

导读:本文整理自线上分享,首次披露Sugar BI的技术架构。
本次技术分享,将以 Sugar BI 为示例,分析背后的技术架构与流程,以及可视化图表的智能推荐策略等功能的设计思路,帮助大家深入理解智能化可视化 BI 的技术与实践。
本次内容主要分为以下 4 个部分:Sugar BI 产品的整体概况、可视化技术分析、智能图表推荐、智能语音交互。
全文5923字,预计阅读时间15分钟。
01 Sugar BI 介绍
1.1 百度智能云大数据体系产品架构全景
百度智能云大数据产品架构全景图共三层:
底层:通过湖仓数据基础设施(包括湖仓引擎和治理开发)为企业提供数据存储、数据处理、数据开发等能力。
中层:数据价值挖掘平台,充分利用百度智能大数据技术,实现企业数据资产价值最大化。
顶层:基于底层和中层的技术,帮助各行各业落地大数据应用落地。
除此之外,在架构图的右侧我们可以看到,百度智能云大数据体系建立了数据安全防护体系,如:多方安全计算、数据审计、加密脱敏等把控数据安全。
Sugar BI 作为数据价值挖掘平台之一,它是数据与用户最直接的一个连接。
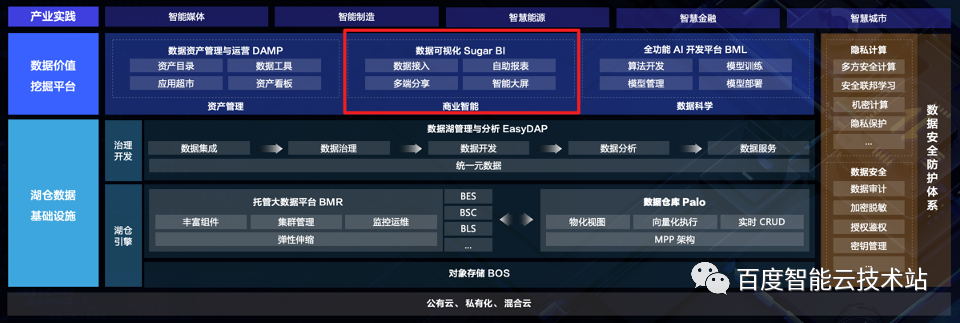
△图 1 百度大数据体系产品架构全景图
1.2 快速搭建专业化BI分析平台
设计目标:让用户在 5 分钟之内就能搭建专业的场景化的 BI 分析平台。
