
数据分析
取出退货的订单 使用透视图进行观察
df1 = df.loc[df['Quantity'] 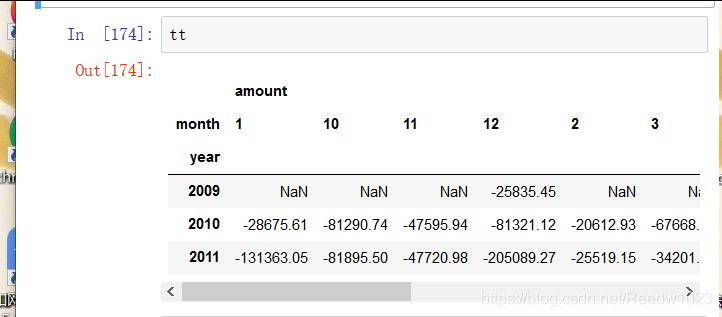
取出除退货订单以外的已完成订单并观察
df2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd.pivot_table(df2,index=['year'],columns=['month'],values=['amount'],aggfunc={'amount':np.sum},margins=False)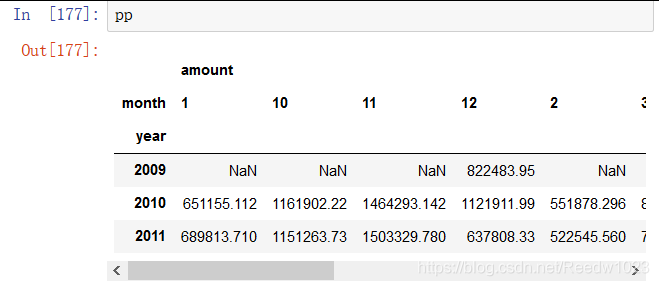
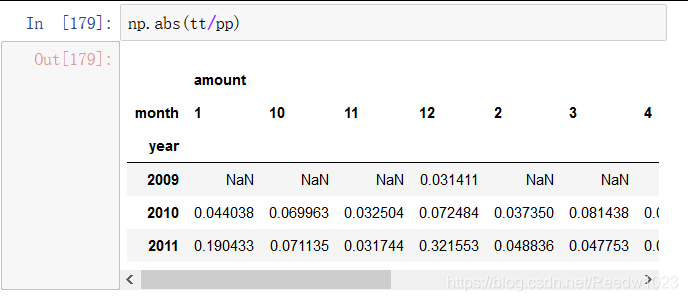
退货率=退货金额/合计金额
以2010年为例来画出退货率的折线图
#取出多列
df2010 = df[['year','month','Quantity','Price','amount']]
#取出2010年的记录
df2010 = df2010.loc[df2010['year'] == '2010']
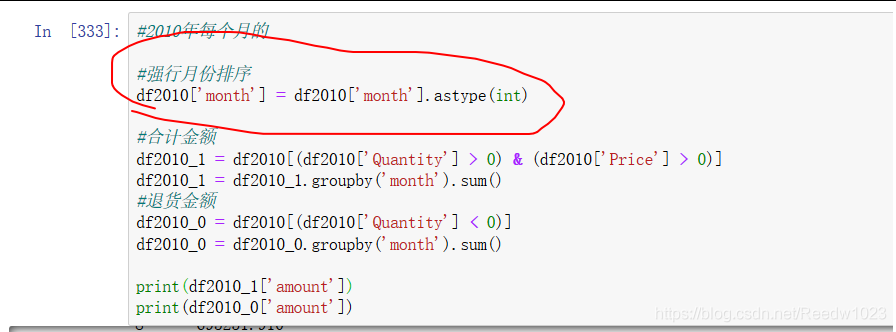
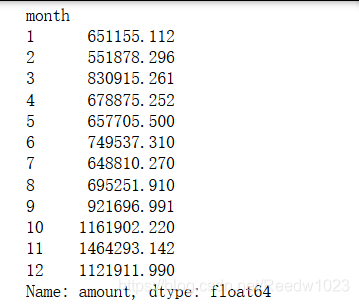
#2010年每个月的
#合计金额
df2010_1 = df2010[(df2010['Quantity'] > 0) & (df2010['Price'] > 0)]
df2010_1 = df2010_1.groupby('month').sum()
#退货金额
df2010_0 = df2010[(df2010['Quantity'] 出来的结果是这样的:
顺序是错的
搜了一下怎么解决,看到一个思路是修改行名变成01 02 03
但是用th2010.index[]和th2011.rename({})都失败了,想搜一下怎么把行换顺序也没搜到合适的
可能新建一个来放它/改一下month的数据类型/split的时候顺便加上'0'才能解决吧
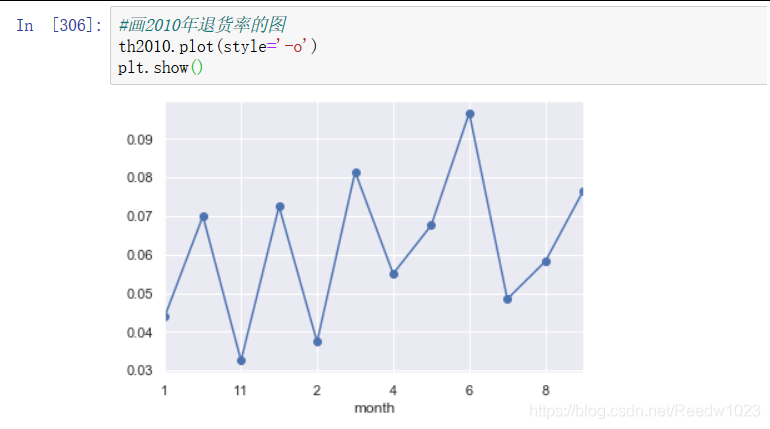
后来试了一下在前面取列时强行加上一句把month转成int 后来的数据排序果然正常了
画图时再加一句plt.xticks(range(0,12),th2010.index)把横坐标填充满
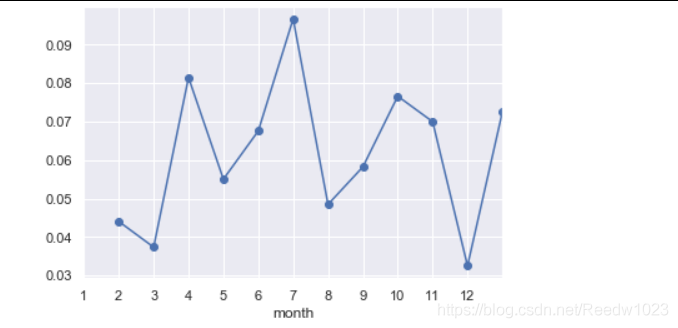
从数据中发现问题
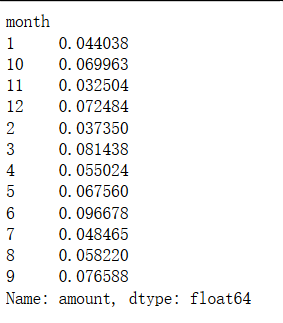
1、可以求出一年的退货平均值网购退货率数据分析网购退货率数据分析,对超过平均值的月份重点分析
np.abs(tt/pp).loc['2011'].mean()
