
作者
现任职网易邮件事业部资深数据开发工程师,作为主要开发人员参与网易邮箱大数据平台的建立、优化、重构等工作,并取得相当的成效。他长期从事服务端应用及大数据领域的架构研发工作,对相关领域的底层架构、开发流程及技术细节等都有一定积累。
(本文为作者在 StarRocks Summit Asia 2022 上的分享)
从零到一,臻于至善,反映了网易人对于数据追求的不断进步,也反映了 StarRocks 在技术方面尽善尽美的追求。本次分享给大家介绍网易邮箱基于 StarRocks 开发大数据平台的实践心得。
#01 网易邮箱业务背景
1.1 网易邮箱发展史
网易邮箱作为国内互联网行业一个活化石级别的业务,从诞生到现在已经进入第二十五个年头:
网易邮箱见证了国内互联网行业从诞生到发展以及壮大的整个过程,相应的数据处理架构也发生了一系列变化:
1.2 邮箱数据应用场景
业务日志数据存储:所有业务日志都要求永久冷备存储,同时在一些关键的业务上面,要求至少有半年以上的热点数据的热备存储。不同的数据分别存储,离线数据存储到 HDFS ,实时数据存储到 ClickHouse。
业务可用性保障:网易邮箱作为一个通信性质的业务,它的核心收发信链路以及用户登录验证机制对可用性要求非常高。
核心指标统计:包括用户的活跃度,用户新增/流失/挽回等转化率,APP的安装率, Webmail 的登录等数据,会生成数据报表进行数据展现。
运营策略指引:包括直邮、推送等的转化率的分析,以及引流用户的留存率等方面的一些数据统计。
反垃圾与风控:邮箱需要具备反垃圾的能力以及风控的能力,会对用户的敏感行为做出判断,通过数据的反馈来进行捕捉,同时制定反垃圾策略。
业务产品优化:邮箱的数据产品会支持一些业务的优化,包括对一些新业务的用户使用数据的采集分析,以及诸如用户支付和订阅情况的分析等。
1.3 数据规模与业务现状
服务器方面。包括一些实体机和云上的一些虚机,总的算力超过1万核,服务器分布在华北和华东等各个 IDC 机房。数据比较分散,汇总处理的难度较高。
用户量方面。网易邮箱存量的注册用户达到10亿级别,同时每天还在新增巨大的新注册用户量。存量和增量巨大,风控的压力较大。
数据量方面。冷备的历史压缩数据已经达到PB级别,同时每天新增的数据量也很大,内外网的数据流量峰值达到每秒上G的级别。资源吃紧,维护成本高。
业务线方面。核心的收发信数据链路和登录服务的可用性要求都是 SLA 达到 99.99%,同时每天都有超过1000个的离线数据处理任务,实时数据处理要求7×24小时无间断运行,下游支撑超过1万个数据服务。业务模型复杂,服务精度、可用性要求高。
#02 OLAP 引擎演进与选型
2.1 OLAP 平台演进
网易邮箱作为国内互联网行业里面最早接触大数据领域的互联网厂商之一,从05年就开始接触 Hadoop 架构作为大数据处理平台。当时主要功能是数据的存储和采集,使用 MapReduce 进行数据处理,使用 Hive 和 HBase 进行离线和实时数据查询任务,数据输出使用 Oracle 的 BI 系统实现。
随着技术的不断发展,到18年逐渐过渡到基于 Flink + Kafka + ClickHouse 以及网易杭研自研的猛犸平台组建的一个批流合一的数据平台。ClickHouse 作为 ODS 基础数仓,主要用来支持实时性的查询任务,猛犸平台主要负责任务的编排和调度3g网络 典型数据业务介绍,自研的数据报表系统进行数据的呈现。
