
近年来,大规模在线开放课程(MOOC)以全新的教育形式逐渐进入人们的视野。MOOC为学习者提供了超越时间、空间和地点限制的灵活途径和渠道,因此随着移动互联网技术的发展,有效促进了在线教育的发展。
目前,除了完成规定的专业课程,学生还可以根据自己的兴趣和未来的计划选择自己的课程。
然而,一些学生由于对课程了解不够,盲目跟随他人而无法有效利用课程资源。因此,如何从众多共享教育资源中选择适合的学习者进行在线课程已成为在线学习平台目前需要解决的主要问题之一。
推荐系统方法简介
推荐系统可以有效解决MOOC平台中复杂学习资源带来的“选择困难”问题,学习者可以方便地获取相关课程信息,从而提高平台的个性化服务水平,大大促进在线学习的发展。
对于在线教育来说,通过使用推荐系统为在线学习者提供个性化服务、建模学习者的偏好并提供推荐课程服务,可以推动在线学习的发展。尽管基于学习者偏好的个性化课程推荐算法不断被提出,但其中大多数尚未被充分挖掘。
传统推荐模型包含以下内容:
协同过滤(Collaborative Filtering):基于用户行为数据或项目之间的相似性,通过寻找用户间的共同兴趣或项目间的相似性来进行推荐。其中包括基于用户的协同过滤和基于项目的协同过滤。
基于内容的推荐(Content-Based Recommendation):根据用户对项目的喜好和项目的特征描述时空序列数据分析和建模,通过计算项目之间的相似度来进行推荐。这种方法依赖于对项目内容的分析和特征提取。
基于流行度的推荐(Popularity-Based Recommendation):根据项目的流行度或热门程度来进行推荐。这种方法认为流行的项目更有可能受到用户的喜欢时空序列数据分析和建模,因此推荐热门项目给用户。
混合推荐(Hybrid Recommendation):结合多种推荐方法来生成推荐结果。这种方法可以综合利用不同推荐模型的优势,提高推荐的准确性和多样性。
但在上述方案中,推荐系统的数据稀疏性问题尤为突出,需要进一步研究其他课程推荐方法,例如依赖学习者与课程之间的历史互动数据。
另一方面,传统的推荐模型在捕捉学习者的偏好和特征方面存在局限性,推荐性能的改进并不显著。
而由于其强大的非线性映射能力,深度学习可以有效地将高维数据映射到低维空间以提取高级特征。近年来,深度学习在个性化推荐中得到了广泛应用。