2、可以对各年的退货平均值进行对比
RFM分层模型
R:Rencency 最近一次消费
影响因素:店铺记忆强度、接触机会多少、回购周期
应用场景:决定接触策略、决定接触频次、决定刺激力度
F:Frequency 消费频率
影响因素:品牌忠诚度、店铺熟悉度、客户会员等级、购买习惯养成
应用场景:决定资源投入、决定营销优先级、决定活动方案
M:Money 消费金额
影响因素:消费能力、产品认可度
应用场景:决定推荐商品、决定折扣门槛、决定活动方案
#最近一次交易时间 作为参考时间
df2['date'].max()
#最近购买日期间隔
R_value = df2.groupby('Customer ID')['date'].max() #每位客户的最近一次交易日期
R_value = (df2['date'].max() - R_value).dt.days #获得日期天数差距
R_value
#消费频次
F_value = df2.groupby('Customer ID')['Invoice'].nunique()#去重
F_value
#消费总金额
M_value = df2.groupby('Customer ID')['amount'].sum()
M_value用R_value.describe()来观察异常值
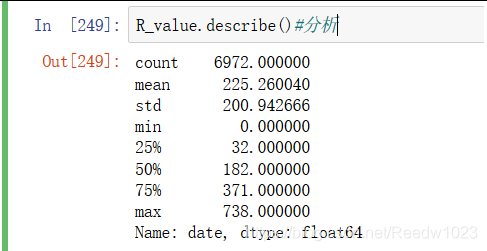
最久远的交易间隔已经两年了……
中位数和平均值相比不算差距很大
画个直方图看看分布情况
import seaborn as sns
sns.set(style = 'darkgrid')
plt.hist(R_value,bins=30)
plt.show()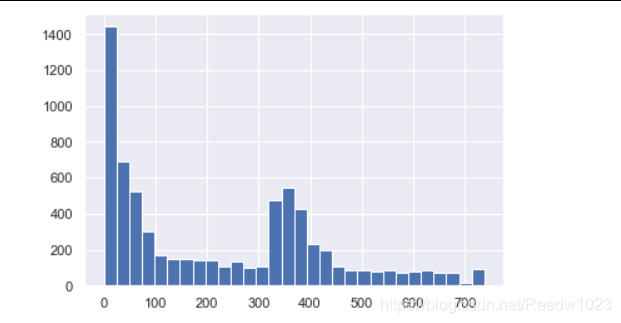
M_value.describe()
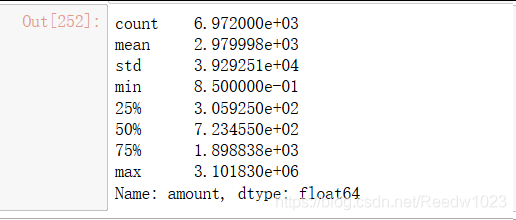
均值和中位数差距过大 方差也很大 异常值严重
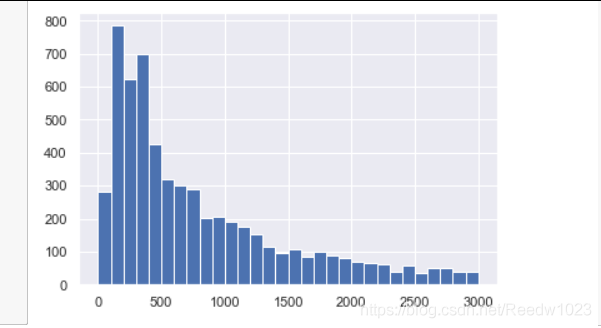
plt.hist(M_value[M_value因为看全范围的图的话分布很稀疏 所以就只看看小于平均值的
F_value.describe()
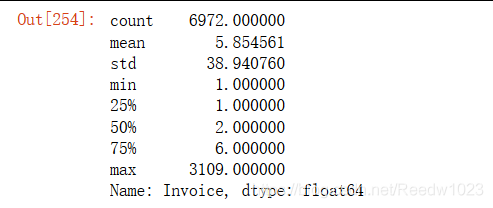
最大值过大 异常值严重
plt.hist(F_value[F_value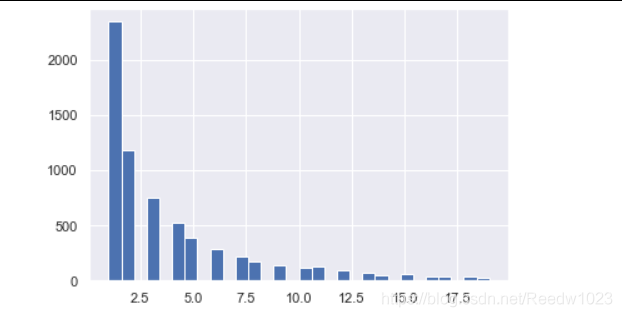
客户分级
R_bins = [0,30,90,180,360,720]#自定义间隔
F_bins = [1,2,5,10,30,100]#消费频次 可以用quantile查看分位数
M_bins = [0,500,2000,5000,10000,20000]#值越小越好 代表消费天数近
