

研究人员一致认为,视觉是我们的主要意识:我们感知,学习或处理的信息中有80-85%是通过视觉进行调节的。 当我们试图理解和解释数据时,或者当我们寻找数百或数千个变量之间的关系以确定它们的相对重要性时,情况就更是如此。 识别重要关系的最有效方法之一是通过高级分析和易于理解的可视化。
数据可视化几乎应用于所有知识领域。 不同学科的科学家使用计算机技术对复杂事件建模并可视化无法直接观察到的现象,例如天气模式,医疗条件或数学关系。
数据可视化提供了一套重要的工具和技术,可用于定性理解。 基本技术如下图:
线图
线图是最简单的技术,用于绘制一个变量与另一个变量之间的关系或依存关系。 要绘制两个变量之间的关系,我们可以简单地调用plot函数。

条形图用于比较不同类别或组的数量。 类别的值通过条形图表示,可以用垂直或水平条形图配置,每个条形图的长度或高度代表该值。
饼图和甜甜圈图
关于饼图和甜甜圈图的价值存在很多争论。 通常,它们用于比较整体的各个部分,并且在组成部分有限以及包含文本和百分比来描述内容时最有效。 但是,它们可能难以解释,因为人眼很难估计区域并比较视角。
直方图
直方图表示连续变量在给定间隔或时间段内的分布,是机器学习中最常用的数据可视化技术之一。 它通过将数据分成多个块(称为" bin")来绘制数据。 它用于检查基础频率分布,离群值,偏斜度等。
散点图
另一种常见的可视化技术是散布图,散布图是表示两个数据项的联合变化的二维图。 每个标记(点,正方形和加号等符号)表示一个观察值。 标记位置指示每个观察值。 当您分配两个以上的度量时,将生成一个散布图矩阵,该矩阵是一系列散布图,显示分配给可视化的各对度量的所有可能配对。 散点图用于检查X和Y变量之间的关系或相关性。
可视化大数据
今天,组织每分钟都会生成和收集数据。 由于必须考虑到信息的速度,大小和多样性,因此生成的大量数据(称为大数据)给可视化带来了新的挑战。 此类数据的数量,种类和速度要求组织从技术上离开其舒适区,以获取有效决策所需的情报。 基于数据分析核心基础的新的更复杂的可视化技术不仅考虑了基数,还考虑了此类数据的结构和来源。
非参数数据的内核密度估计
如果我们不了解数据的总体和底层分布,则将此类数据称为非参数数据,并借助代表随机变量概率分布函数的内核密度函数将其可视化。 当数据的参数分布没有太大意义,并且您希望避免对数据进行假设时大数据可视化技术,可以使用它。
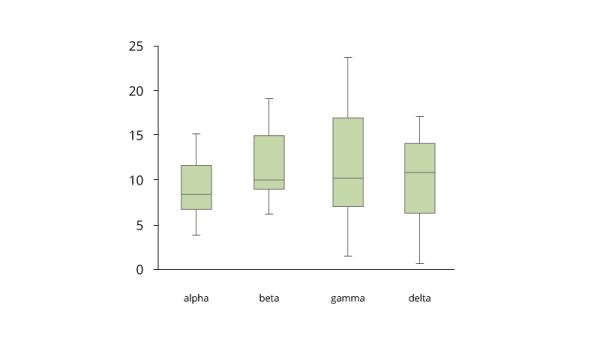
大数据的盒须图
带须状图的装箱图显示了大数据的分布,并且很容易看到异常值。 本质上,它是五个统计信息(最小值,下四分位数,中位数,上四分位数和最大值)的图形显示,总结了一组数据的分布。 较低的四分位数(第25个百分位数)由框的下边缘表示,较高的四分位数(第75个百分位数)由框的上边缘表示。 中位数(第50个百分位数)由中心线表示,该中心线将框分成多个部分。 极值由从盒子边缘伸出的晶须表示。 箱形图通常用于了解数据中的异常值。
非结构化数据的词云和网络图
大数据的多样性带来了挑战,因为半结构化和非结构化数据需要新的可视化技术。 词云视觉表示一个词在文本主体中的出现频率及其在云中的相对大小。 此技术用于非结构化数据,作为显示高频或低频单词的一种方式。

可以用于半结构化或非结构化数据的另一种可视化技术是网络图。 网络图将关系表示为节点(网络内的各个参与者)和关系(关系在个人之间)。 它们被用于许多应用程序中,例如,用于分析社交网络或绘制跨地理区域的产品
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