搭建流程:添加数据源 → 创建数据模型 → 可视化效果制作(包括报表制作&大屏制作)
这样简单的步骤让用户非常容易就能搭建一个可视化平台。在这个过程中利用了百度可视化开源组件 Apach Echarts ,通过拖拽图表组件及数据字段的方式,在 5 分钟之内就可以搭建数据可视化页面并进行复杂的数据分析操作。
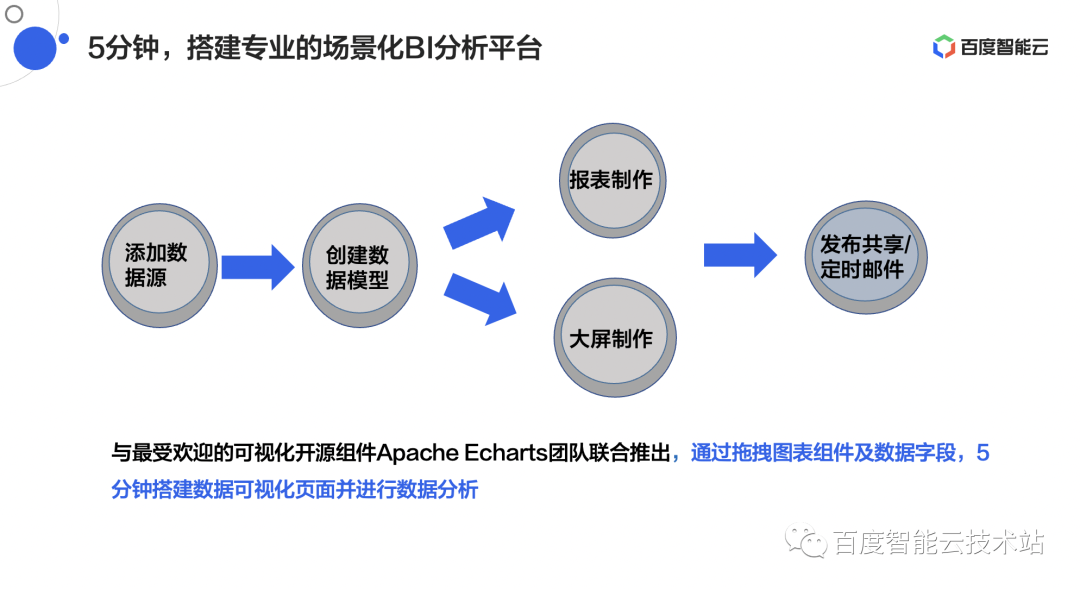
△图 2 Sugar BI 可视化页面搭建流程
1.3 对接多种数据源
在数据源层面,Sugar BI 可以对接的数据源包括:
开放性的数据库:MySQL、SQL Sever、 PostgreSQL、Oracle 等。
大数据的数据源:国产麒麟(Kylin)等。
其他场景中经常会用到的大数据的组件:Hive、Spark、Impala、Presto 等。Sugar BI还可以支持 Excel / CSV 数据的上传,同时还支持对接已有的 API 并且允许用户静态的输入 JSON 代码来做效果展示。
最后还开发了内网隧道的功能,可以让内网中数据源的数据通过内网隧道的方式直接对接到云上 Sugar BI 的产品中。
对于不同的数据源,比如 MySQL 和 SQL Server ,还支持两种数据源的跨源交叉分析。
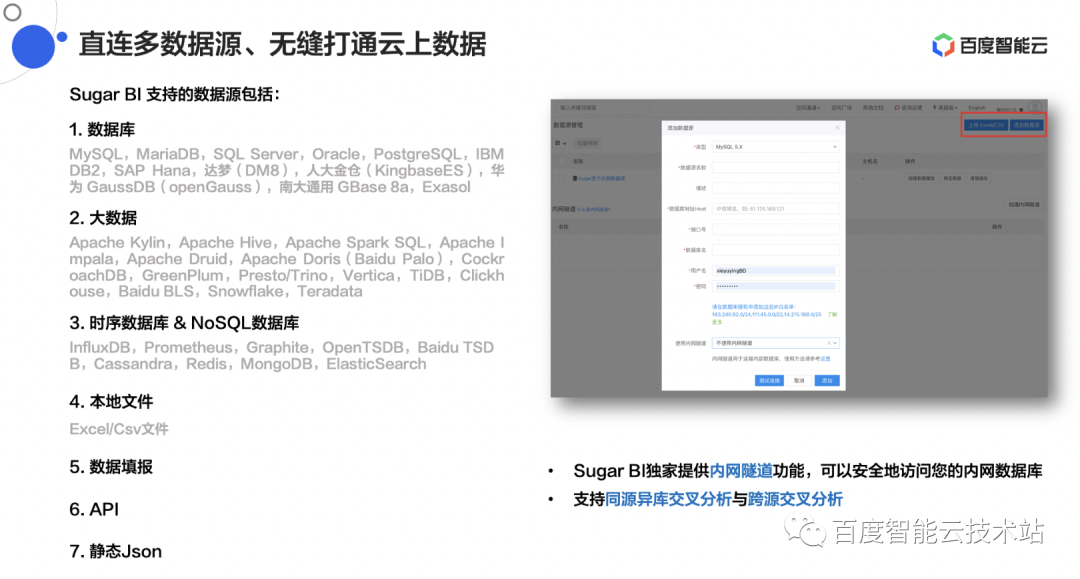
△图 3 Sugar BI 支持的数据源类型
1.4 零代码+拖拽式制作报表