R_score = pd.cut(R_value,R_bins,labels=[5,4,3,2,1],right=False)
R_score#值越大越好 频次
F_score = pd.cut(F_value,F_bins,labels=[1,2,3,4,5],right=False)
F_scoredf2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd.pivot_table(df2,index=['year'],columns=['month'],values=['amount'],aggfunc={'amount':np.sum},margins=False)0df2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd.pivot_table(df2,index=['year'],columns=['month'],values=['amount'],aggfunc={'amount':np.sum},margins=False)1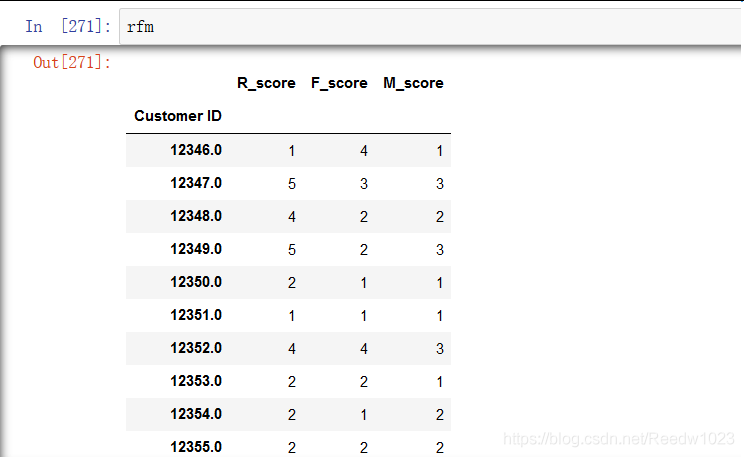
df2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd.pivot_table(df2,index=['year'],columns=['month'],values=['amount'],aggfunc={'amount':np.sum},margins=False)2查看describe() 按照平均值对客户进行价值分层
df2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd.pivot_table(df2,index=['year'],columns=['month'],values=['amount'],aggfunc={'amount':np.sum},margins=False)3这个转换是自定义的
高高高:近期消费过+消费频率高+消费金额高=重要价值
低高高:近期未消费+消费频率高+消费金额高=重要挽留
高低高:近期消费过+消费频率低+消费金额高=重要保持
高高低:近期消费过+消费频率高+消费金额低=一般保持
低低高:近期未消费+消费频率低+消费金额高=重要发展
低高低:近期未消费+消费频率高+消费金额低=一般挽留
高低低:近期消费过+消费频率低+消费金额低=一般发展
低低低:近期未消费+消费频率低+消费金额低=一般价值
df2 = df[(df['Quantity'] > 0) & (df['Price'] > 0)]
#使用透视图分析
pp = pd来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。




