
目前,编程人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语言和API越来越复杂,我们构建的应用也越来越复杂。根据外媒的一项调查报告,以下列出了Java程序员在过去12个月内一直使用的一些工具或框架,或许会对你有意义。
1、MongoDB--最受欢迎的,跨平台的,面向文档的数据库。
MongoDB是一个基于分布式文件存储的数据库,使用C++语言编写。旨在为Web应用提供可扩展的高性能数据存储解决方案。应用性能高低依赖于数据库性能,MongoDB则是非关系数据库中功能最丰富,最像关系数据库的,随着MongDB 3.4版本发布,其应用场景适用能力得到了进一步拓展。
MongoDB的核心优势就是灵活的文档模型、高可用复制集、可扩展分片集群。
2、Elasticsearch --为云构建的分布式RESTful搜索引擎。
ElasticSearch是基于Lucene的搜索服务器。它提供了分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是比较流行的企业级搜索引擎。
3、Cassandra--开源分布式数据库管理系统,最初是由Facebook开发的,旨在处理许多商品服务器上的大量数据,提供高可用性,没有单点故障。
Apache Cassandra是一套开源分布式NoSQL数据库系统。集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身。于2008开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
4、Redis --开源(BSD许可)内存数据结构存储,用作数据库,缓存和消息代理。
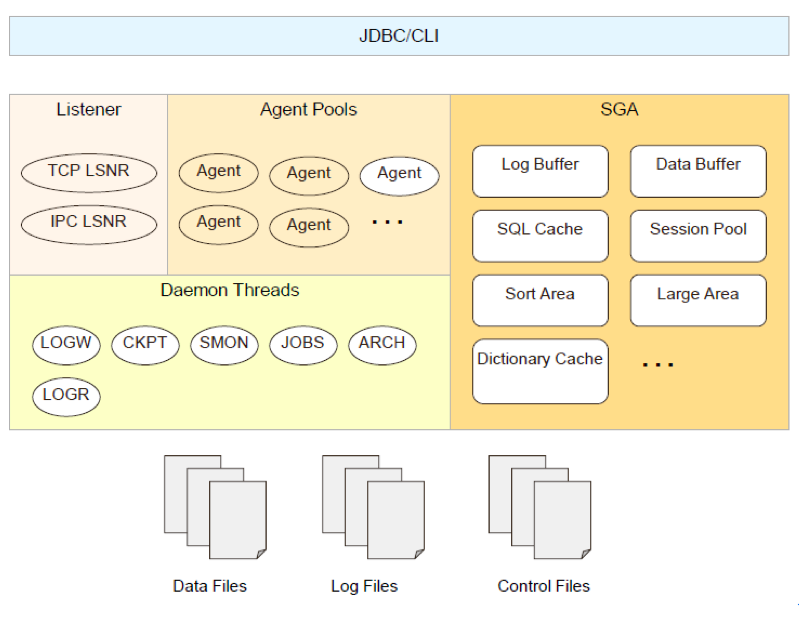
Redis是一个开源的使用ANSI C语言编写的、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
5、Hazelcast --基于Java的开源内存数据网格。
Hazelcast 是一种内存数据网格 in-memory data grid,提供Java程序员关键任务交易和万亿级内存应用。虽然Hazelcast没有所谓的‘Master’,但是仍然有一个Leader节点(the oldest member),这个概念与ZooKeeper中的Leader类似,但是实现原理却完全不同。同时,Hazelcast中的数据是分布式的,每一个member持有部分数据和相应的backup数据,这点也与ZooKeeper不同。
6、EHCache--广泛使用的开源Java分布式缓存。主要面向通用缓存、Java EE和轻量级容器。
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点开源数据仓库解决方案,是Hibernate中默认的CacheProvider。主要特性有:快速简单,具有多种缓存策略;缓存数据有两级,内存和磁盘,因此无需担心容量问题;缓存数据会在虚拟机重启的过程中写入磁盘;可以通过RMI、可插入API等方式进行分布式缓存;具有缓存和缓存管理器的侦听接口;支持多缓存管理器实例,以及一个实例的多个缓存区域;提供Hibernate的缓存实现。
7、Hadoop --用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
8、Solr --开源企业搜索平台,用Java编写,来自Apache Lucene项目。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
9、Spark --Apache Software Foundation中最活跃的项目,是一个开源集群计算框架。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。

10、Memcached --通用分布式内存缓存系统。
Memcached是一套分布式快取系统,当初是Danga Interactive为了LiveJournal所发展的,但被许多软件(如MediaWiki)所使用。Memcached作为高速运行的分布式缓存服务器,具有以下的特点:协议简单,基于libevent的事件处理,内置内存存储方式。
11、Apache Hive --在Hadoop之上提供类似SQL的层。
Hive是一个基于Hadoop的数据仓库平台。通过hive,可以方便地进行ETL工作。hive定义了一个类似于SQL的查询语言,能够将用户编写的SQL转化为相应的Mapreduce程序基于Hadoop执行。目前,已经发布了Apache Hive 2.1.1 版本。
12、Apache Kafka --最初是由LinkedIn开发的高吞吐量,分布式订阅消息系统。
Apache Kafka是一个开源消息系统项目,由Scala写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。Kafka维护按类区分的消息,称为主题(topic)。生产者(producer)向kafka的主题发布消息,消费者(consumer)向主题注册,并且接收发布到这些主题的消息。
13、Akka --用于在JVM上构建高并发,分布式和弹性消息驱动应用程序的工具包。
Akka 是一个用 Scala 编写的库,用于简化编写容错的、高可伸缩性的 Java 和 Scala 的 Actor 模型应用。它已经成功运用在电信行业,系统几乎不会宕机。
14、HBase --开放源代码,非关系型,分布式数据库,采用Google的BigTable建模,用Java编写,并在HDFS上运行。
与FUJITSU Cliq等商用大数据产品不同开源数据仓库解决方案,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
15、Neo4j --在Java中实现的开源图形数据库。
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全事务特性的Java持久化引擎。
16、CouchBase --开源分布式的NoSQL面向文档数据库,针对交互式应用程序进行了优化。
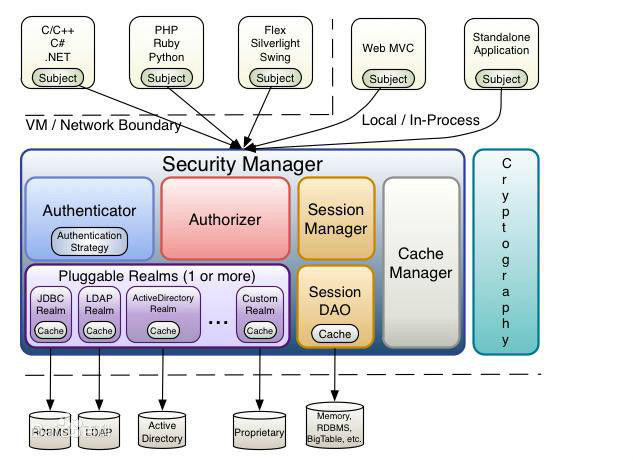
如果以前没有NoSQL的使用经验,那么理解couchbase的时候关键有两点:延后写入和松散存储。该产品基于Apache CouchDB,并整合了GeoC
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