在大屏页面中通过内置几十种大屏模板,Sugar BI 将百度内部专业的 UE / UI 设计资源赋能给客户,模板包括政务、教育、零售、金融、制造、新闻、餐饮等各行业。
整套设计涵盖移动端与 PC 端。客户只需简单修改,即可使用。
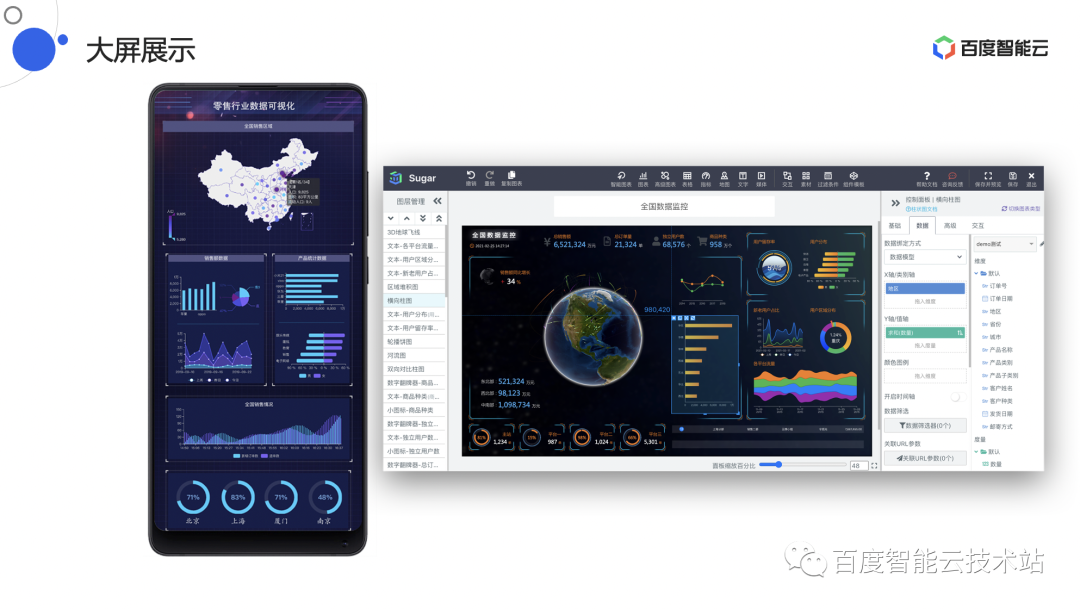
△图 4 Sugar BI 大屏展示
1.5 自动分析:你准备数据,我生成报表
在传统 BI 工具拖拽式生成报表的基础上,Sugar BI 进一步实现一键自动分析。系统在几秒钟内,就能将明细数据自动制作成交互式报表,真正做到解放用户双手。
用户只需提供一些维度和度量数据,Sugar BI 根据数据模型和维度、度量,就可以自动生成可视化页面。不仅页面中会自动生成图表,也会帮助用户自动添加一些过滤组件。用户可以根据自己需求,在自动生成的图表上做一些可视化的修改。
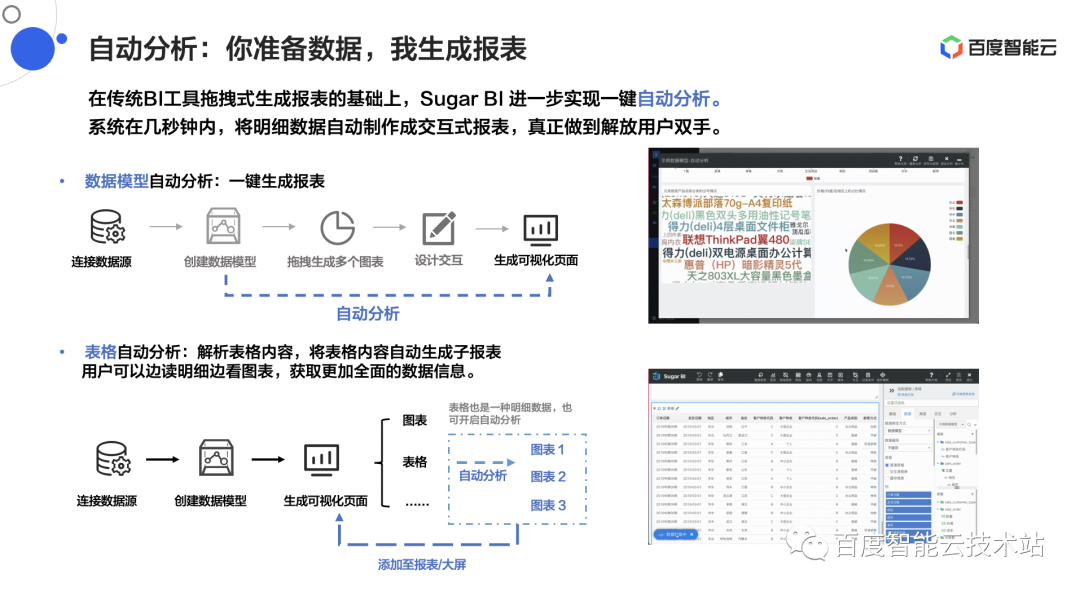
△图 5 Sugar BI 自动分析功能展示
02 可视化技术分析
2.1 Sugar BI 架构——有AI特色的可视化+BI分析平台
**Sugar BI 设计的定位是做一个有 AI 特色的可视化分析平台。**其中主要突出的三个特点分别是 AI、BI 和可视化。
Sugar BI 的整体架构图都是围绕"AI"、"BI"和"可视化"这三大特点来构建的,它将AI、BI、可视化这样的三个能力进行融合,最终使用容器化的技术进行打包和部署。
