
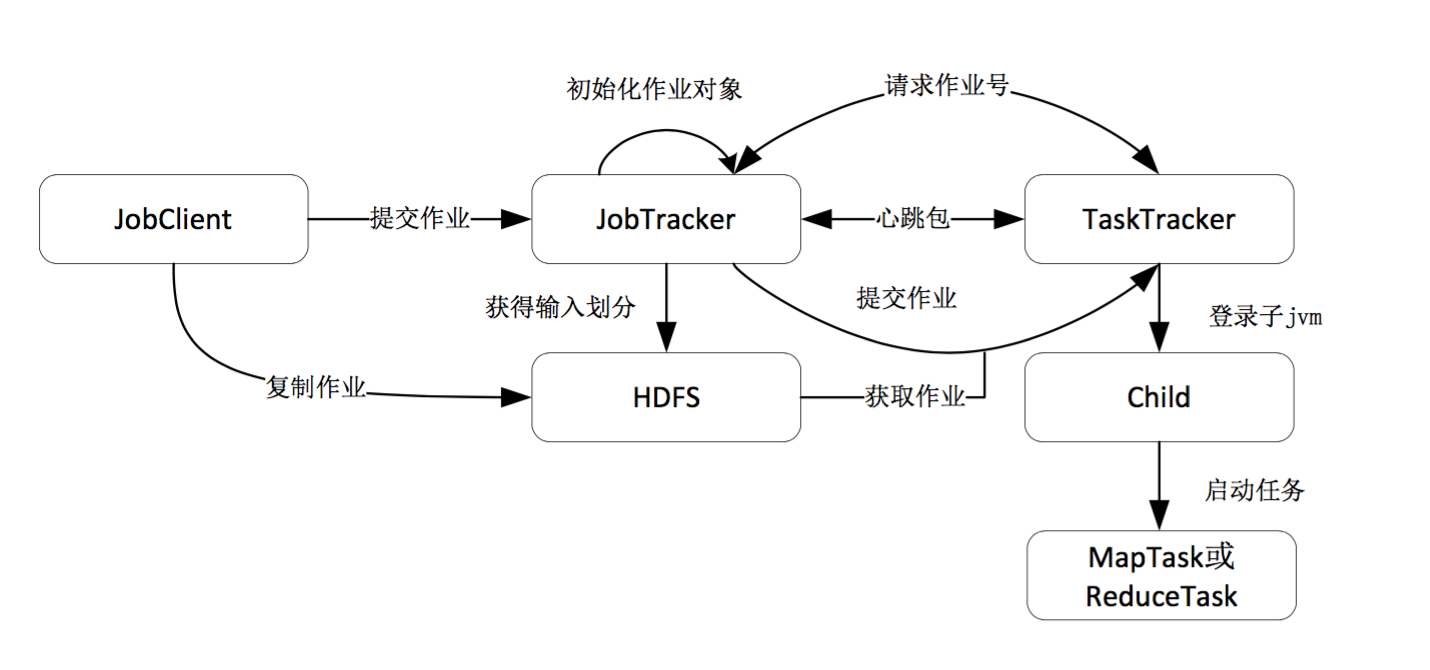
作业调度器是hadoop核心组件。对于目前的Hadoop任务调度,分配任务是一个“拉”的过程,即每一个TaskTracker节点主动向JobTracker节点请求作业的任务,而不是当有新作业的时候,JobTracker节点主动给TaskTracker节点分配任务。集群运行期间每个TaskTracker都要向JobTracter汇报状态信息(默认时间间隔为3秒),信息包括TaskTracker自身的状态属性、运行在TaskTracker上每个作业的状态、slot的设置情况等。这些状态信息只是源数据,提供给JobTracker做分析决策使用。Hadoop MapReduce并行计算框架广泛应用于大规模数据并行处理,hadoop的基本设计更多地强调了数据的高吞吐率。
作业调度策略主流的有三种:
默认调度算法FIFO 队列策略
即先来先服务,这种调度算法简单,JobTracker的工作负担小。但是hadoop 数据分析,忽略了不同作业的需求差异。例如如果类似对海量数据进行统计分析的作业长期占据计算资源,那么在其后提交的交互型作业有可能迟迟得不到处理,从而影响到用户的体验。
计算能力调度算法Capacity Scheduler(Yahoo 开发)
(1)Capacity Scheduler 中可以定义多个作业队列,作业提交时将直接放入到一个队列中,每个队列中采用的调度策略是FIFO算法。
(2)每个队列都可以通过配置获得一定数量的task tracker资源用于处理map/reduce操作,调度算法将按照配置文件为队列分配相应的计算资源量。
(3)该调度默认情况下不支持优先级,但是可以在配置文件中开启此选项,如果支持优先级,调度算法就是带有优先级的FIFO。
(4)不支持优先级抢占,一旦一个工作开始执行,在执行完之前它的资源不会被高优先级作业所抢占。
(5)对队列中同一用户提交的作业能够获得的资源百分比进行了限制以使同属于一用户的作业不能出现独占资源的情况.