随着业务深入的发展,现有的架构在一些特殊的场合或需求下,有些力不从心。包括一些跨表的或者复杂度较高的查询,以及一些高并发的场景,还有一些大数据的热点更新的场景,现有的架构都没有办法做到满意。
网易邮箱从21年开始引入了 StarRocks,作为下一代数据引擎架构,解决高并发查询输出,复杂事务跨表查询,数据热更新支持等问题。
2.2 为什么引入 StarRocks
网易邮箱为什么会引入 StarRocks,这要从业务痛点说起。
首先,从资源方面来说,网易邮箱因为用户量和数据量都非常大,资源显得有些不足,造成 Kafka 和 ClickHouse,以及运算机器本身等,经常会出现一些因为压力过大而产生的报警,影响数据业务的开展和数据处理任务的开发。
其次,因为现有架构里面会同时存在多个数据平台,每个平台都要相应的运维人员介入,造成运维成本和采购费用居高不下。
再次,在数据需求方面,当前的架构与一些业务需求不匹配,主要体现在包括离线实时,和一些高并发以及跨表的查询,都没有一劳永逸的方案。
同时,作为移动互联网的一个永恒不变的矛盾,产品对于数据需求的紧迫性,当前的架构没有办法很好的快速支持。
另外,在数据开发方面,由于邮箱的一些历史原因,一些比较老旧的基础服务的日志,开发的时候并没有考虑到数据统计方面的需求,这些日志的格式参差不齐,对数据清洗以及下游的数据存储的技术迭代有一定影响。
最后,系统的一些链路经过多年的迭代之后有些臃肿,而数据需求经常变化多端,导致开发人员的人力资源不是很够,造成开发难度的增大。
因为上述问题,我们迫切需要一个性能强悍、上手容易、部署简单、使用方便、适配性高、安全稳定的 OLAP 系统,而 StarRocks 刚好能满足我们的需求,这是我们为什么要引入 StarRocks 的根本原因。
2.3 OLAP 指标维度对比
我们对比了国内外一些比较常见的 OLAP 系统,包括 StarRocks、ClickHouse、Impala 以及最基础的 Kylin。下图是我们的对比结果。
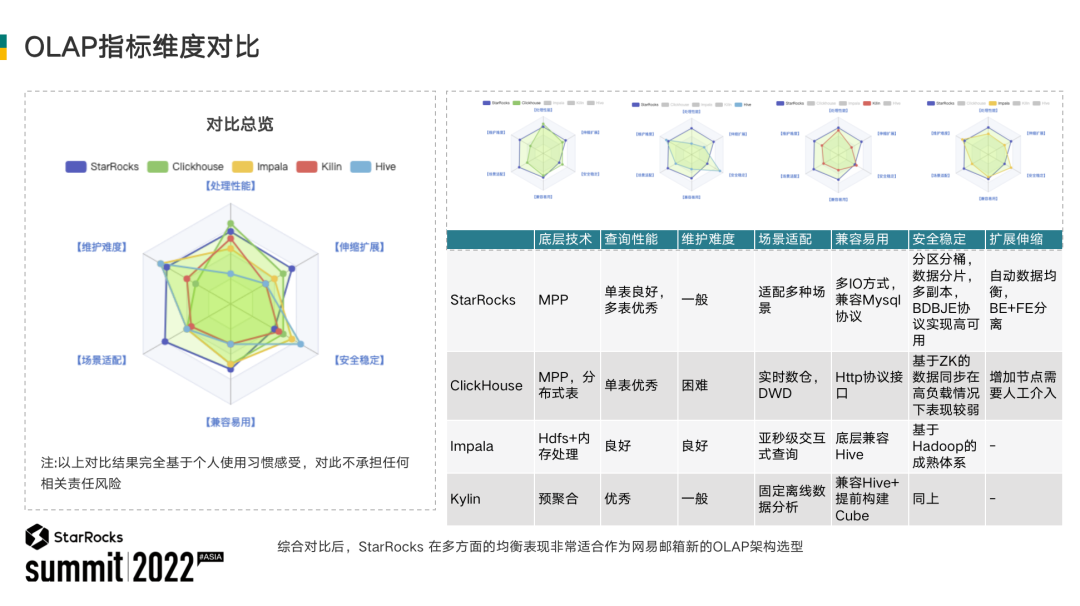
我们对比的维度包括底层技术、查询性能、维护难度、场景适配、兼容易用、安全稳定和扩展伸缩7个维度。
ClickHouse 作为当前比较流行的 OLAP 系统,我们重点分析一下它跟 StarRocks 的一些区别。
底层技术方面, StarRocks 与 ClickHouse 都是基于 MPP 架构实现。
查询性能方面,StarRocks 的性能在单表查询上表现良好,多表联合查询方面比 ClickHouse 更有优势。
维护难度方面,StarRocks 没有三方依赖,可以开箱即用,而 ClickHouse 的维护难度在业界是出了名的高。
场景适配方面3g网络 典型数据业务介绍,我们当前的实际应用是实时数仓,存储海量的流水数据。StarRocks 提供了若干种数据模型,可以覆盖大部分的业务场景。
兼容易用方面,两者的表现差不多。ClickHouse 支持 HTTP 接口,StarRocks 的优势则体现在提供多种 IO 的支持,以及对于 MySQL 协议的兼容。