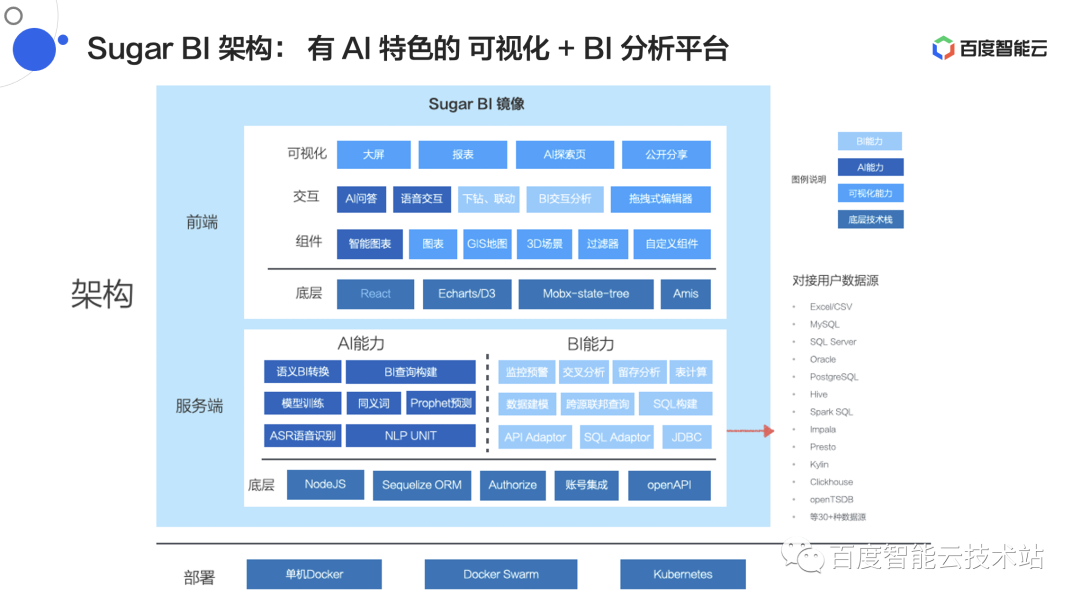
△图 6 Sugar BI 架构图
2.2 BI 能力:数据模型+灵活交互+数据计算
BI 能力方面,Sugar BI 支持对接丰富的数据源种类,包括 Excel、各种关系型数据库 MySQL、Oracle 等、以及大数据数仓 Doris、ClickHouse 等,一共超过 30 种数据源,目前在国内支持数据源类型最全。除此之外,Sugar BI 支持了达梦、人大金仓、南大通用、华为 GaussDB 等国产数据库。
数据模型:BI 能力的最底层是数据模型,在数据模型层面 Sugar BI 可以实现单表查询、多表 Join,支持数据库里面的视图,同样也支持用户去写自定义 SQL 视图。并且,用户在进行拖拽操作时,Sugar BI 能够对数据表里的字段自动进行维度、度量的划分。
BI 引擎:数据模型的上层是 BI 引擎。BI 引擎是在数据模型的基础上,以数据模型技术去解析用户的交互,从而进行过滤条件和数据筛选,最终生成能够在数据库上运行的查询语句,包括支持数据的筛选,下钻,联动,还可以支持和 URL 的参数来做联动。
计算引擎:包括表计算、交叉计算、数据格式化等,并且在数据层面也能做监控预警和留存分析这样一些比较深层次的计算。
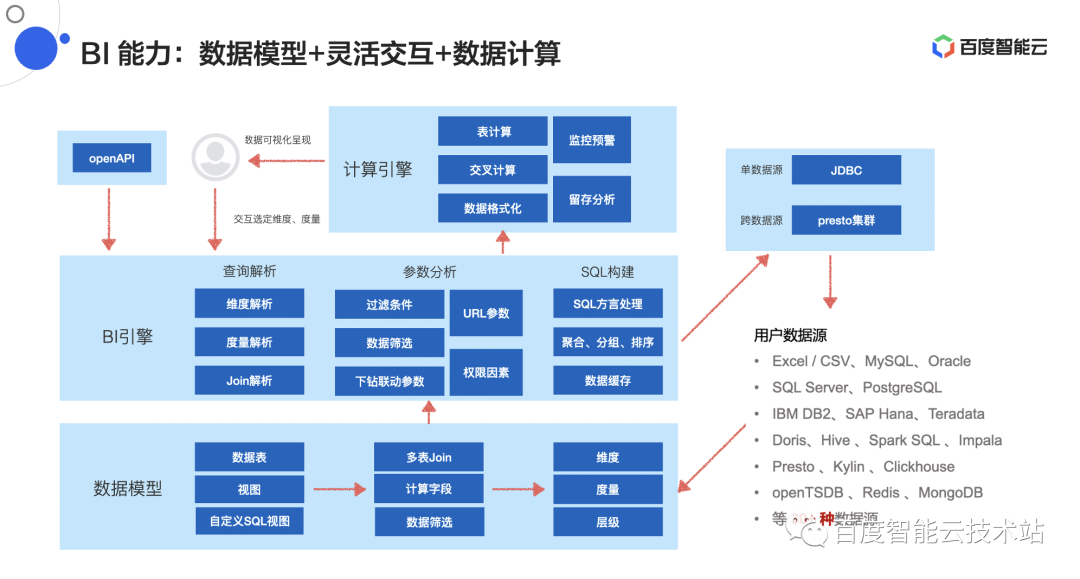