Capacity Scheduler能有效地对hadoop集群的内存资源进行管理,以支持内存密集型应用。作业对内存资源需求高时,调度算法将把该作业的相关任务分配到内存资源充足的task tracker上。在作业选择过程中,Capacity Scheduler会检查空闲的tasktracker上的内存资源是否满足作业要求。Tasktracker上的空闲资源(内存)数量值可以通过tasktracker的内存资源总量减去当前已经使用的内存数量得到,而后者包含在tasktracker向jobtracker发送的周期性心跳信息中。
公平份额调度算法Fair Scheduler(Facebook开发)
Facebook要处理生产型作业(数据统计分析,hive)、大批处理作业(数据挖掘、机器学习)、小型交互型作业(hive查询),不同用户提交的作业型在计算时间、存储空间、数据流量和相应时间上都有不同需求。为使hadoop mapreduce框架能够应对多种类型作业并行执行,使得用户具有良好的体验,Facebook公司提出该算法。
Fair Scheduler调度中,只有一个作业执行时,它将独占集群所有资源。有其他作业被提交时会有TaskTracker被释放并分配给新提交的作业,以保证所有的作业都能够获得大体相同的计算资源。
作业池:
为每一个用户建立一个作业池,用户提交的作业将会放进一个能够公平共享资源的pool(池)中,每个作业池设定了一个最低资源保障,当一个池中包含job时,它至少可以获得minmum share的资源(最低保障资源份额机制)。
池中的作业获得一定份额的资源,可以通过配置文件限制每个池中作业数量,缺省情况下,每个作业池中选择将要执行的作业的策略是FIFO策略,先按照优先级高低排序,然后再按照提交时间排序。
不足之处:
Fair Scheldure为每个作业定义了一个deficit指标,Deficit是一个作业在理想情况下的获得的计算资源和实际中获得的计算资源之间的差距。Fair Scheduler会每隔几百毫秒观察每个作业有多少任务已经在这个时间间隔内执行,并将结果与它的资源份额比较,一更新该作业的deficit值。一旦有空闲的task tracker出现,首先分配给当前具有最高deficit值得作业。
例如:如果系统中存在着尚未获得最低资源保障的作业池,那么该池中的作业将会优先调度,而选择池中的作业需要根据他们的deficit来决定。这样做是为了尽可能满足作业池最低保障资源份额的限制。
hadoop已经成为一个技术生态,有很强的开放性和可扩展性,如果有兴趣研究hadoop源码,我们也可以自己实现一套作业调度算法。
HDFS存储原理