其中,自编码器具有强大的隐性特征学习能力,可以有效解决数据稀疏性的问题。此外,由于用户经常考虑他们之前学过的课程,用户的课程选择序列具有明显的时间特征,而LSTM具有强大的时间建模能力,可以处理时间序列数据。
基于上述特点,下面将介绍一种使用LSTM来改进应用于在线教育课程推荐领域的自编码器,并根据用户的学习历史推荐以下课程。
理论基础
深度学习技术的引入给推荐系统带来了革新,为提高推荐性能提供了新的机遇。它能够有效地捕捉学习者与课程之间的复杂交互关系,并挖掘学习者的个性化偏好。
然而,另一个挑战是从训练网络模型中获取的课程的潜在特征大多是通过随机初始化生成的课程序列,无法以细粒度构建学习者的隐性偏好模型,这使得很难区分不同历史课程对学习者偏好的推荐效果。
不同课程之间存在层次关系是一种常见现象,课程的相关性是影响推荐效果的因素之一。先决条件意味着人们在接触某个概念的深层知识之前必须学习它,这对满足学习者的课程体验非常重要,也是帮助学习者按照正确的学习顺序选择课程的前提条件。
课程的先决条件和后续关系不仅适用于线下课程,也适用于在线课程。然而,现有的先决条件关系主要是由教师或领域专家手动标记的,无法满足在线课程的不断增长的需求。
另一方面,在线用户可能来自具有不同背景的学习者,不同大学在MOOC上提供不同学科的课程,因此,对来自不同背景的学生进行个性化学习相对较困难,如何充分利用课程的属性信息并捕捉在线课程的先决条件关系是一个具有挑战性的问题。
正如图1所示,根据不同的推荐方法,它们可以分为显性反馈和隐性反馈。
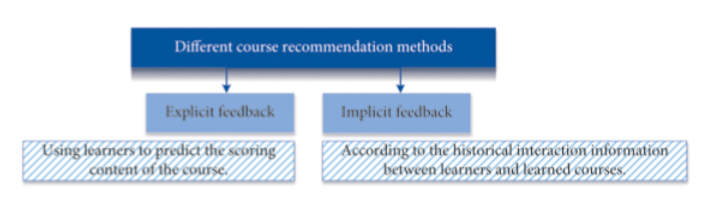
图1 不同推荐方法
前者利用学习者对已学习课程的评分内容来预测其他课程的评分。后者根据学习者与已学习课程之间的历史交互信息,如已学习课程的行为数据,生成相应的课程推荐列表。
与显性反馈中存在虚假或随机评分等问题相比,基于隐性反馈的推荐是常用的推荐算法之一,可以真正挖掘用户的偏好。然而,矩阵分解模型通过简单组合可以挖掘用户的特征,但无法捕捉复杂数据的更深层特征向量,这将极大地降低推荐的准确性和训练过程的收敛速度。
长短时记忆网络