△图 7 Sugar BI “数据模型+灵活交互+数据计算”能力展示图
2.2.1 数据模型
市面上其他数据可视化的平台的缺点是需要用户去写 SQL 语句,然后将 SQL 语句查询的结果绑定到图表上。这对非技术的人员非常不友好,因为需要用户懂 SQL 语句的书写,而且在开发的过程中需要反复的修改 SQL 语句,这样会导致整体的开发效率比较低。
而在 Sugar BI 产品中,借鉴了 BI 的做法,将 BI 与可视化大屏的进行融合。除了写SQL 语句之外,用户也可以通过数据建模,将数据通过拖拽的方式绑定到可视化图表上,所以 Sugar BI 产品的定位就是一个产品满足两个产品的需求。
总结起来,Sugar BI 数据模型有以下的优势:
第一种是根据字段的数据类型,例如如果是字符串、日期会自动生成维度;如果是整数、小数等会自动生成度量。
第二种是根据字段名称、数据内容进行识别,类似 ID、type 类型、注释,从而在维度和度量的自动生成上做一个智能的区分,如果写的是省份 province / city,Sugar BI 会根据词性猜测字段为地理字段,不过用户也可以将维度和度量之间任意转换。

△图 8 Sugar BI 数据模型:零 SQL 代码,用户使用更简单
在 Sugar BI 中多表的 Join 使用的是雪花模型,可以自动的根据字段来选择 Join 的方式。使用最近共同祖先寻找法来解决查询的字段来自多个不同表的问题。