简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
特点
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
架构介绍
HDFS是Master和Slave结构,分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode
是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
NameNode内存中存储的是fsimage+edits。
SecondaryNameNode
是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
SecondaryNameNode负责定时默认1小时,从NameNode上,获取fsimage和edits来进行合并,然后再发送给NameNode。减少NameNode的工作量。
DataNode
Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份和冷备份区别
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
HDFS读写原理
以下原理介绍HDFS按默认配置
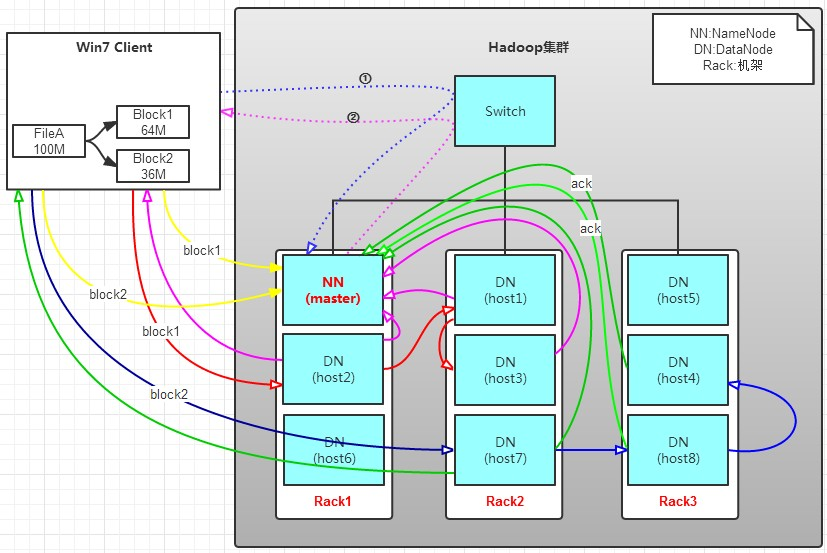
写操作
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块hadoop 数据分析,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①——>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②———>。
Block1: host2,host1,host3
Block2: host7,host8,host4
存储节点寻找原理是什么?
NameNode具有RackAware机架感知功能,这个可以配置。若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。流式写入过程如下:
通过分析写过程,我们可以了解到:
读操作
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:优选读取本机架上的数据。
MapReduce原理
从一个有趣的例子说起:你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃?
MapReduce方法则是:
MapReduce合并了两种经典函数:
