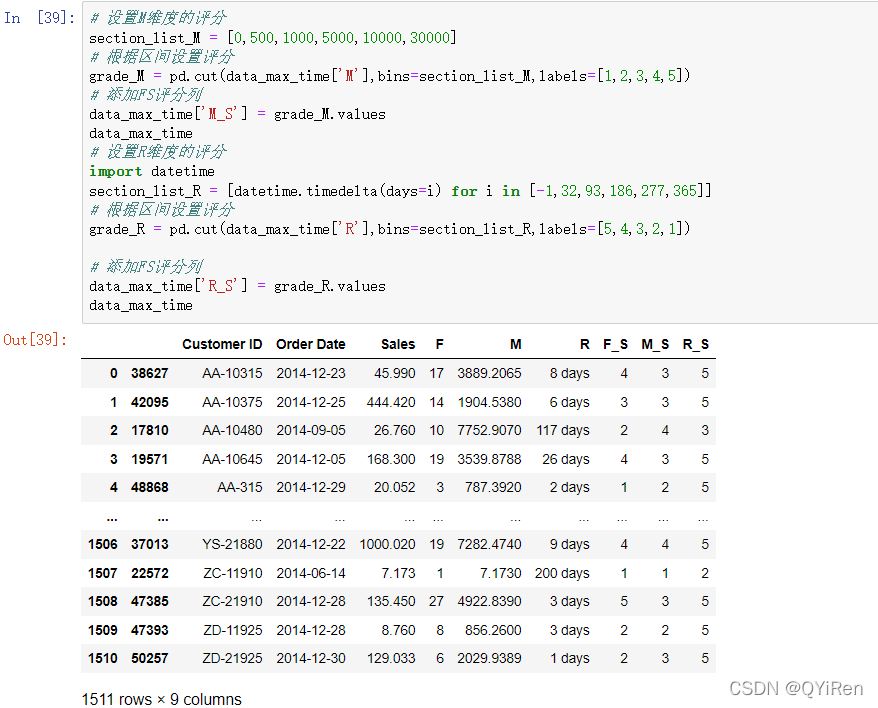
第7步,上面给每条数据的RFM都设置了对应的评分,现在需要根据每一个维度计算出对应的平均分,然后用对应的分数与平均分进行对比,大于平均分的值标记成1,同理小于平均分的值标记成0,如以下代码所示。
# 设置F维度高低值
data_max_time['F_S'] = data_max_time['F_S'].values.astype('int')
# 根据评分平均分设置判别高低
grade_avg = data_max_time['F_S'].values.sum()/data_max_time['F_S'].count()
grade_avg
# # 将高对应为1,低设置为0
data_F_S = data_max_time['F_S'].where(data_max_time['F_S']>grade_avg,0)
data_max_time['F_high-low']=data_F_S.where(data_max_time['F_S']grade_avg,0)
data_max_time['M_high-low']=data_M_S.where(data_max_time['M_S']grade_avg,1).values
data_max_time 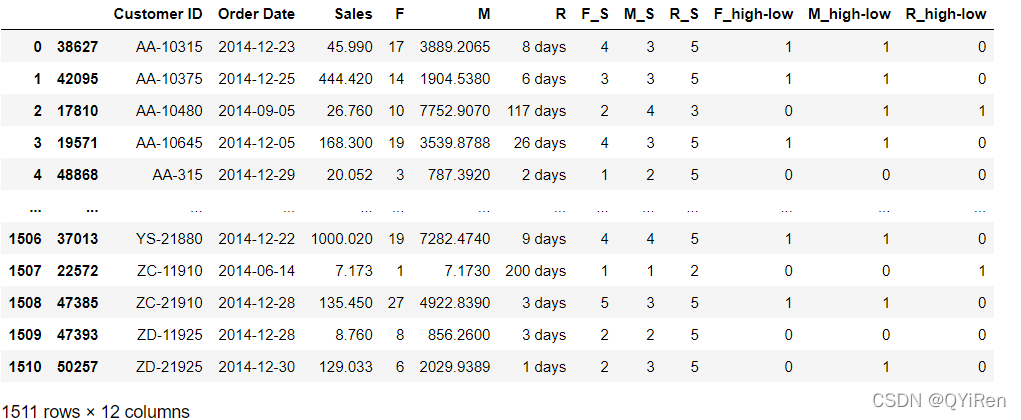
第8步,现在基本完成对每个数据RFM高低值的设置,接下来就可以根据RFM的高低值对每个客户进行类型标记了,如以下代码所示。
# 截取部分列数据
data_rfm = data_max_time.loc来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。
行业消费趋势分析")




