
InfoSphere CDC 复制原理
InfoSphere CDC 能够对包括数据仓库,主数据管理,BI,SOA 等在内的应用整合及升级项目提供高速、可靠、低延迟的数据复制方案,而且对生产系统低影响。由于只复制变化的数据,减少了处理的开销和占用的带宽。复制可以是持续的也可以是周期性的。
图 1 CDC 架构图:
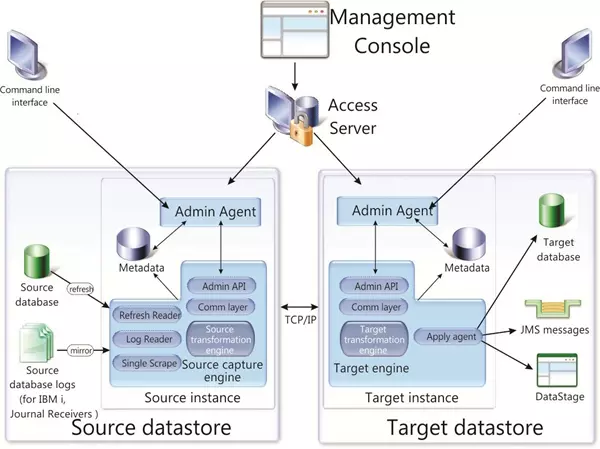
CDC 的关键组件主要的组成部分包括:
Access Server(AS):用户配置和监控 CDC 引擎的安全管理工具,支持图形化界面(V6.5 之后集成在 MC 中)及命令行。当用户登录 Management Console,就会连接到 AS。在客户端关闭 AS,不会影响源服务器到目标服务器到数据复制。
Management Console(MC):CDC 的图形化界面工具,允许用户配置、监控和管理在多个不同服务器上到数据复制,可以在客户端上指定复制的参数,初始化刷新和镜像。MC 也允许用户监控复制操作、延迟、事件消息和其他源和目标 datastore 支持的统计数据。
源端引擎:读取源端数据库的日志文件捕获变更数据,经过行列过滤,字符编码转换后由 TCP/IP 发送给目标端。
目标端引擎:接收源端发送的变更数据,经过数值转换,字符编码转换晨星资讯 股票数据分析员 薪酬,冲突检测后将变更数据应用到目标数据库。
Metadata:存储 CDC 实例的配置信息,包括数据库连接信息,预定信息以及表的映射信息等,同时记录当前的复制进行状态
源和目标 Datastore(数据存储):存储的是数据文件和数据复制需要的 InfoSphere CDC 实例信息。每个 datastore 代表了一个用户要连接的数据库,存储要复制的表。
多数的 CDC 引擎既可作为源端引擎捕获变化数据又可作为目标端引擎接收变化数据并将其应用于指定的数据库;通常,CDC 引擎称为 CDC 实例,如果从 AS/MC 的角度,一个 CDC 引擎也被称作一个 CDC 数据存储。
图 2 CDC 处理数据的流向图

1、当 CDC 处于复制状态的时候晨星资讯 股票数据分析员 薪酬,CDC 源端引擎中的 log reader 组件将会不停的从源端数据库日志中捕获所有要复制表的新变化的日志。
2、而 CDC 源端引擎中的 log parser 组件则将这些变化日志中跟 CDC 需要复制的表相关的日志找出来并根据其所属的 transaction ID 放在不同的 transaction queue 中。Transaction queue 是 log parser 在内存在分配的一片区域,专门存放没有提交的跟 CDC 复制表相关的事务信息。每个 Transaction queue 会写在以“txnq”做前缀的文件里,此文件在“/tmp”下可以找到。如果 txnq 开头的文件大小大于 0 字节,说明在处理非常大的还没有提交的事务。当订阅停止后,transaction queue 里的内容会存放在 pointbase 容器里。
3、当 CDC 读到 commit 触发一个事务结束时,该 transaction queue 将其内容提交给 Staging Store 后会释放相应的内存空间。Staging Store 是 CDC 分配的存放已提交的事务信息的内存区域,目标端引擎会自动从 Staging Store 中
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。