映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
化简(Reducing )遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
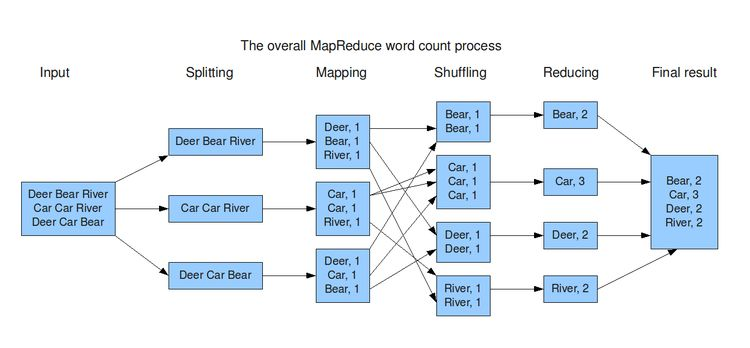
下图描述了wordCount的过程:
shuffling过程
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
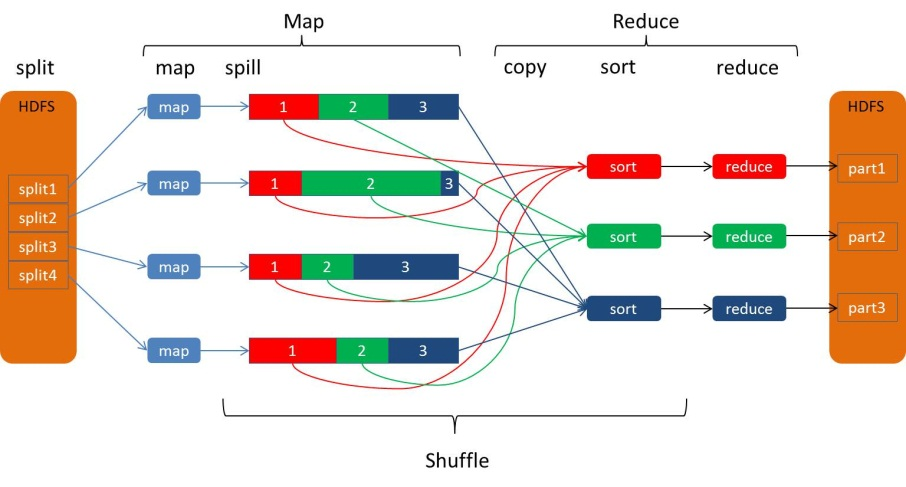
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:
Spill过程
Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
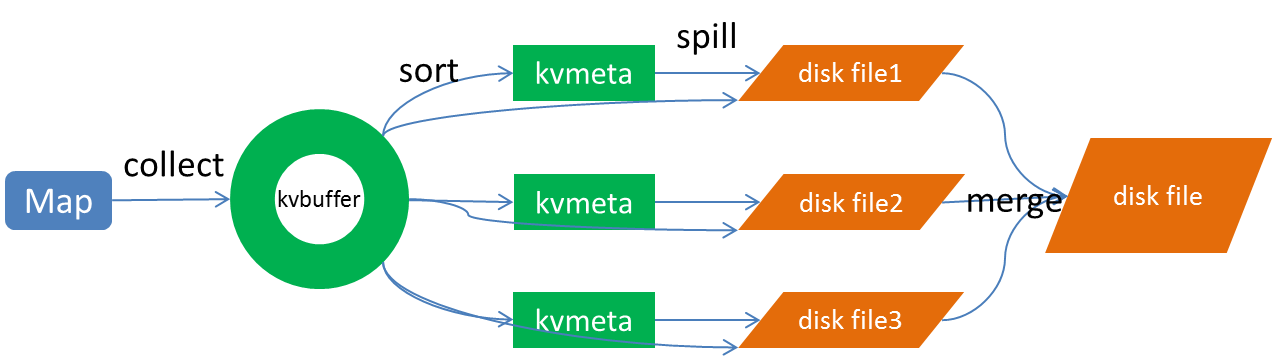
Collect
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
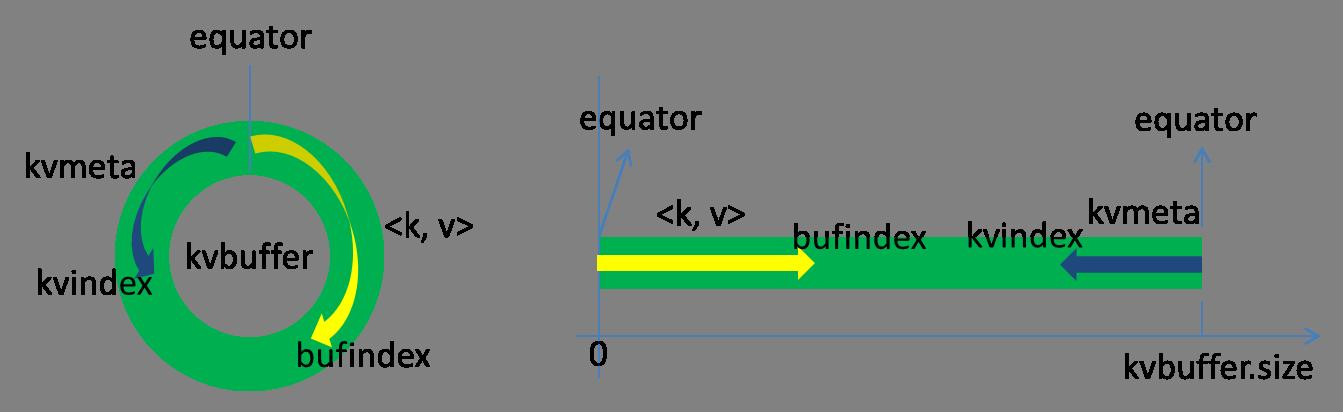
Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
索引是对在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如Kvindex初始位置是-4,当第一个写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二个和索引写完之后,Kvindex跳到-32位置。
Kvbuffer的大小虽然可以通过参数设置,但是总共就那么大,和索引不断地增加,加着加着,Kvbuffer总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill,多么明了的叫法,内存中的数据满了就自动地spill到具有更大空间的磁盘。
关于Spill触发的条件,也就是Kvbuffer用到什么程度开始Spill,还是要讲究一下的。如果把Kvbuffer用得死死得,一点缝都不剩的时候再开始Spill,那Map任务就需要等Spill完成腾出空间之后才能继续写数据;如果Kvbuffer只是满到一定程度,比如80%的时候就开始Spill,那在Spill的同时,Map任务还能继续写数据,如果Spill够快,Map可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后者。
Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill,原来不仅仅是Spill,在Spill之前还有个颇具争议性的Sort。
Sort
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill
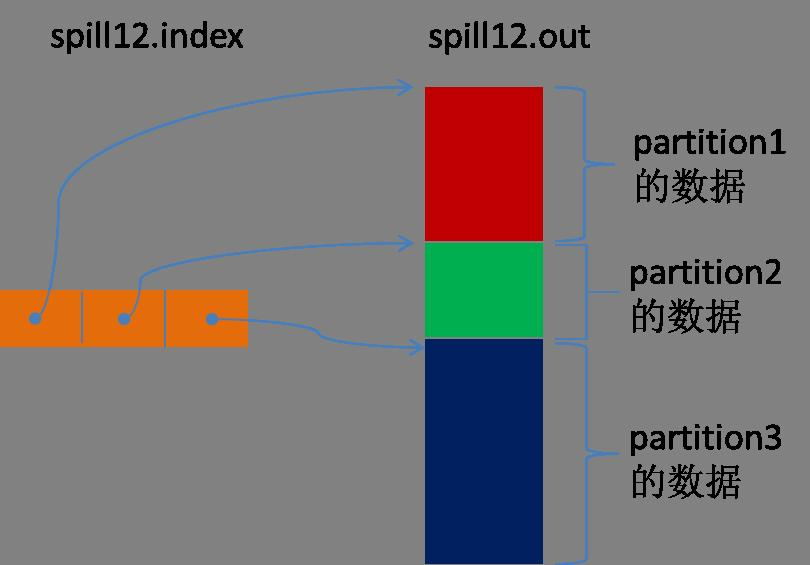
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。
所有的partition对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个partition在这个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个partition对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。然后把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index”的文件,文件中不光存储了索引数据,还存储了crc32的校验数据。(spill12.out.index不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中,即使在磁盘上创建了,和spill12.out文件也不一定在同一个目录下。)
每一次Spill过程就会最少生成一个out文件,有时还会生成index文件,Spill的次数也烙印在文件名中。索引文件和数据文件的对应关系如下图所示:
在Spill线程如火如荼的进行SortAndSpill工作的同时,Map任务不会因此而停歇,而是一无既往地进行着数据输出。Map还是把数据写到kvbuffer中,那问题就来了:只顾着闷头按照bufindex指针向上增长,kvmeta只顾着按照Kvindex向下增长,是保持指针起始位置不变继续跑呢,还是另谋它路?如果保持指针起始位置不变,很快bufindex和Kvindex就碰头了,碰头之后再重新开始或者移动内存都比较麻烦,不可取。Map取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex指针移动到这个分界点,Kvindex移动到这个分界点的-16位置,然后两者就可以和谐地按照自己既定的轨迹放置数据了,当Spill完成,空间腾出之后,不需要做任何改动继续前进。分界点的转换如下图所示:
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





