

在实际研究中,我们经常需要获取大量数据,而这些数据很大一部分以pdf表格的形式呈现,如公司年报、发行上市公告等。面对如此多的数据表格,采用手工复制黏贴的方式显然并不可取。那么如何才能高效提取出pdf文件中的表格数据呢?
这是小编准备的python爬虫学习资料,关注,转发,私信小编“01”即可免费获取!

Python提供了许多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等。综合来看,pdfplumber库的性能较佳,能提取出完整、且相对规范的表格。因此,本推文也主要介绍pdfplumber库在pdf表格提取中的作用。
作为一个强大的pdf文件解析工具,pdfplumber库可迅速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页面、页码等信息,还可进行页面可视化操作。使用pdfplumber库前需先安装,即在cmd命令行中输入:
pip install pdfplumber
pdfplumber库提供了两种pdf表格提取函数,分别为.extract_tables( )及.extract_table( ),两种函数提取结果存在差异。为进行演示python数据可视化 pdf,我们网站上下载了一份短期融资券主体信用评级报告,为pdf格式。任意选取某一表格,其界面如下:
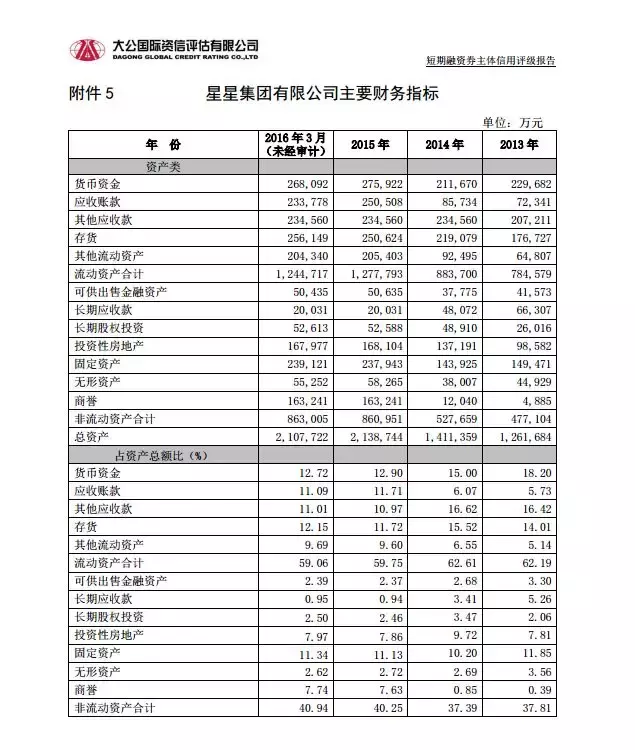
接下来,我们简要分析两种提取模式下的结果差异。
(1).extract_tables( )
可输出页面中所有表格,并返回一个嵌套列表,其结构层次为table→row→cell。此时,页面上的整个表格被放入一个大列表中,原表格中的各行组成该大列表中的各个子列表。若需输出单个外层列表元素,得到的便是由原表格同一行元素构成的列表。例如,我们执行如下程序:

输出结果:

(2).extract_table( )
返回多个独立列表,其结构层次为row→cell。若页面中存在多个行数相同的表格,则默认输出顶部表格;否则,仅输出行数最多的一个表格。此时,表格的每一行都作为一个单独的列表,列表中每个元素即为原表格的各个单元格内容。若需输出某个元素,得到的便是具体的数值或字符串。如下:

输出结果:
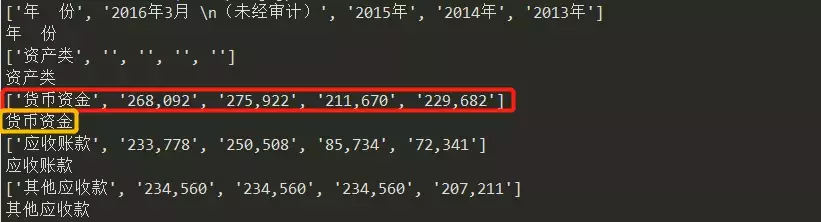
在此基础上,我们详细介绍如何从pdf文件中提取表格数据。其中一种思路便是将提取出的列表视为一个字符串,结合Python的正则表达式re模块进行字符串处理后,将其保存为以标准英文逗号分隔、可被Excel识别的csv格式文件python数据可视化 pdf,即进行如下操作:

输出结果:
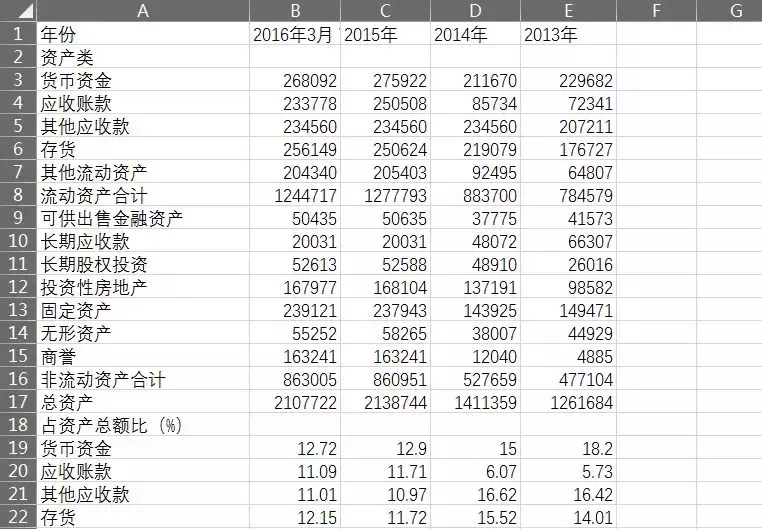
尽管能获得完整的表格数据,但这种方法相对不易理解,且在处理结构不规则的表格时容易出错。由于通过pdfplumber库提取出的表格数据为整齐的列表结构,且含有数字、字符串等数据类型。因此,我们可调用pandas库下的DataFrame( )函数
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