长短时记忆网络(Long Short-Term Memory,简称LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,简称RNN),用于解决传统RNN在处理长序列数据时出现的梯度消失和梯度爆炸的问题。
LSTM网络引入了一种称为"门"(gates)的机制,通过控制信息的流动和遗忘来实现对长期依赖关系的建模。
LSTM网络包含三个关键的门控单元,分别是遗忘门、输入门和输出门。这些门控单元根据输入数据和之前的隐藏状态来决定信息的保留和遗忘,从而实现长期记忆和长序列建模的能力。图2展示了LSTM的内部结构。
在LSTM中,遗忘门决定要从前一个时间步长的隐藏状态中遗忘多少信息;输入门决定要从当前时间步长的输入和前一个时间步长的隐藏状态中选择多少信息添加到细胞状态(cell state)中;输出门决定从当前时间步长的输入和前一个时间步长的隐藏状态中选择多少信息输出。
通过这种门控机制,LSTM网络能够有效地捕捉长期依赖关系,并且在训练过程中能够保持梯度的稳定,从而更好地处理长序列数据的建模任务,如语言模型、机器翻译、音乐生成等。
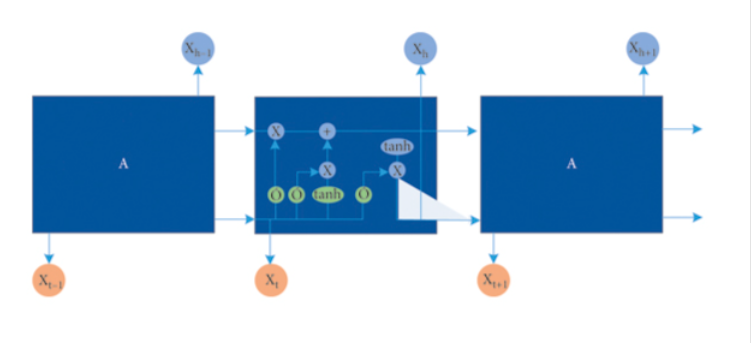
图2 LSTM内部结构
LSTM网络的结构相对复杂,但由于其出色的性能和对长序列数据的适应能力,它成为了自然语言处理、时间序列分析等领域中常用的神经网络模型之一。
自编码器
自编码器是一种通过无监督学习学习数据编码的人工神经网络。它的特点是学习目标与输入数据相同,其通常的目的是通过训练神经网络忽略无关信息来减少数据的维度。
常见的自编码器有以下几种:
基本自编码器(Basic Autoencoder):由一个简单的前馈神经网络构成,编码器和译码器的层结构对称。
稀疏自编码器(Sparse Autoencoder):在基本自编码器的基础上加入稀疏性约束,以促使编码器学习到更稀疏的表示。
压缩自编码器(Variational Autoencoder):采用概率建模的方法,将编码器学习到的表示看作是潜在变量的概率分布,并通过最大化对数似然来训练模型。
堆叠自编码器(Stacked Autoencoder):由多个自编码器堆叠而成,每个自编码器的输出作为下一个自编码器的输入,用于学习更复杂的特征表示。
卷积自编码器(Convolutional Autoencoder):适用于处理图像数据的自编码器,使用卷积神经网络来构建编码器和译码器。