下面一共举了三个例子帮助大家共同去理解(参考图 9 左半部分):
因为 Field 3、Field 6 分别在 Table 2 和 Table 3 下面,所以我们需要查询 Table1 、Table 2、Table 3 的关联,才能把 Field 3、Field 6 同时查询出来。
因为 Field 3、Field 13 分别在 Table 2 和 Table 7 下面,所以我们只需要查询 Table1 、Table 2、Table 3、Table 7 即可。
因为Field 7、Field 13 分别在 Table 4 和 Table 7 下面,所以我们只需要查询 Table1 、Table 2、Table 4、Table 3、Table 7 即可。
以上过程总结为机器理解的方式——最近共同祖先寻找法。每一个在查的时候,他在往上寻找一个共同的祖先,就可以解决这个问题了。
正是因为有最近共同祖先寻找法,所以才能够确保 Sugar BI 的模型在根据用户拖拽字段的时候,他才能够找到到底要从雪花模型中 Join 哪几个表,然后通过设置的Join 关系能够自动的生成 SQL 语句。
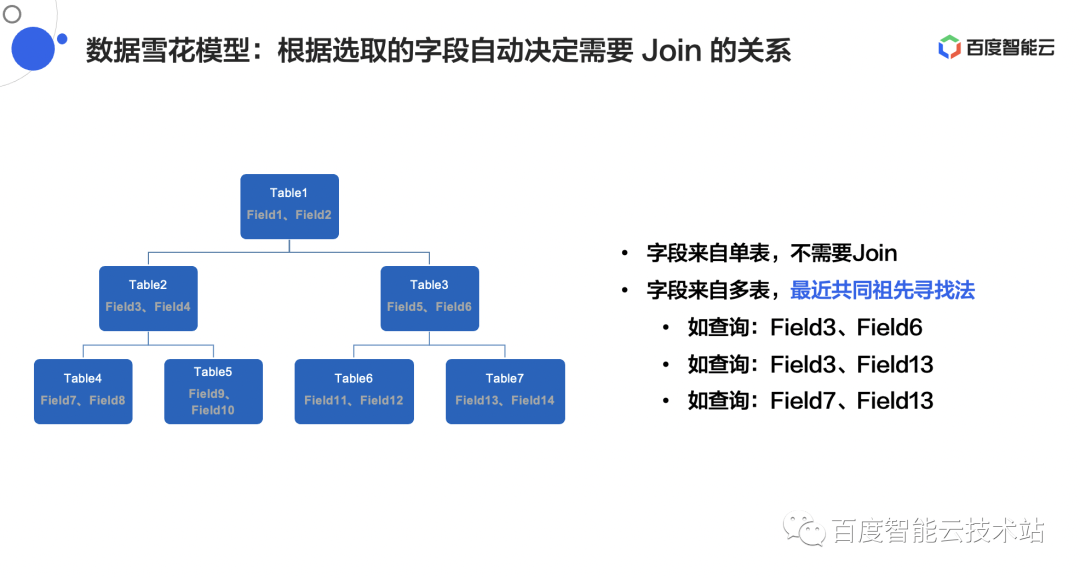
△图 9 Sugar BI 数据雪花模型图
2.2.2 灵活交互