安全稳定方面,分区分桶和多副本架构两者都支持,最大区别是 ClickHouse 的分布式高可用是基于ZooKeeper 实现的。我们在实际应用中发现,在高负载的情况下,ZooKeeper 的表现是比较差的,经常出现一些诸如复制失败、数据丢失的情况。StarRocks 则是基于自研的 BDBJE 来实现,在我们的实际应用过程中并没有发现它出现类似 ClickHouse 那样的数据异常的问题。
扩展伸缩方面, StarRocks 的优势主要体现在它可以对每一个分区来灵活的定制它的数据扩容的方案,同时它在扩容之后,可以自动实现数据均衡,相对来说 ClickHouse 则需要人工介入来处理。
经过以上7大方面的对比,StarRocks 在各方面的均衡表现,都非常适合作为网易邮箱的下一代 OLAP 系统的选型。
#03 系统架构
3.1 系统架构描述
下图左边就是网易邮箱大数据处理系统的系统结构图,从左到右,从下到上可以分为5个层次。
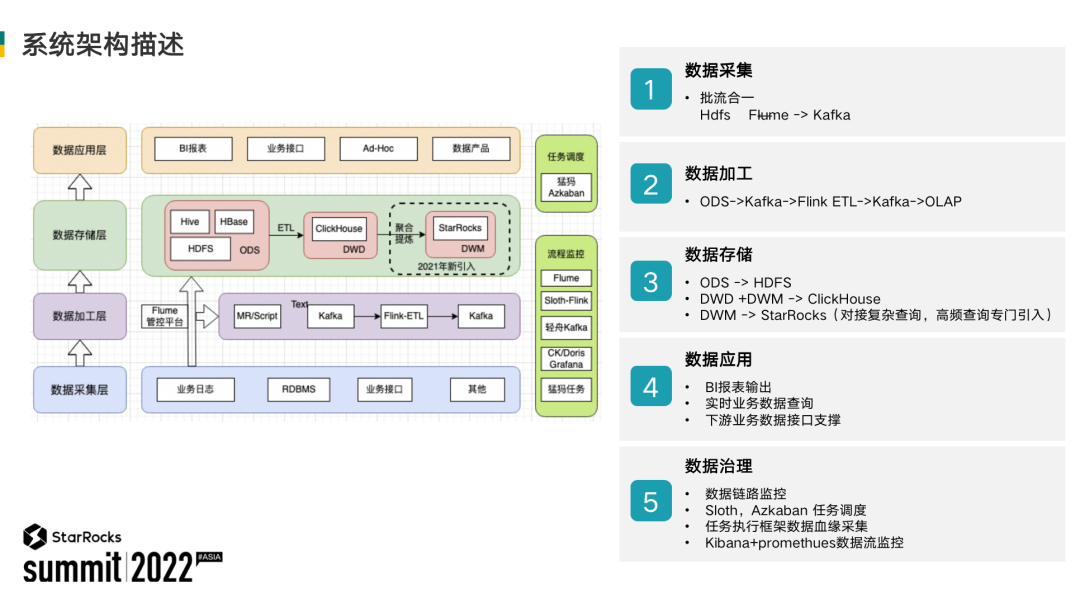
左下角是数据采集层,它主要的任务就是将分布在各个服务器上的日志数据,通过 Flume 采集汇总到数据处理层,按照不同的类型诸如离线的或者是实时的分别存储到对应的存储介质上。
再上一层是数据加工层,对应不同的数据类型,离线数据使用MapReduce 任务处理,实时数据使用 Flink 任务处理,然后把数据存储到数据存储层。
再往上是数据存储层,最原始的没有经过任何加工的 ODS 数据会存储到 HDFS 上,经过一定的清洗形成的结构化数据会放到 ClickHouse 的实时数仓里面。从21年开始,数据存储层引入了 StarRocks 把 ClickHouse 实时数仓上的基础数据进行聚合提炼,以应对更深层更复杂的查询,和一些实时性的查询。
在数据存储层上面就是数据应用层了,应用层主要包括了数据大盘报表的输出,以及给下游业务提供的实时查询的业务接口。
右面绿色部分是数据治理框架,包括数据链路的监控,实时和离线任务的配套 Sloth,以及 Azkaban 的模型,还有我们出于对数据血缘方面的考虑,自己研发的一套任务执行框架,以及对应的 Kibana 和 Promethues 的数据监控系统。
这5大部分共同组成了一个完整的大数据处理架构。
3.2 StarRocks 使用场景
StarRocks 在网易邮箱的实际业务中的使用场景,可以分为4个类型:
以上4种场景都是基于 StarRocks 提供的,包括跨表查询的能力、聚合模型实现的数据热更新以及高并发的数据查询响应能力等。这使得 StarRocks 能够适应网易邮箱大部分的使用场景,能够做到以往要靠多个系统才能完成的工作。
3.3 StarRocks 表现
下图中的3是我们生产环境中的一个 StarRocks 集群,包括三台物理机。
图中的1是一个跨表查询的结果,在若干个数据规模超过亿级的大表上进行一个联合查询,大概两分钟左右能够产生结果,这是比较强悍的一个跨表查询,解决掉了我们以往的比较头痛的问题。