自编码器由两部分组成:一个压缩和编码输入数据的编码器,以及一个将编码重构为输入数据的译码器。图3显示了它的基本结构。
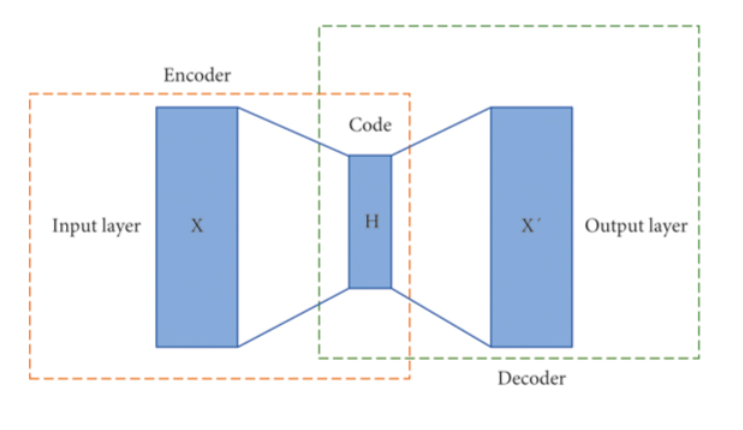
图3 自编码器结构
用户的评分数据被输入到模型中,经过编码器处理后得到隐藏层的变量,然后通过译码器对隐藏层的变量进行重构,得到模型的输出数据,在重构过程中,可以预测未知项目的评分。
基于自编码器的在线课程推荐模型
首先是数据集获取部分,虽然大学的在线数据集中包含了一些相关课程的简要内容,但是有些课程的简要内容过于繁杂,不利于后续的自然语言处理来提取课程之间的关系。
因此,首先需要通过网络爬虫工具获取部分文本信息。具体步骤如下,如图4所示。
(1) 打开大学的在线网站,学习者可以查看相应课程介绍内容的页面,通过浏览器工具将其转换为HTML编码页面,并分析页面不同位置的数据编排方式;
(2) 使用正则表达式获取相应课程的文本数据;
(3) 根据统一的格式将这些课程的描述存储在本地数据库中,然后对数据进行清洗处理。
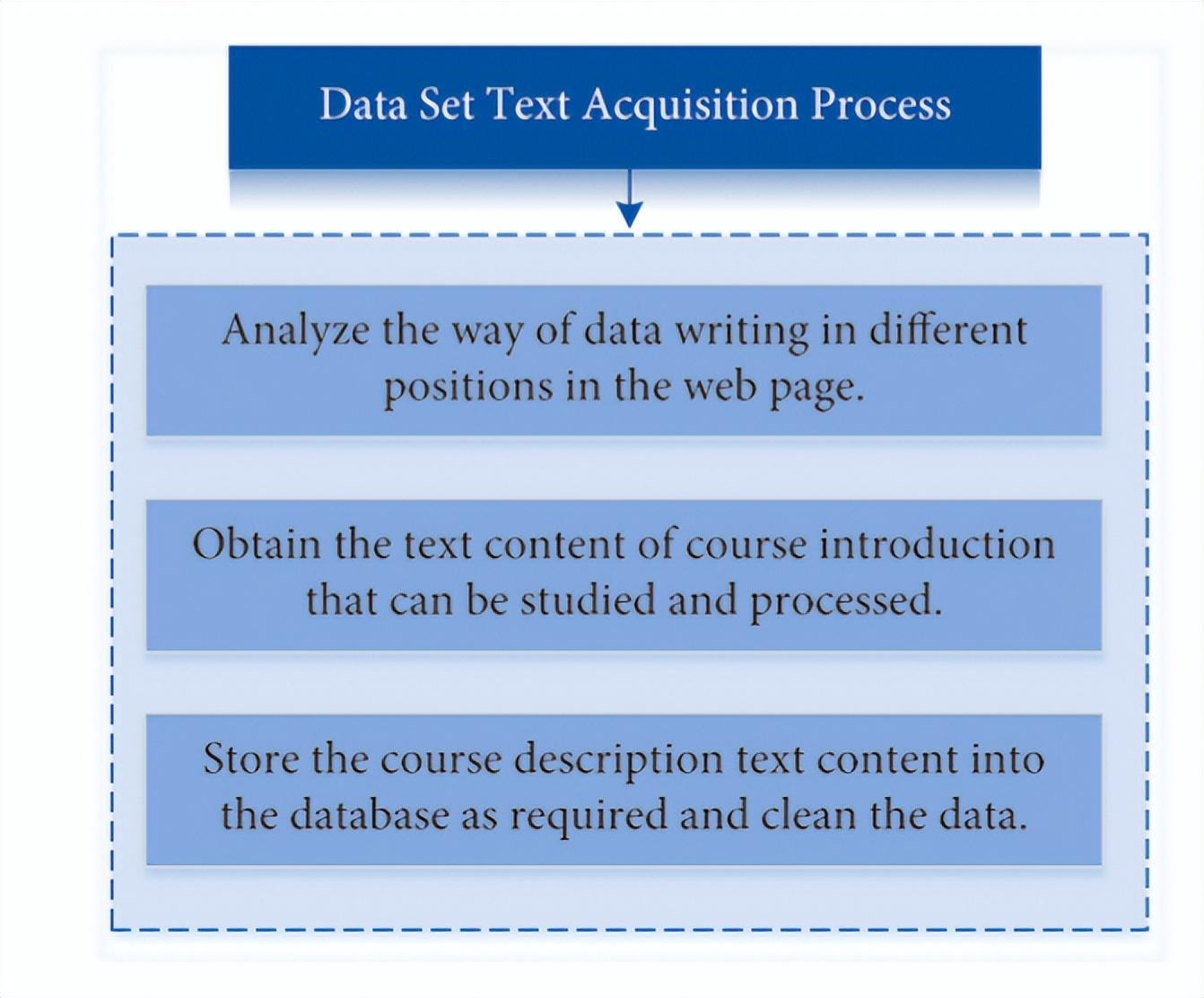
图4 数据集获取过程
研究人员们采用了一个MOOC的真实数据集,包含458,454条选课记录,包括82,535个用户和1,302门课程。每条记录包含用户ID、选课时间、课程ID、课程名称、课程类别等属性。
他们对噪声数据进行了以下操作:
(1) 将原始数据简化为三元组(用户ID、选课时间、课程ID)。
(2) 在82,535个用户中,排除选课数量少于10门的用户,留下130,812条数据和8,268个用户。
(3) 将用户分成8,268个组,并按照选课时间的升序在每个组内进行排序。
(4) 根据用户ID、课程ID的时间序列合并组内的数据,从而得到最终的数据集,共计8,268条数据。
时间序列特征提取模型
为了对用户的课程选课数据进行时间序列建模,研究人员采用了LSTM替代自编码器中的前馈神经网络,这类似于RNN Encoder Decoder和ENDEC-AD。所提出的时间序列特征提取方法如图5所示。
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。


")