在复杂场景下做 SQL 的 Where 筛选,就是要对数据进行过滤,对于右边非常复杂的 Where 筛选,Sugar BI 设计了左边的功能能够满足用户非常复杂的交互场景。

△图 10 Sugar BI 数据筛选示例图
Sugar BI 还支持聚合查询后的 Having 筛选,例如场景是查询年度总销售额大于 13 万的城市,对应到 SQL 语句的 Having 场景,是对数据聚合后再做一个筛选。
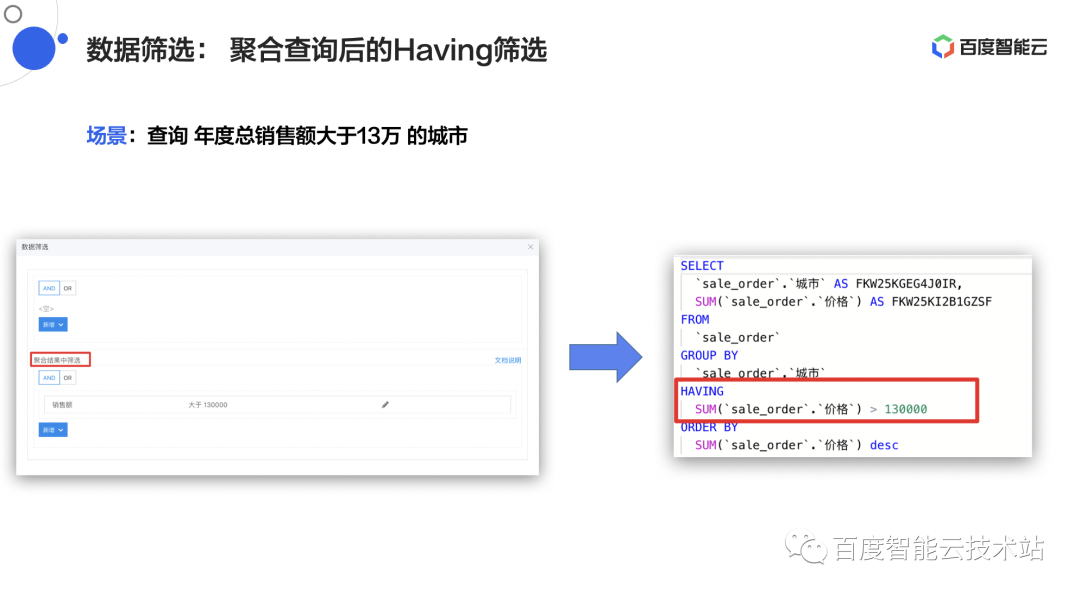
△图 11 Sugar BI 聚合查询后的 Having 筛选示例图
交互式的数据筛选其中分为页面整体的过滤组件和单个图表的过滤组件。

△图 12 Sugar BI 过滤组件:交互式的数据筛选示例图
除了数据的筛选和过滤组件的联动以外,Sugar BI 还有图表间的联动。例如:点击左侧地图,然后点击地图的某一个省份,想让右边的某一个组件展现省份的具体数据,这就是典型的图表联动效果。
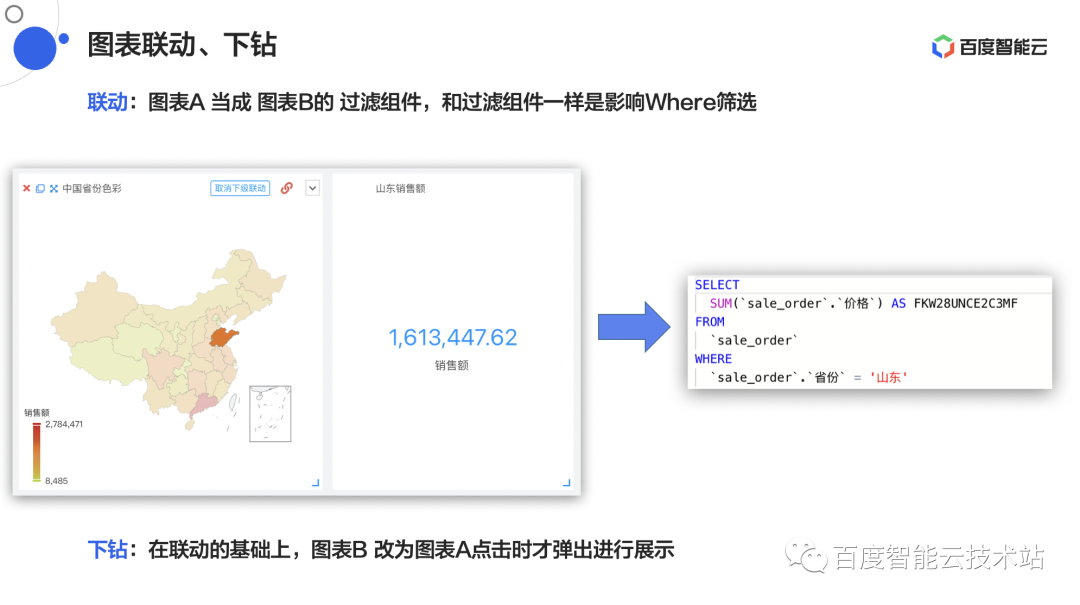
△图 13 Sugar BI 图表联动、下钻
2.2.3 SQL 查询层面的数据计算
特点:最终都转化为 SQL 语句,在数据库层面进行计算。具体可做的计算操作包括:
2.2.3.1 二次计算
二次计算是指在 SQL 查询结果后的再次计算,二次计算可以基于 SQL 查询结果,在内存中进行多线程计算。