对于这些复杂的查询,以往只能在数据规划阶段,把所有维度都合成一个大宽表来实现,一来导致维护的难度较高,二来会造成数据冗余,实现不够优雅。有了 StarRocks 之后,可以充分利用它的跨表查询的能力,把不同的数据,按照各自的特性切分到最合适的维度,在查询时根据各自的特性,组合成一个结果输出。
图中的2是在一个高并发场景下的压测结果,在100个并发以内,StarRocks 的响应时间都可以控制在50毫秒以内,这样的高并发的响应效率,已经足以媲美 HBase 或关系型数据库的能力了。因此StarRocks 其实已经能够取代关系型数据库的部分应用场景,从而不需要部署多种不同的业务架构,实现我们减少投入的目标。
图中的4是数据的 IO 的压测结果,基于文件的 Stream Load 来进行压测,导入1.1亿条数据,耗时5分钟左右。比较强大的交互式数据导入能力,保证了 StarRocks 作为基础数仓对接不同数据源的扩展能力。
对比 ClickHouse 和 Hadoop 这些比较传统的大数据架构,StarRocks 的系统维护门槛相对较低,主要体现在它是一个没有第三方依赖的系统,能够开箱即用。
StarRocks 的 FE/BE 的分离设计,分区分桶的数据存储方案,还有多副本机制,能够最大程度的保证数据的可用性。
StarRocks 分区分桶的设计,保证了能够支持在线扩容、自动数据均衡、自动冷备等特性,很大程度上降低了维护人员的工作强度。
StarRocks 还配备了覆盖面比较广的Grafana模板,提供集群性能指标的全方位可视化监控,使我们能够随时随地监控集群的运行情况。
StarRocks 提供了多种数据模式来支持不同的业务场景,像明细、聚合以及主键更新等,可以选择最贴切的数据模型来应对业务场景的开发。
StarRocks 支持文件、流以及外部表等多种数据交互方式,还提供了 Flink Connector 来提供流数据的支持,可以直接对接 Flink 任务实现数据流的导入。
StarRocks 的存储可以灵活的配置,像分区分桶的策略、TTL 的自动实现以及对外部表和物化视图的支持等,这些设计都能更好的提升查询性能。
StarRocks 支持标准的 SQL95 语法,同时提供了丰富的函数以及 UDF 自定义函数的功能。另外 Bitmap 可以实现数据的过滤去重以及索引的管理等。
StarRocks 在交互接口方面,它提供了 FE 多节点自动轮巡的 HTTP 接口,能够实现负载均衡。同时它对于 MySQL 协议的全兼容,很大程度上方便了业务开发,可以直接使用 MySQL Client 或者 JDBC 的驱动来开发对接。
StarRocks 有充分的技术团队支持,这也是它最重要的优势。镜舟公司提供了强大的业务团队,帮助解决我们在开发过程中遇到的问题,对于一些数据处理的工作,也提供了强大的业务支持。
#04 应用案例
4.1 用户登录处理链路
左边是数据链路的一个示意图,用户登录的行为数据,经过 Kafka 以及 Flink 的实时处理之后,存储到 StarRocks 数仓,然后同时支持下游4个不同的数据需求。
数据的落盘存储。基于存储之后的数据,在 T+1 的时间窗口进行数据的统计,最终生成 OKR 指标,输出到下游的数据报表系统。实时的用户登录,我们要求进行一些监控,
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





