
1.配置pom包
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.配置application.yml kafka部分:
kafka: # 指定kafka 代理地址,可以多个
bootstrap-servers: hadoop:9092, slave1:9092
template: # 指定默认topic id
default-topic: producer
listener: # 指定listener 容器中的线程数,用于提高并发量
concurrency: 5
consumer:
group-id: myGroup # 指定默认消费者group id
client-id: 200
max-poll-records: 200
auto-offset-reset: earliest # 最早未被消费的offset
producer:
batch-size: 10 # 每次批量发送消息的数量
retries: 3
client-id: 200
3.定义生产者类:
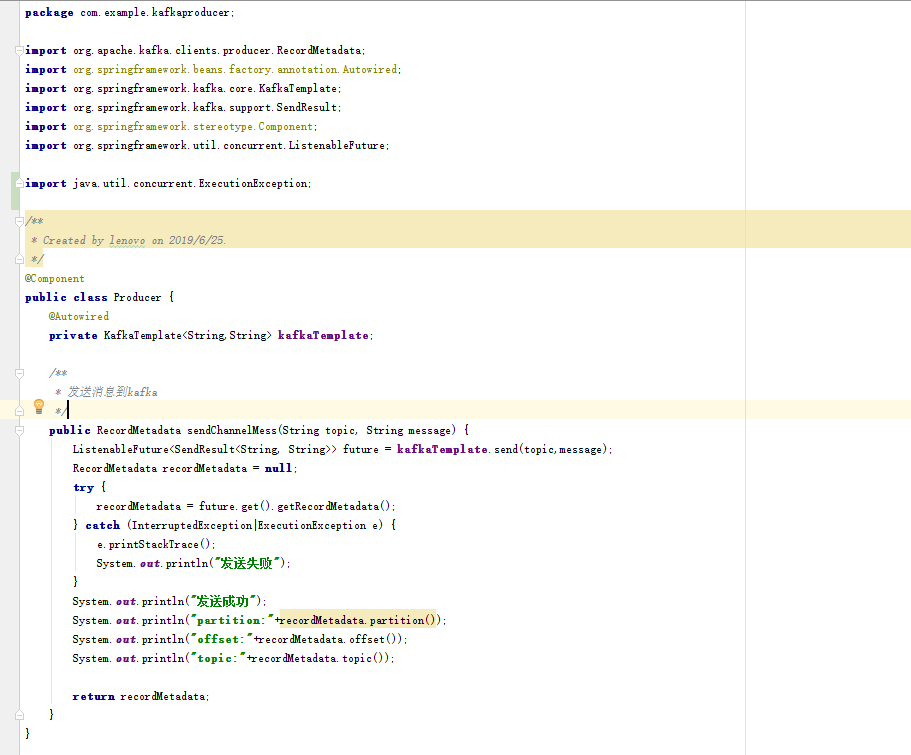
试看结束,如继续查看请付费↓↓↓↓
打赏0.5元才能查看本内容,立即打赏
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