该计算发生在内存中。具体包括:
在很多场景下,用户数据库里面存的是代码,但是用户希望可以将其展现为大多数人可以看懂的方式,这个时候就要用到数据值映射。Sugar BI 支持用户配置一对一的映射,数据值映射将这些不友好的值映射为可以展示给用户的可阅读性强的值。
2.2.3.2 性能优化
Sugar BI 在性能优化方面做了如下尝试:
03 智能图表推荐
3.1 智能图表目的
**智能图表作为智能语音交互的基础,可以根据数据的维度和字段,自动为用户推荐最合适的图表类型。**同时,也支持用户根据需求自主切换图表类型。
3.2 智能图表推荐流程
智能图表首先是对系统内部 100 多种的图表进行抽象百度数据分析,从图表中提取特征,例如根据折线图的属性,X 轴、Y 轴至少需要绑定一个字段。并且,用户在拖入字段的时候,Sugar BI 可以根据数据度量、维度、地理字段等抽象为一个数据特征。
然后在图表推荐模块将图表的特征与当前用户输入的特征做一个匹配,之后推荐的图表有一个列表百度数据分析,并对列表中对每一个图表进行打分,最后进行排名将得分最高的
来源【首席数据官】,更多内容/合作请关注「辉声辉语」公众号,送10G营销资料!
版权声明:本文内容来源互联网整理,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 jkhui22@126.com举报,一经查实,本站将立刻删除。





